Spark流式编程介绍 - 编程模型
来源Spark官方文档
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#programming-model
编程模型
结构化流中的核心概念就是将活动数据流当作一个会不断增长的表。这是一个新的流处理模型,但是与批处理模型很相似。你在做流式计算就像是标准针对静态表的批查询,Spark会在一个无限输入的表上进行增量查询。我们来从更多详细内容来理解这个模型。
基本概念
将输入的数据流理解为“写入表”,每个流中到达的数据就像是写入表中新增的一行。
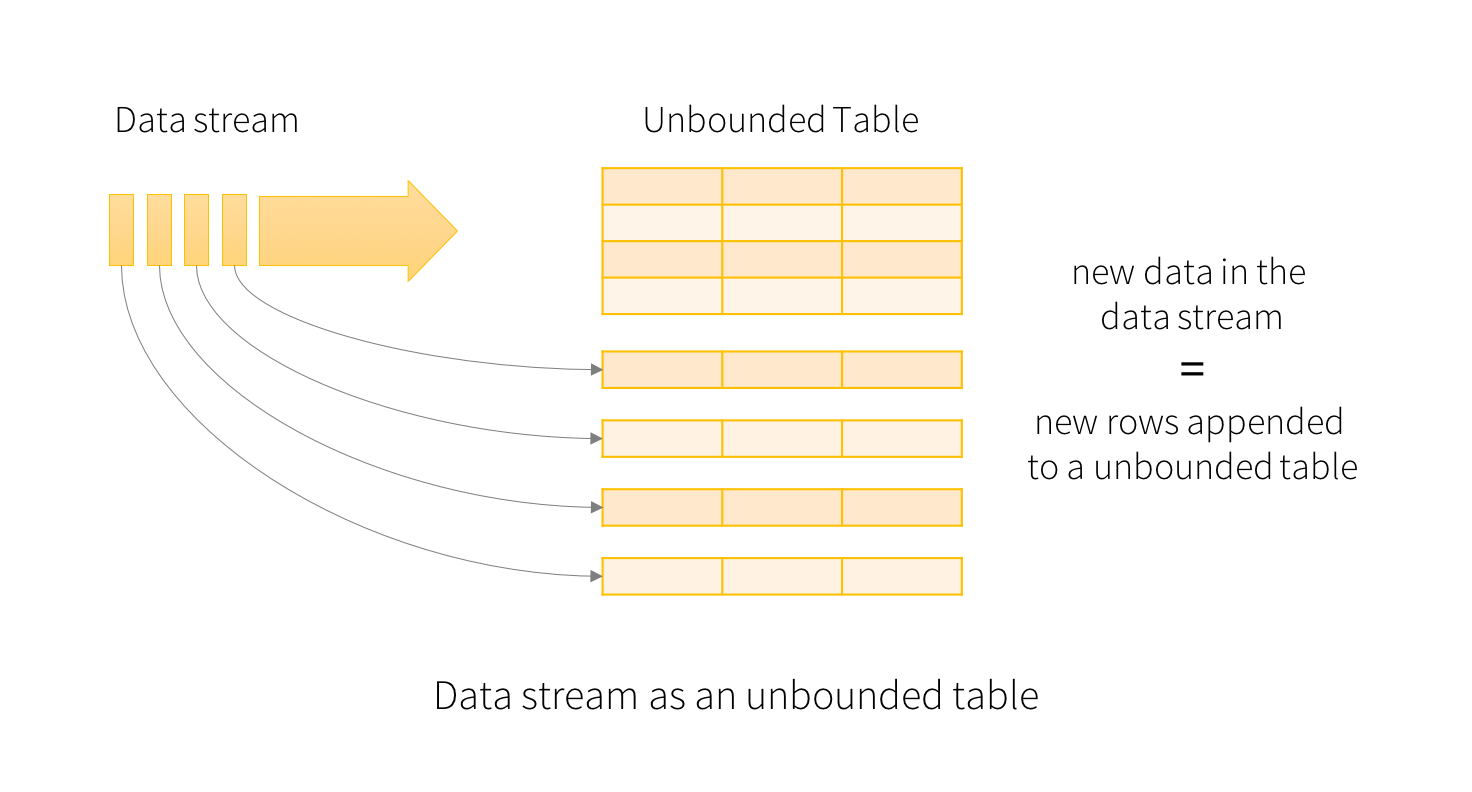
针对输入的查询会生成“结果表”。每个触发间隔之间(比如1秒钟),就会有新的行添加到“写入表”,最终更新结果表。当结果表变更后,我们能够将变更的结果行写入外部存储。
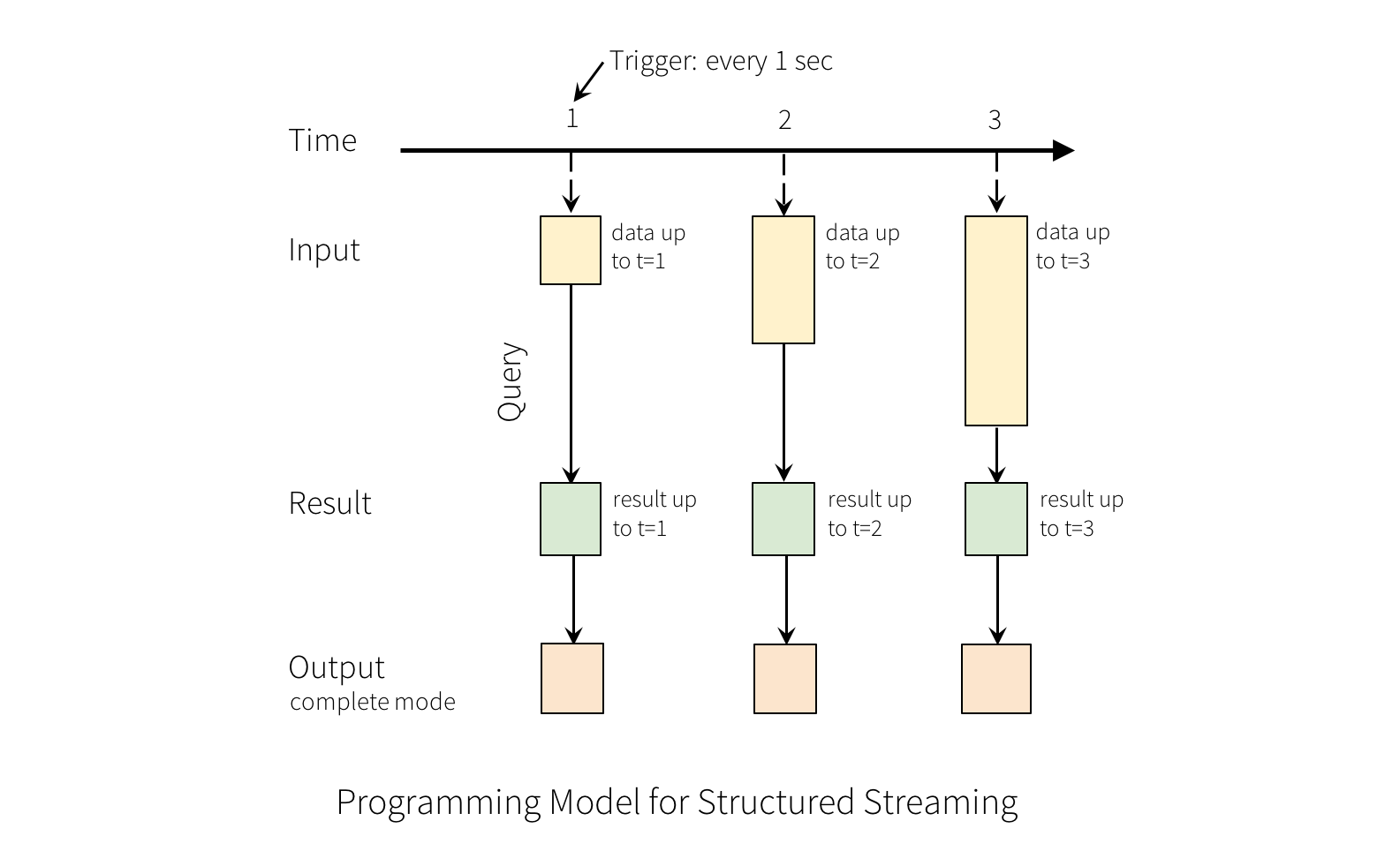
“输出(Output)”定义为写入外部存储的内容。输出存在几种模式:
- 完全模式(Complete Mode) :整个更新后的结果表会全部写入外部存储。具体的全表写入方式取决于与存储的底层连接。
- 增量模式(Append Mode) :从上次触发后的新增结果表数据才会写入外部存储。这个模式只适用于那些预期结果表中的存量数据不会变化的查询。
- 更新模式(Update Mode) : 从上次触发后的更新结果表数据才会写入外部存储(从Spark 2.1.1开始生效)。注意本模式和完全模式的差异,本模式下只会输出上次触发后的变更行。如果查询不包含聚合,基本会和增量模式相同。
要注意每个模式都有确定的适配的查询,这个会在稍后讨论。
为了解释这个模型的使用方式,我们用上面的快速示例来辅助理解模型。第一个DataFrame类型的变量 line 就是写入表,而最后DataFrame类型的变量 wordCounts 就是结果表。注意针对流的查询方法,从 line 生成 wordCounts 和一个静态的DataFrame完全相同。当查询开始之后,Spark会持续检查从socket链接传入的新数据。如果存在新数据,Spark会运行“增量”查询,并且针对新数据计算更新的计数,整合之前运行的计数,如下图所示。
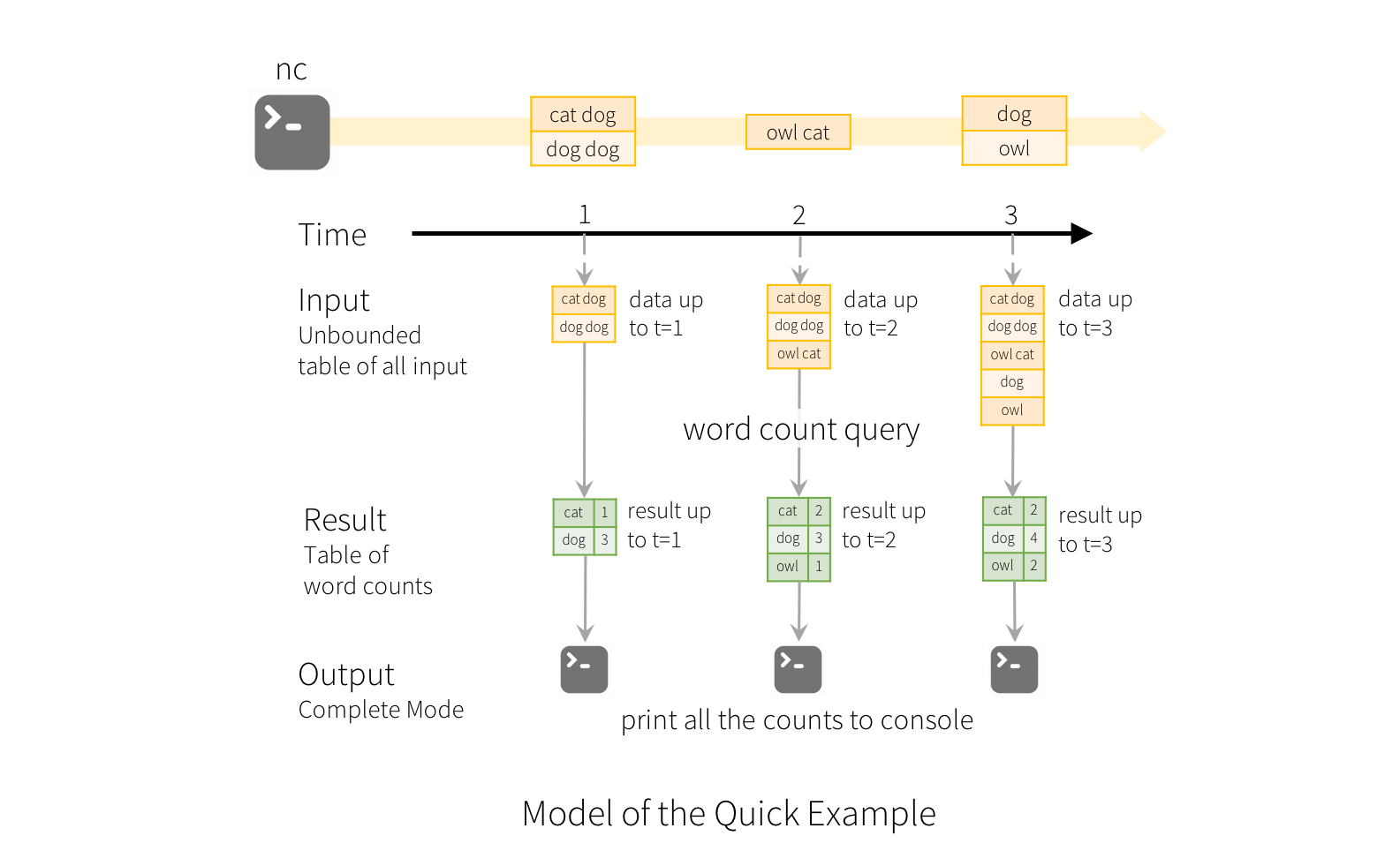
注意结构化流并没有存储整张表。从数据源读取最近有效的数据,增量的处理并且更新结果数据,然后丢弃源数据。Spark只保留最小中间状态数据,用于更新结果(例如上面例子中的中间统计结果计数)。
这个模型明显和其他的流处理引擎不同。许多流处理系统要求用户自行维护运行聚合,因为有诸如容错性(fault-tolerance)、数据一致性(data consistency:at-least-once, at-most-once, exactly-once)。在这个模型中,当有新数据时,由Spark负责更新结果表,因此解放了用户无需关注。我们以模型处理事件时间和延迟数据作为例子来看下。
处理事件时间和延迟数据
事件时间是包含在数据本身的。很多应用都希望基于事件时间操作。例如你的想要获取物联网设备每分钟产生事件数量,然后你可能希望使用数据生成的时间(这就是事件时间),而不是Spark接收到他们的时间。事件时间在这个模型中是很自然的,因为每个设备产生事件都是都是表中的一行数据,而事件时间就是一行数据中的一列。这样基于窗口的聚合(例如每分钟的事件数量)可以作为基于事件时间列做的特别的分组和聚合。每个时间窗口都是一个分组,每行数据也可以属于多个窗口或分组。因此类似这种基于事件时间的聚合查询能够在静态数据集(例如收集的设备事件日志)和动态数据流,能够是用户的使用比较简单。
此外模型天然的能够基于事件时间处理延迟到达的数据。当Spark更新结果表时,他仍然能够针对延迟数据来更新历史聚合的结果,也同时可以清除历史聚合数据,从而限制中间状态数据的大小。从Spark2.1开始,我们支持水位线概念(watermarking),允许用户指定延迟数据的阈值,系统也能够清理旧状态数据。稍后会在窗口操作章节介绍。
容错性
保证唯一投送端到端是结构化流的设计中的关键目标之一。为了达成这样的目标,我们设计了结构化流的源(Source)、汇(Sink)以及执行引擎能够可靠的跟踪处理进度,从而能够重启/重新处理来应对各种故障。每个数据流的源应该都有偏移量概念(类似Kafka的偏移量,或者Amazon Kinesis 的序列编号)来跟踪流中的读取位置。引擎使用保存点和先写日志来记录每次处理的数据偏移边界。流的汇设计天然就支持重新处理的幂等性。整合起来,使用可重放的源与幂等的汇,结构化流在面对任何故障时都能保证端对端严格一致性(end-to-end exactly-once semantics)。
Spark流式编程介绍 - 编程模型的更多相关文章
- Storm简介——实时流式计算介绍
概念 实时流式计算: 大数据环境下,流式数据将作为一种新型的数据类型,这种数据具有连续性.无限性和瞬时性.是实时数据处理所面向的数据类型,对这种流式数据的实时计算就是实时流式计算. 特征 实时流式计算 ...
- 实时查询系统架构:spark流式处理+HBase+solr/ES查询
最近要做一个实时查询系统,初步协商后系统的框架 1.流式计算:数据都给spark 计算后放回HBase 2.查询:查询采用HBase+Solr/ES
- Spark流式状态管理(updateStateByKey、mapWithState等)
通常使用Spark的流式框架如Spark Streaming,做无状态的流式计算是非常方便的,仅需处理每个批次时间间隔内的数据即可,不需要关注之前的数据,这是建立在业务需求对批次之间的数据没有联系的基 ...
- 流式 storm介绍
Storm是什么 如果只用一句话来描述storm的话,可能会是这样:分布式实时计算系统.按照storm作者的说法,storm对于实时计算的意义类似于hadoop对于批处理的意义.我们都知道,根据goo ...
- Stream流式编程
Stream流式编程 Stream流 说到Stream便容易想到I/O Stream,而实际上,谁规定“流”就一定是“IO流”呢?在Java 8中,得益于Lambda所带来的函数式编程,引入了一个 ...
- Paip.Php Java 异步编程。推模型与拉模型。响应式(Reactive)”编程FutureData总结... 1
Paip.Php Java 异步编程.推模型与拉模型.响应式(Reactive)"编程FutureData总结... 1.1.1 异步调用的实现以及角色(:调用者 提货单) F ...
- 20190827 On Java8 第十四章 流式编程
第十四章 流式编程 流的一个核心好处是,它使得程序更加短小并且更易理解.当 Lambda 表达式和方法引用(method references)和流一起使用的时候会让人感觉自成一体.流使得 Java ...
- GPU编程和流式多处理器(四)
GPU编程和流式多处理器(四) 3.2. 单精度(32位) 单精度浮点支持是GPU计算的主力军.GPU已经过优化,可以在此数据类型上原生提供高性能,不仅适用于核心标准IEEE操作(例如加法和乘法),还 ...
- GPU编程和流式多处理器(三)
GPU编程和流式多处理器(三) 3. Floating-Point Support 快速的本机浮点硬件是GPU的存在理由,并且在许多方面,它们在浮点实现方面都等于或优于CPU.全速支持异常可以根据每条 ...
随机推荐
- Windows下ElasticSearch的Head安装及基本使用
前段时间,有一朋友咨询我,说es的head插件一直安装失败,为了给朋友解惑,自己百度博文并实践了一番,也的确踩了些坑,但我给爬了起来.今天就来分享下实践心得并跳过的坑. ElasticSearch 是 ...
- php if语句
一.前言 if语句 是几乎所有编程语言都有的函数. 当然我们最好的php这么最好的语言也有啦~ 二.搞起! 直接上代码不多哔哔.talk is cheap show me the code 2.1 i ...
- OWASP 关于会话管理 - 译文 [原创]
英文原文:https://github.com/OWASP/CheatSheetSeries/blob/master/cheatsheets/Session_Management_Cheat_Shee ...
- C语言入门9-1-分类函数
分类函数 ASCII字符可以分为英文字母.数字.控制字符.空白字符.大小写字母以及标点符号,分类是指对字符进行属性判定,判断字符属于哪些范畴,这些属性的判定在程序中非常常见,尤其是通信协议的字符处理部 ...
- html+css test1
模拟实验楼提供的一个网页.. [可由 git clone https://github.com/shiyanlou/finaltest 获取相关图片素材] <!DOCTYPE html>& ...
- [03] HEVD 内核漏洞之UAF
作者:huity出处:https://www.cnblogs.com/huity35/p/11240997.html版权:本文版权归作者所有.文章在博客园.个人博客同时发布.转载:欢迎转载,但未经作者 ...
- 分享一个 Linux 环境下,强力的Python 小工具
场景 Linux 用户,经常需要在终端查看一些数据,从文件里看 或者网络协议获取数据并查看. 比如,查看文件里的json数据:比如,查看etcd里存下的数据. 如果直接看cat 或者 curl 得到的 ...
- web设计_1_思路总览
核心思想:结构和样式分离 HTML与CSS 只有充分将页面核心内容和外观设计相分离而获得的灵活性,才能顺利构建出能够满足每个web用户需要的最佳设计方案. 核心要求:灵活性 适应不同的浏览器,适应各种 ...
- string的学习
原:https://blog.csdn.net/qq_37941471/article/details/82107077 一. string的构造函数的形式: string str:生成空字符串 st ...
- Angular JS 中的内置方法之表单验证
angular js 结合html5 可以实现强大的表单验证功能 关闭html5自带的表单验证功能可以用