大数据平台搭建 - cdh5.11.1 - spark源码编译及集群搭建
一、spark简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,Spark 是一种与 hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
二、spark编译
为什么cdh提供了spark已经编译好的包,还要自己手工编译?因为从spark某个版本之后,就不再集成hadoop相关的jar包了,这些jar包需要自己来指定路径,并且除了hadoop的jar包外,还有FastJson,Hbase等许许多多jar包需要自己指定,很麻烦,所以再三考量,决定还是自己手工编译spark。
1.安装scala 2.10.4
这个从scala官网上下载压缩包到linux,解压缩,配置好环境变量,即可,非常easy
2.下载spark1.6.0-cdh5.11.1源码包
http://archive.cloudera.com/cdh5/cdh/5/
同样是从这个网站下载源码包
解压
配置make-distribute.sh文件,修改:
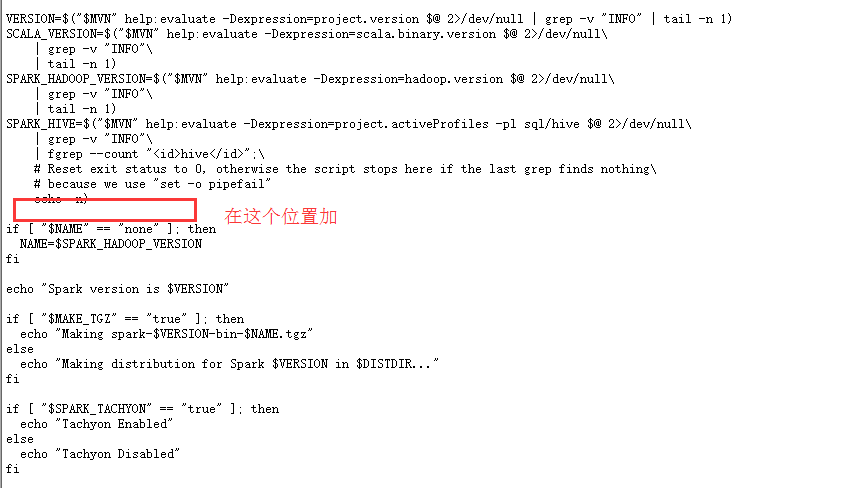
把脚本里的VERSION,SCALA_VERSION,SPARK_HADOOP_VERSION,SPARK_HIVE四个参数的定义注释掉,因为这会花费大量的时间来获取到,并且添加下面的内容:
3.修改pom.xml文件

修改一下最前面定义的scala.version的版本号,改成2.10.4
4.上传必要的编译的东西到build目录下
一是scala解压缩之后的包,zinc解压缩后的包
zinc可在这个地址下下载:
http://downloads.typesafe.com/zinc/0.3.5.3/zinc-0.3.5.3.tgz
结果如下:

5.修改maven配置文件的settings.xml,加入阿里云的镜像
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
6.开始编译
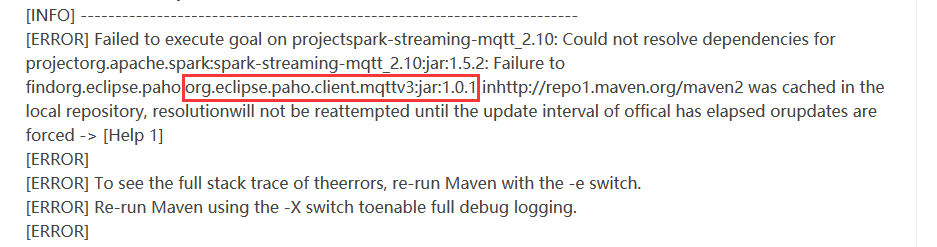
说是找不到这个包,于是去maven仓库中手动下载所有的文件,复制到本地的仓库,即可:
1.把这个文件夹下的内容都下载到本地
https://repo.eclipse.org/content/repositories/paho-releases/org/eclipse/paho/org.eclipse.paho.client.mqttv3/1.0.1/
之后,在本地maven仓库中,建立org/eclipse/paho/org.eclipse.paho.client.mqttv3/1.0.1/这个目录,把文件拷贝到这个目录下
2.把这个文件夹下的内容下载到本地
https://repo.eclipse.org/content/repositories/paho-releases/org/eclipse/paho/java-parent/1.0.1/
同样在本地建立org/eclipse/paho/java-parent/1.0.1/文件夹,把下载的东西复制到这即可
重新编译
8.漫长的等待,因为需要下载许多的jar包,务必这次编译成功后,把maven库打包备份一份,下次使用
9.之后,在本地可以看到一个编译好的tar包,这个就是spark的安装包
三.spark集群环境搭建
解压缩spark包,配置conf
重命名spark-env.sh.template为spark-env.sh,加入以下配置
JAVA_HOME=/home/hadoop/app/jdk
SCALA_HOME=/home/hadoop/app/scala
HADOOP_CONF_DIR=/home/hadoop/app/hadoop/etc/hadoop
HADOOP_HOME=/home/hadoop/app/hadoop
## 这里不同的机器不同的配置
SPARK_LOCAL_IP=hadoop001
SPARK_MASTER_IP=hadoop001
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
注意,SPARK_LOCAL_IP是本地的地址,不同的机器,这个配置需要改正哦
修改slaves
这里放入所有的worker节点
hadoop002
hadoop003
即可
先启动本地
bin/spark-shell
如果没有问题,那么可以启动集群了
sbin/start-all.sh
进入hadoop001:7077访问,即可看到spark的监控界面
大数据平台搭建 - cdh5.11.1 - spark源码编译及集群搭建的更多相关文章
- 基于.NetCore的Redis5.0.3(最新版)快速入门、源码解析、集群搭建与SDK使用【原创】
1.[基础]redis能带给我们什么福利 Redis(Remote Dictionary Server)官网:https://redis.io/ Redis命令:https://redis.io/co ...
- Spark源码编译
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3822995.html spark源码编译步骤如下: cd /home/hdpusr/workspace ...
- Spark环境搭建(六)-----------sprk源码编译
想要搭建自己的Hadoop和spark集群,尤其是在生产环境中,下载官网提供的安装包远远不够的,必须要自己源码编译spark才行. 环境准备: 1,Maven环境搭建,版本Apache Maven 3 ...
- Mosquitto搭建Android推送服务(三)Mosquitto集群搭建
文章钢要: 1.进行双服务器搭建 2.进行多服务器搭建 一.Mosquitto的分布式集群部署 如果需要做并发量很大的时候就需要考虑做集群处理,但是我在查找资料的时候发现并不多,所以整理了一下,搭建简 ...
- Spark源码编译(未完待续)
在这里我们不需要搭建独立的Spark集群,利用Yarn Client调用Hadoop集群的计算资源. Spark源码编译生成配置包: 解压源码,在根去根目录下执行以下命令(sbt编译我没尝试) ./m ...
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- spark源码编译记录
spark在项目中已经用了一段时间了,趁现在空闲,下个源码编译在IDEA里面阅读下,特此记录过程. 前提已经安装maven和git 1.上官网下载源码的包: 2.然后解压到一个文件夹 3.编译,编译的 ...
- 大数据平台CentOS7+CDH5.12.1集群搭建
1.CM(Cloudera Manager)介绍 1.1 简介 Cloudera Manager是一个拥有集群自动化安装.中心化管理.集群监控.报警功能的一个工具,使得安装集群从几天的时间缩短在几个小 ...
随机推荐
- JVM 栈帧之操作数栈与局部变量表
目录 前置知识 引子 基于寄存器的设计模式 基于栈的设计模式 一个简单的例子 如何查看局部变量表? 实例方法中的局部变量表 结论 前置知识 阅读本文需要对以下知识有所了解: * 栈 * 汇编 * Ja ...
- jmeter之beanshell使用
beanshell官网:http://www.BeanShell.org/ 一.beanshell介绍 是一种完全符合Java语法规范的轻量级的脚本语言: 相当于一个小巧免费嵌入式的Java源代码解释 ...
- .NET使用Bogus生成大量随机数据
.NET如何生成大量随机数据 在演示Demo.数据库脱敏.性能测试中,有时需要生成大量随机数据.Bogus就是.NET中优秀的高性能.合理.支持多语言的随机数据生成库. Bogus的Github链接: ...
- python paramiko外部传参和内部调用命令的方法
学习了很久的python,但在工作中使用的时候,却发现不知道怎么传参进入到python中执行,所以这两天就研究 了python args怎么将外部参数传入到python中执行 1.首先使用python ...
- 10.源码分析---SOFARPC内置链路追踪SOFATRACER是怎么做的?
SOFARPC源码解析系列: 1. 源码分析---SOFARPC可扩展的机制SPI 2. 源码分析---SOFARPC客户端服务引用 3. 源码分析---SOFARPC客户端服务调用 4. 源码分析- ...
- CSS布局:元素水平垂直居中
CSS布局:元素水平垂直居中 本文将依次介绍在不同条件下实现水平垂直居中的多种方法 水平垂直居中是在写网页时经常会用到的需求,在上两篇博客中,分别介绍了水平居中和垂直居中的方法.本文的水平垂直居中就是 ...
- ssh通过pem文件登陆服务器
一些为了安全操作,推荐使用私钥进行登录服务器,拿jenkins来说,默认的验证方式就是私钥 实现方式 先在本机通过ssh-keygen直接生成公私钥 如下在当前文件夹下生成my.pem(私钥)和my. ...
- getline()与get()(c++学习笔记)
istream中的类(如cin)提供了一些面向行的类成员函数:getline()和get() 1.getline()函数 读取整行,使用回车键输入的换行符来确定输入结尾. 调用方法:cin.getli ...
- UVA 10395 素数筛
Twin Primes Twin primes are pairs of primes of the form (p; p + 2). The term \twin prime" was c ...
- 设计模式(C#)——01单例模式
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 为什么要学习设计模式呢?我以前也思考过很多次这个问题,现在也还困惑.为什么我最后还是选择了学设计模式呢?因为在游戏中 ...