大数据平台搭建 - cdh5.11.1 - spark源码编译及集群搭建
一、spark简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,Spark 是一种与 hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
二、spark编译
为什么cdh提供了spark已经编译好的包,还要自己手工编译?因为从spark某个版本之后,就不再集成hadoop相关的jar包了,这些jar包需要自己来指定路径,并且除了hadoop的jar包外,还有FastJson,Hbase等许许多多jar包需要自己指定,很麻烦,所以再三考量,决定还是自己手工编译spark。
1.安装scala 2.10.4
这个从scala官网上下载压缩包到linux,解压缩,配置好环境变量,即可,非常easy
2.下载spark1.6.0-cdh5.11.1源码包
http://archive.cloudera.com/cdh5/cdh/5/
同样是从这个网站下载源码包
解压
配置make-distribute.sh文件,修改:
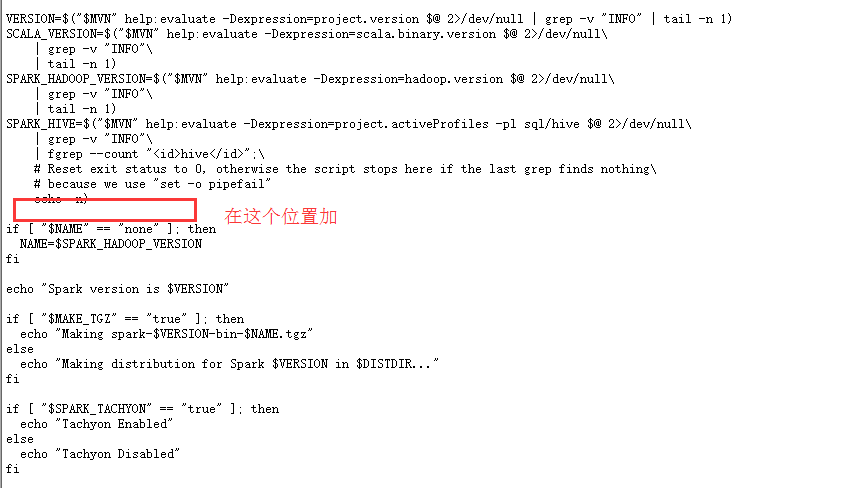
把脚本里的VERSION,SCALA_VERSION,SPARK_HADOOP_VERSION,SPARK_HIVE四个参数的定义注释掉,因为这会花费大量的时间来获取到,并且添加下面的内容:
3.修改pom.xml文件

修改一下最前面定义的scala.version的版本号,改成2.10.4
4.上传必要的编译的东西到build目录下
一是scala解压缩之后的包,zinc解压缩后的包
zinc可在这个地址下下载:
http://downloads.typesafe.com/zinc/0.3.5.3/zinc-0.3.5.3.tgz
结果如下:

5.修改maven配置文件的settings.xml,加入阿里云的镜像
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
6.开始编译
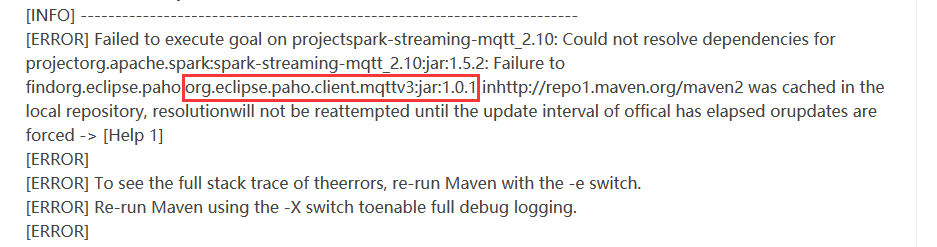
说是找不到这个包,于是去maven仓库中手动下载所有的文件,复制到本地的仓库,即可:
1.把这个文件夹下的内容都下载到本地
https://repo.eclipse.org/content/repositories/paho-releases/org/eclipse/paho/org.eclipse.paho.client.mqttv3/1.0.1/
之后,在本地maven仓库中,建立org/eclipse/paho/org.eclipse.paho.client.mqttv3/1.0.1/这个目录,把文件拷贝到这个目录下
2.把这个文件夹下的内容下载到本地
https://repo.eclipse.org/content/repositories/paho-releases/org/eclipse/paho/java-parent/1.0.1/
同样在本地建立org/eclipse/paho/java-parent/1.0.1/文件夹,把下载的东西复制到这即可
重新编译
8.漫长的等待,因为需要下载许多的jar包,务必这次编译成功后,把maven库打包备份一份,下次使用
9.之后,在本地可以看到一个编译好的tar包,这个就是spark的安装包
三.spark集群环境搭建
解压缩spark包,配置conf
重命名spark-env.sh.template为spark-env.sh,加入以下配置
JAVA_HOME=/home/hadoop/app/jdk
SCALA_HOME=/home/hadoop/app/scala
HADOOP_CONF_DIR=/home/hadoop/app/hadoop/etc/hadoop
HADOOP_HOME=/home/hadoop/app/hadoop
## 这里不同的机器不同的配置
SPARK_LOCAL_IP=hadoop001
SPARK_MASTER_IP=hadoop001
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
注意,SPARK_LOCAL_IP是本地的地址,不同的机器,这个配置需要改正哦
修改slaves
这里放入所有的worker节点
hadoop002
hadoop003
即可
先启动本地
bin/spark-shell
如果没有问题,那么可以启动集群了
sbin/start-all.sh
进入hadoop001:7077访问,即可看到spark的监控界面
大数据平台搭建 - cdh5.11.1 - spark源码编译及集群搭建的更多相关文章
- 基于.NetCore的Redis5.0.3(最新版)快速入门、源码解析、集群搭建与SDK使用【原创】
1.[基础]redis能带给我们什么福利 Redis(Remote Dictionary Server)官网:https://redis.io/ Redis命令:https://redis.io/co ...
- Spark源码编译
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3822995.html spark源码编译步骤如下: cd /home/hdpusr/workspace ...
- Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行. 环境准备: 1,Maven环境搭建,版本Apache Maven 3 ...
- Mosquitto搭建Android推送服务(三)Mosquitto集群搭建
文章钢要: 1.进行双服务器搭建 2.进行多服务器搭建 一.Mosquitto的分布式集群部署 如果需要做并发量很大的时候就需要考虑做集群处理,但是我在查找资料的时候发现并不多,所以整理了一下,搭建简 ...
- Spark源码编译(未完待续)
在这里我们不需要搭建独立的Spark集群,利用Yarn Client调用Hadoop集群的计算资源. Spark源码编译生成配置包: 解压源码,在根去根目录下执行以下命令(sbt编译我没尝试) ./m ...
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- spark源码编译记录
spark在项目中已经用了一段时间了,趁现在空闲,下个源码编译在IDEA里面阅读下,特此记录过程. 前提已经安装maven和git 1.上官网下载源码的包: 2.然后解压到一个文件夹 3.编译,编译的 ...
- 大数据平台CentOS7+CDH5.12.1集群搭建
1.CM(Cloudera Manager)介绍 1.1 简介 Cloudera Manager是一个拥有集群自动化安装.中心化管理.集群监控.报警功能的一个工具,使得安装集群从几天的时间缩短在几个小 ...
随机推荐
- ABP 配置全局数据过滤器 II
第一篇 那种写法有些复杂, 简单办法是直接注入 切换到 ***.EntityFramework 项目 在Uow 里面创建 ***EfUnitOfWork.cs 类 public class Coope ...
- Javarscipt中数组或者字符串的随机排序方法
在日常开发中,经常会遇到随机排序的需求,思路就是利用Math.random()方法,抽取随机数,让数组中的元素进行对调: 话不多说直接上代码,方法一:基本思路就是将a中随机抽取一个元素,放入b中,再从 ...
- linux 目录大小 文件个数 基于文件大小排列显示
显示硬盘占用空间du -hlsblk 查看指定目录大小du -sh /opt查看各个目录大小du -h --max-depth=1 当前目录的全部文件个数(包含子文件夹的文件)ls -lR | gre ...
- HuffmanTree
/* 例如,对于数列{pi}={5, 3, 8, 2, 9},Huffman树的构造过程如下: 1. 找到{5, 3, 8, 2, 9}中最小的两个数,分别是2和3,从{pi}中删除它们并将和5加入, ...
- SpringBoot项目中如何异步执行一个方法
1. SpringBoot上加上开启异步方法注解:@EnableAsync 2. 在需要异步执行的方法上,加上异步方法注解 @Async 3. 测试 5. 测试结果为,访问127.0.0.1:8888 ...
- Codeforces 936B
题意略. 思路: 图论里掺杂了一些动态规划. 有几个注意点: 1.dp时状态的设计:因为我们要寻求的是出度为0并且可以从起点走奇数步抵达的点,由于同一个点可以通过多种方式到达. 并且我们在获得奇数步点 ...
- HDU 6315
题意略. 思路:本题的思路总的来说就是暴力 + 剪枝. 我们依然用线段树来维护: 定义结点node{ l , r , minn , contirbute} 分别为某个区间的左右端点,和该区间(b序列) ...
- 前端测试工具之 postman
1.不论你是一个前端工程师还是一个后端工程师相信这款工具都会使你的开发更加简便. 2.在此我推荐的一款软件工具是 postman . 在这里我对 postman 做一个简单的介绍: ①它能够模拟表单发 ...
- python小白短期基础入门
一.编程语言介绍与分类 1.什么是编程语言 编程语言本质就是人类的语言,主要用于沟通交流.我们通过编程语言与计算机进行互动交流,从而使计算机来帮助我们实现一些特定的功能和一些复杂的工作. 2.编程语言 ...
- Agentless监控实践中的预警指标采集
很多公司已经开发了监控解决方案,解决了指标收集.展示.预警发送等一系列问题. 本文介绍的监控解决方案由高性能时序数据库InfluxDB.时序分析监控工具Grafana及Agentless自动化工具An ...