elk 7.2
Elasticsearch
7.0开始内置了Java环境
1、jvm.options配置建议
- Xmx和Xms设置成一样
- Xmx不要超过机器内存的50%
- 不要超过30GB
https://www.elastic.co/cn/blog/a-heap-of-trouble
2、元数据,用于标注文档的相关信息
- _index: 文档所属的索引名
- _type: 文档所属的类型名
- _id: 文档的唯一ID
- _source: 文档的原始json数据
- _all: 整合所有字段内容到该字段,已被废除
- _version: 文档的版本信息
- _score: 相关性打分
3、节点介绍,
- master节点
每个节点启动后,默认就是一个master eligible节点,设置nod.master:false禁止。
只有master节点才能修改集群的状态信息。
- Data节点
可以保持数据的节点,叫做data node。负责保持分片数据。
- Coordinating node
负责接受client的请求,将请求分发到合适的节点,最终把结果汇聚到一起。
每个节点默认都起到了Coordinating node的职责。
- Hot & Warm Node
不同硬件配置的Data Node,用来实现Hot & Warm架构,降低集群部署的成本
冷热架构,为了保证大规模时序索引实时数据分析的时效性,可以根据资源配置不同将 Data Nodes 进行分类形成分层或分组架构。
一部分支持新数据的读写,另一部分仅支持历史数据的存储,存放一些查询发生机率较低的数据。
即 Hot-Warm 架构,对 CPU,磁盘、内存等硬件资源合理的规划和利用,达到性能和效率的最大化。
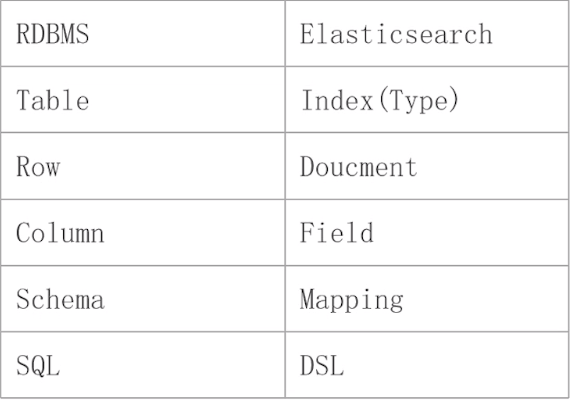
Search API
elk 7.2的更多相关文章
- ELK日志系统:Filebeat使用及Kibana如何设置登录认证
根据elastic上的说法: Filebeat is a lightweight, open source shipper for log file data. As the next-generat ...
- 5分钟部署ELK+filebeat5.1.1
标题有点噱头,不过网络环境好的情况下也差不多了^_^ 1. 首先保证安装了jdk. elasticsearch, logstash, kibana,filebeat都可以通过yum安装,这里前 ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- ELK+Kafka集群日志分析系统
ELK+Kafka集群分析系统部署 因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部 ...
- 第三十章 elk(1) - 第一种架构(最简架构)
软件版本: es:2.4.0 logstash:2.4.0 kibana:4.6.1 一.logstash安装(收集.过滤日志.构建索引) 1.下载:https://www.elastic.co/do ...
- #研发解决方案#基于Apriori算法的Nginx+Lua+ELK异常流量拦截方案
郑昀 基于杨海波的设计文档 创建于2015/8/13 最后更新于2015/8/25 关键词:异常流量.rate limiting.Nginx.Apriori.频繁项集.先验算法.Lua.ELK 本文档 ...
- ELK+redis搭建nginx日志分析平台
ELK+redis搭建nginx日志分析平台发表于 2015-08-19 | 分类于 Linux/Unix | ELK简介ELKStack即Elasticsearch + Logstas ...
- ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程
环境:OS X 10.10.5 + JDK 1.8 步骤: 一.下载ELK的三大组件 Elasticsearch下载地址: https://www.elastic.co/downloads/elast ...
- elk系列4之kibana图形化操作
preface 我们都搭建了ELK系统,且日志也能够正常收集的时候,那么就配置下kibana.我们可以通过kibana配置柱状图,趋势图,统计图,圆饼图等等各类图.下面就拿配置统计图和柱状图为例,结合 ...
- elk平台搭建
很多时候我们需要对日志做一个集中式的处理,但是通常情况下这些日志都分布到n台机器上面,导致一个结果就是效率比较低,而ELK平台可以帮助我们解决这么一件事情: ELK下载:https://www.ela ...
随机推荐
- .Net Core使用Swagger来对接口文档化
参考文档来源:https://www.cnblogs.com/yilezhu/p/9241261.html 官方地址 https://swagger.io/ 代码即接口文档,接口文档即代码 使用.ne ...
- scrapy 爬取图片
scrapy 爬取图片 1.scrapy 有下载图片的自带接口,不用我们在去实现 setting.py设置 # 保存log信息的文件名 LOG_LEVEL = "INFO" # L ...
- leetcode 树类问题
208. Implement Trie (Prefix Tree) 子节点个数对应的是数组
- RabbitMQ的消息传输保障三个层级
这里只简单介绍一下三个层级,笔记摘录自<RabbitMQ实战指南>朱忠华作者 消息可靠传输一般是业务系统接入消息中间件时候首要考虑的问题,一般消息中间件的消息传输保障分为三个层级 1 A ...
- mysql 日期处理函数
首先创建一张实验用的一张表 drop table if exists t_student; create table t_student( id int primary key auto_increm ...
- 解决Python开发中,Pycharm中无法使用中文输入法问题
Pycharm是开发Python程序的利器,但有时会遇到无法输入中文的情况.表现为:在Ubuntu系统可以正常输入中文,却在Pycharm内写注释的时候,切换不出中文.下面演示如何解决此问题. 1.在 ...
- Python Singleton Pattern(单例模式)
简介 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场. 当 ...
- Vue 使用lodash库减少watch对后台请求压力
lodash需要新引入 我使用的是npm方式 使用lodash的_.debounce方法 具体代码: <!doctype html> <html lang="en" ...
- POJ2976Dropping tests(分数规划)
传送门 题目大意:n个二元组a[i],b[i],去掉k个,求sigma a[i]/ sigma b[i]的最大值 代码: #include<iostream> #include<cs ...
- Linux上error while loading shared libraries问题解决方法
在Linux环境执行程序时经常会遇到提示程序依赖动态库.so文件不存在的情况,出现报错"error while loading shared libraries: XXXX.so.XX: c ...