Scala,Java,Python 3种语言编写Spark WordCount示例
首先,我先定义一个文件,hello.txt,里面的内容如下:
hello spark
hello hadoop
hello flink
hello storm
Scala方式
scala版本是2.11.8。
配置maven文件,三个依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
package com.darrenchan.spark
import org.apache.spark.{SparkConf, SparkContext}
object SparkCoreApp2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("WordCountApp")
val sc = new SparkContext(sparkConf)
//业务逻辑
val counts = sc.textFile("D:\\hello.txt").
flatMap(_.split(" ")).
map((_, 1)).
reduceByKey(_+_)
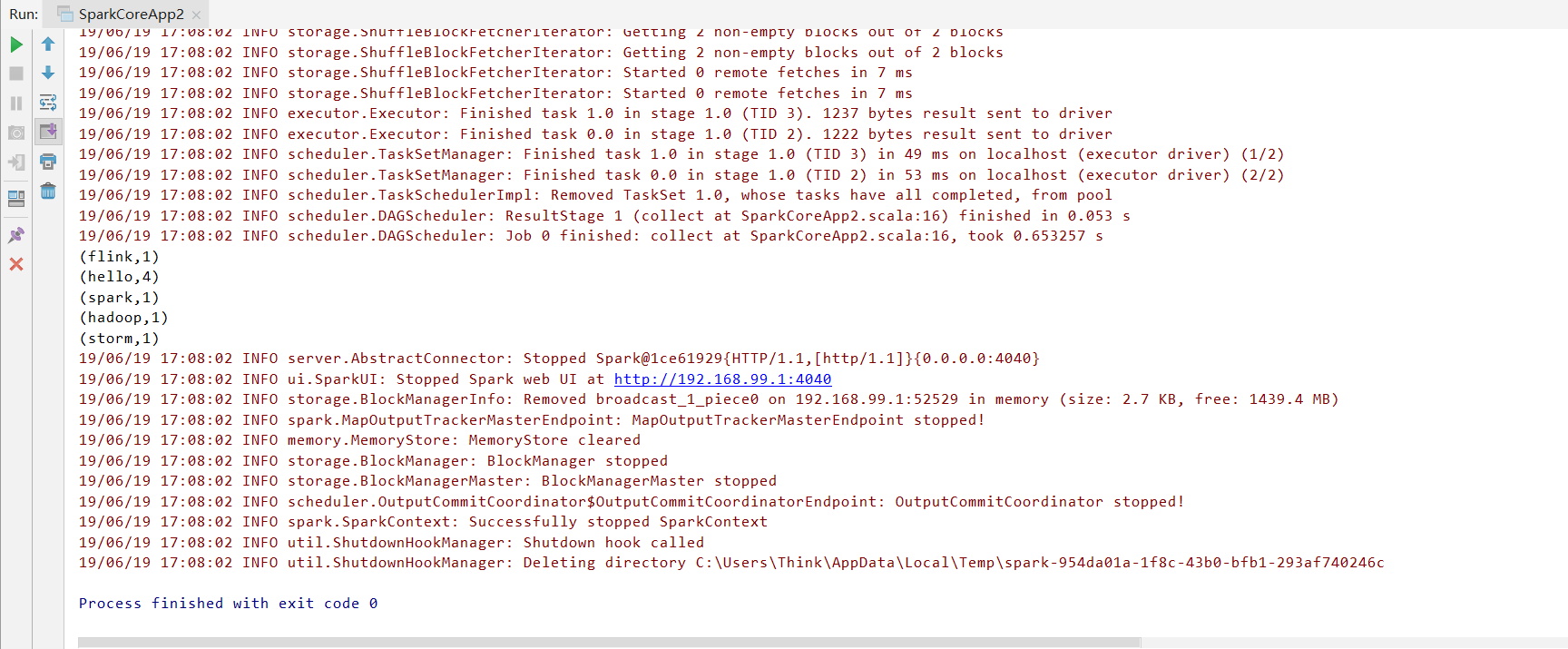
println(counts.collect().mkString("\n"))
sc.stop()
}
}
运行结果:
Java方式
Java8,用lamda表达式。
package com.darrenchan.spark.javaapi; import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2; import java.util.Arrays; public class WordCountApp2 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setMaster("local[2]").setAppName("WordCountApp");
JavaSparkContext sc = new JavaSparkContext(sparkConf); //业务逻辑
JavaPairRDD<String, Integer> counts =
sc.textFile("D:\\hello.txt").
flatMap(line -> Arrays.asList(line.split(" ")).iterator()).
mapToPair(word -> new Tuple2<>(word, 1)).
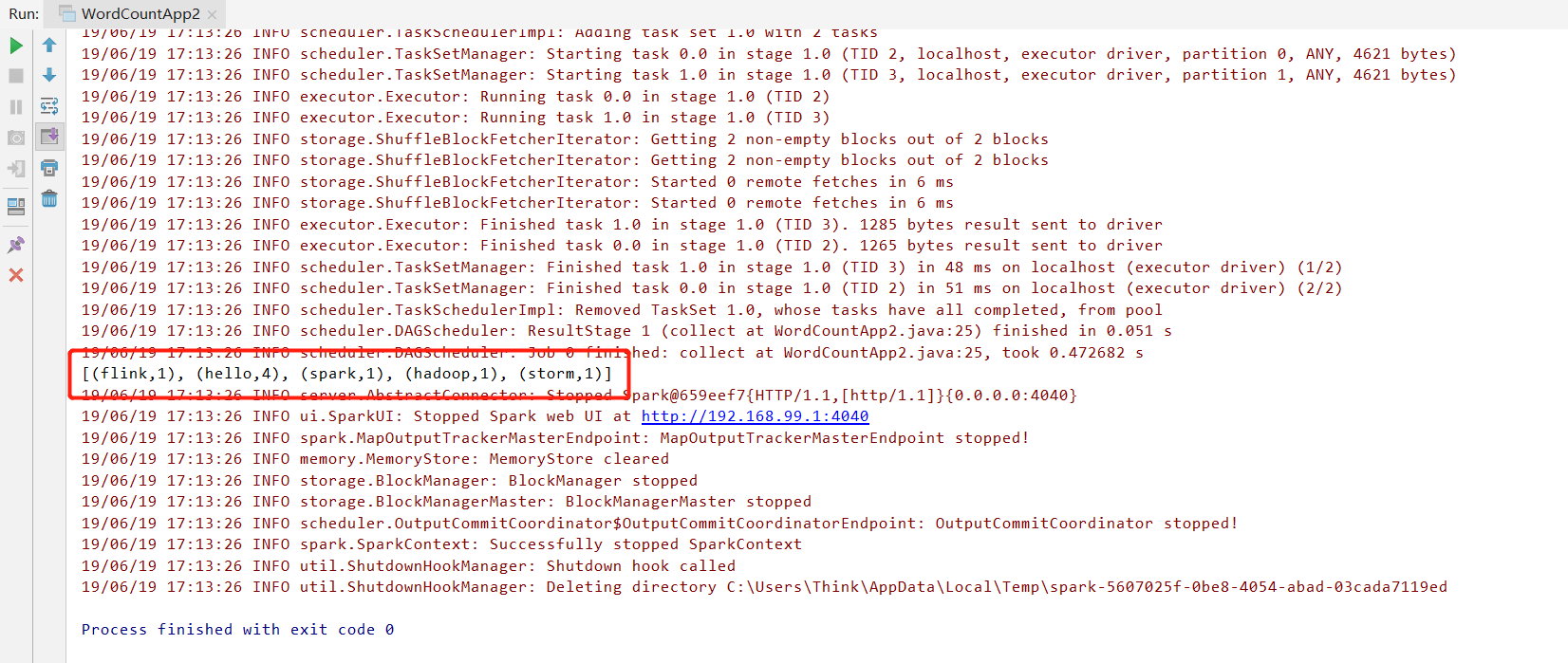
reduceByKey((a, b) -> a + b); System.out.println(counts.collect()); sc.stop();
}
}
运行结果:
Python方式
Python 3.6.5。
from pyspark import SparkConf, SparkContext def main():
# 创建SparkConf,设置Spark相关的参数信息
conf = SparkConf().setMaster("local[2]").setAppName("spark_app")
# 创建SparkContext
sc = SparkContext(conf=conf) # 业务逻辑开发
counts = sc.textFile("D:\\hello.txt").\
flatMap(lambda line: line.split(" ")).\
map(lambda word: (word, 1)).\
reduceByKey(lambda a, b: a + b) print(counts.collect()) sc.stop() if __name__ == '__main__':
main()
运行结果:

使用Python在Windows下运行Spark有很多坑,详见如下链接:
http://note.youdao.com/noteshare?id=aad06f5810f9463a94a2d42144279ea4
Scala,Java,Python 3种语言编写Spark WordCount示例的更多相关文章
- 插入算法分别从C,java,python三种语言进行书写
真正学懂计算机的人(不只是“编程匠”)都对数学有相当的造诣,既能用科学家的严谨思维来求证,也能用工程师的务实手段来解决问题——而这种思维和手段的最佳演绎就是“算法”. 作为一个初级编程人员或者说是一个 ...
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
- 近50种语言编写的“Hello, World”,你会几种?可不要贪杯哦~
本文转自公众号CSDN(ID:CSDNnews)作者:Sylvain Saurel,译者:风车云马
- 三种文本特征提取(TF-IDF/Word2Vec/CountVectorizer)及Spark MLlib调用实例(Scala/Java/python)
https://blog.csdn.net/liulingyuan6/article/details/53390949
- spark Using MLLib in Scala/Java/Python
Using MLLib in ScalaFollowing code snippets can be executed in spark-shell. Binary ClassificationThe ...
- 朴素贝叶斯算法原理及Spark MLlib实例(Scala/Java/Python)
朴素贝叶斯 算法介绍: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法. 朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在没有其它可用信息下,我 ...
- Spark机器学习1·编程入门(scala/java/python)
Spark安装目录 /Users/erichan/Garden/spark-1.4.0-bin-hadoop2.6 基本测试 ./bin/run-example org.apache.spark.ex ...
- idea配置scala编写spark wordcount程序
1.创建scala maven项目 选择骨架的时候为org.scala-tools.archetypes:scala-aechetype-simple 1.2 2.导入包,进入spark官网Docum ...
- Java用n种方法编写实现双色球随机摇号案例
方法清单 规则 实现方式一 实现方式二 实现方式三 实现方式四 实现方法五 之前我用JavaScript编写过一个实现双色球随机摇号的案例, 点击此处查看,今天我再用Java语言来实现这一效果. 规则 ...
随机推荐
- JS时间戳与时间字符串之间的相互转换
时间字符串 转 时间戳 /** * 时间字符串 转 时间戳 * @param {String} time_str 时间字符串(格式"2014-07-10 10:21:12") * ...
- 呵呵,asp.net 屁东西我都会忘记
ASP.NET中的好些基本的东西有的忘了,有的需要学,从现在开始,给自己开一个基本的常用知识点的总结,一是学习,二是备忘. 今天算是第一篇吧! DropDownList在从数据库中得到数据源绑定后,计 ...
- windows下cocos2d-x环境搭建
该教程使用的cocos2dx的版本为3.14,3之后的大概都差不多 Python环境搭建: cocos2dx在windows上新建工程需要用到python脚本,安装python-2.7.x,可以上py ...
- Python 你见过三行代码的爬虫吗
------------恢复内容开始------------ 每次讲爬虫的时候都会从“发送请求” 开始讲,讲到解析页面的时候可能大部分读者都会卡住,因为这部分确实需要一点XPATH或者CSS选择器的前 ...
- Add an Editor to a Detail View 将编辑器添加到详细信息视图
In this lesson, you will learn how to add an editor to a Detail View. For this purpose, the Departme ...
- Spring Boot 2 单元测试
开发环境:IntelliJ IDEA 2019.2.2Spring Boot版本:2.1.8 IDEA新建一个Spring Boot项目后,pom.xml默认包含了Web应用和单元测试两个依赖包.如下 ...
- linux上下键,rlwrap来解决
需要安装两个包1.readline,配置好yum直接安装[root@test152 ~]# yum install readline*2.rlwrap这个下载连接当前有效,找了很多没找到有用的http ...
- PHP 部分语法(一)
PHP: PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言,它以 <?php 开始,并以 ?> 结束: 它还是一门弱类型语言,类型不需显式声明 变量: PHP 没有声明变量的命令 ...
- 执行 Run manage.py Task 报 AttributeError: 'Command' object has no attribute 'usage'?
这个问题,是python与Pycharm不兼容导致,解决办法将Pycharm升级最新版本
- [内核同步]自旋锁spin_lock、spin_lock_irq 和 spin_lock_irqsave 分析【转】
转自:https://www.cnblogs.com/x_wukong/p/8573602.html 转自;https://www.cnblogs.com/aaronLinux/p/5890924.h ...