HashMap原理。图文并茂式解读。这些注意点你一定还不了解
概述
本篇文章我们来聊聊大家日常开发中常用的一个集合类 - HashMap。HashMap 最早出现在 JDK 1.2中,底层基于散列算法实现。HashMap 允许 null 键和 null 值,在计算哈键的哈希值时,null 键哈希值为 0。HashMap 并不保证键值对的顺序,这意味着在进行某些操作后,键值对的顺序可能会发生变化。另外,需要注意的是,HashMap 是非线程安全类,在多线程环境下可能会存在问题。
属性详解
DEFAULT_INITIAL_CAPACITY 默认初始容量
MAXIMUM_CAPACITY 最大容量
DEFAULT_LOAD_FACTOR 默认负载因子
TREEIFY_THRESHOLD 一个桶的树化阈值(超过此值会变成红黑树)
UNTREEIFY_THRESHOLD 一个树的链表还原阈值(小于此值在resize的时候会变回链表)
MIN_TREEIFY_CAPACITY 哈希表的最小树形化容量(为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD)
table
HashMap中的数组(hash表)。hash表的长度总是在2^n。至于原因吗,后面专门会说的。数组里存储的是Node节点的数据
entrySet
Node<K,V> 节点构成的 set
size
当前map中存储节点的数据
modCount
hashMap发生结构性变化的次数,节点转红黑树、扩容等操作。
threshold、loadFactor
扩容阙值和装载因子。
源码知识点必备
getGenericInterfaces和getInterfaces区别
getGenericInterfaces获取直接接口
getInterfaces获取所有接口
ParameterizedType
是Type的子接口,表示一个有参数的类型。就是我们俗称的泛型。实现这个接口的类必须提供equals方法。
getRawType
返回最外层<>前面那个类型,即Map<K ,V>的Map。
getActualTypeArguments
获取“泛型实例”中<>里面的“泛型变量”(也叫类型参数)的值,这个值是一个类型。因为可能有多个“泛型变量”(如:Map<K,V>),所以返回的是一个Type[]。
注意:无论<>中有几层<>嵌套,这个方法仅仅脱去最外层的<>,之后剩下的内容就作为这个方法的返回值,所以其返回值类型是不确定的。
getOwnerType
获得这个类型的所有者的类型,主要对嵌套定义的内部类而言。列如对java.util.Map.Node<K,V> 调用getOwnerType方法返回的是interface java.util.Map接口
comparableClassFor
HashMap类中有一个comparableClassFor(Object x)方法,当x的类型为X,且X直接实现了Comparable接口(比较类型必须为X类本身)时,返回x的运行时类型;否则返回null。通过这个方法,我们可以搞清楚一些与类型、泛型相关的概念和方法
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)
hashCode与自己的高16为进行异或 。 这样更分散
ps:
& : 全部为1则为1,否则为0 偏0
| : 有一个为1则为1,否则为0 偏1
^ : 相同为0 不同为1 更加均衡。 均匀(分散)
hash表维护
在文章开头我们就解释了HashMap中table就是我们的hash表。直观上我们可以理解成一个开辟空间的数组。HashMap通过hash(key)这个方法获取hash值。然后通过hash值确定key在hash表中的位置((n - 1) & hash)。
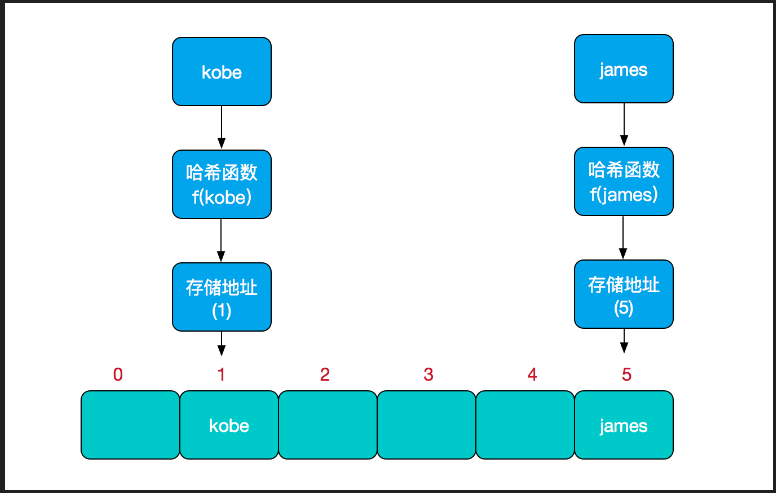
综合上图我们也会发现问题了。key的个数是无限的。但是我们的hash表是有限的。如何能保证hash(key)不会落在同一个位置呢。答案是不能。换句话说就是我们hash(key)无法保证。也就是hashMap会发生hash碰撞的。hash函数只能尽量避免hash碰撞。上面的(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)就是为了让hash更加分散点。这一点上面也作出了解释。
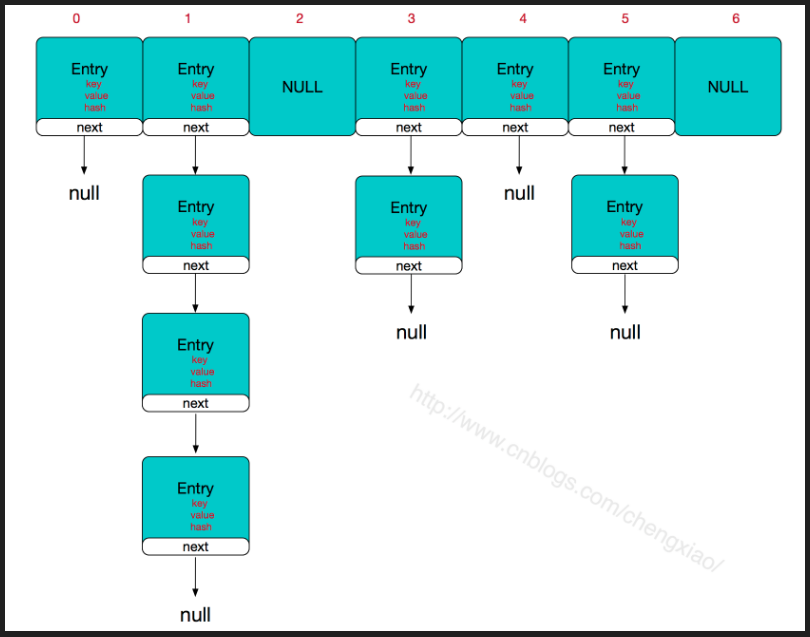
HashMap 数组长度是2^n ?
上面解释了hashmap中hash函数为什么要^ 。 那么深度源码的小伙伴可能会问,为什么hashmap默认容量是16以及后期每次扩容的时候为什么是翻倍扩容。简而言之。为什么hashMap数组长度永远是2的倍数呢。
上面我们知道如何通过hash确定在数组中位置的。
(n - 1) & hash
关于这个n是数组的长度,hash就是key值通过hash函数计算出来的hash值。
& 运算规则是: 全部为1则为1,否则为0
假设目前hashMap容量是16 , 我们来看看在扩容前后我们key的在是数组中的索引。
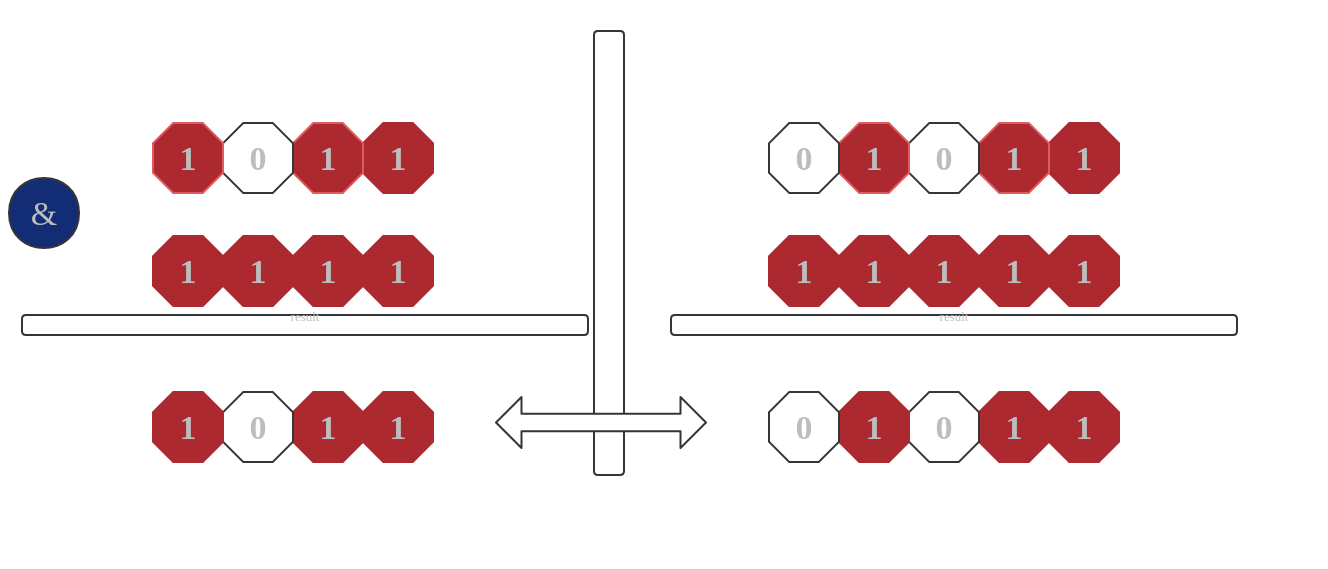
经过图片鲜明的对比我们发现,扩容前后是不会影响原来数据(高位为0)的索引位置的。这里要注意的是并不是说所有数据不受影响,只要原来从右至左第五位为0的hash会受影响,其他不会。这样大大减少了数组位置调换的操作。性能上也大大的提高了。从这里也可以看出hashmap容量越大,扩容是越复杂,因为容量越大,需要换位置的索引越多。
那么如果我们扩容是不是选择扩大2倍 , 我们看看会发生什么样情况。
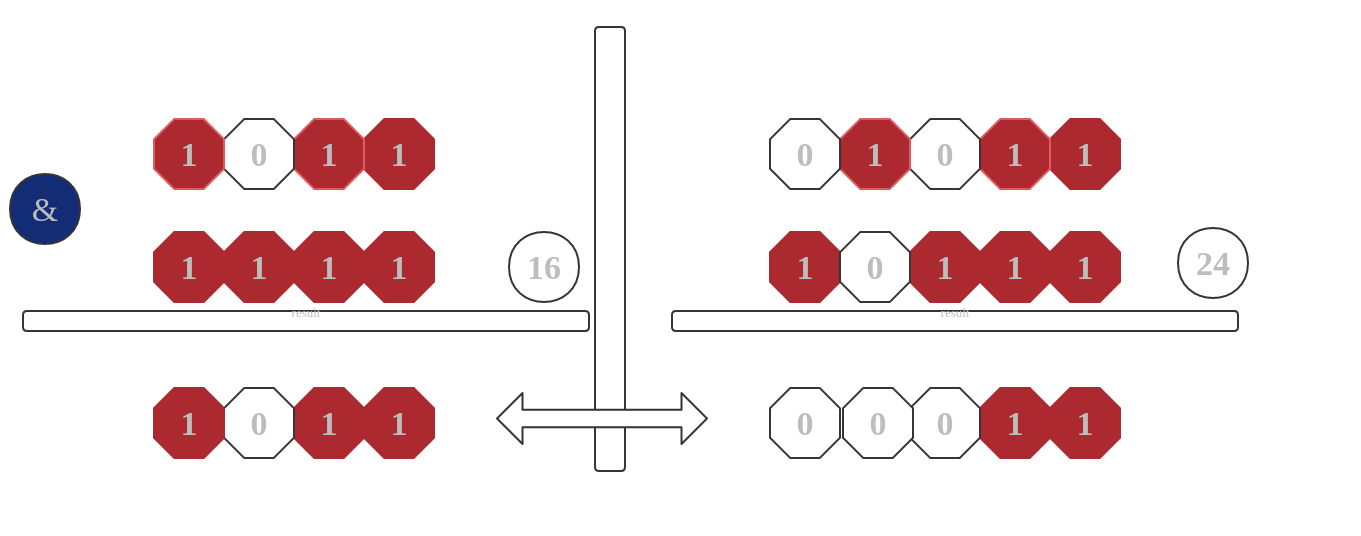
上图中是有16扩展成了24容量。这个时候我们会发现除了(从右至左)第五位以为第四位的数据也发生了变化。这样造成的接口是第四位和第五位的数据都会变化。这样增加了索引位置的数量。所以我们需要在每次扩容为原来的2倍。
神奇的hashmap遍历
做Java的肯定会遇到的一种情况是,为什么我的map遍历的顺序和我添加的顺序不一致呢。有时候我们做列表展示的时候对顺序是有要求的。但是hashmap偏偏和我们想的不一样。今天华仔带你看看为什么会出现这种神奇的遍历。
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
从上面的代码我们可以看出来hashmap在遍历时候,是先遍历数组然后取到数组中链表(红黑树)按照顺序获取node节点的。也即是说我们先按数组再按链表顺序。而不是按照你添加先后的顺序。而上面我们了解添加的node决定其位置的是key的hash值。所以这就解释了为什么hashmap遍历的时候和我们添加不一致的了。
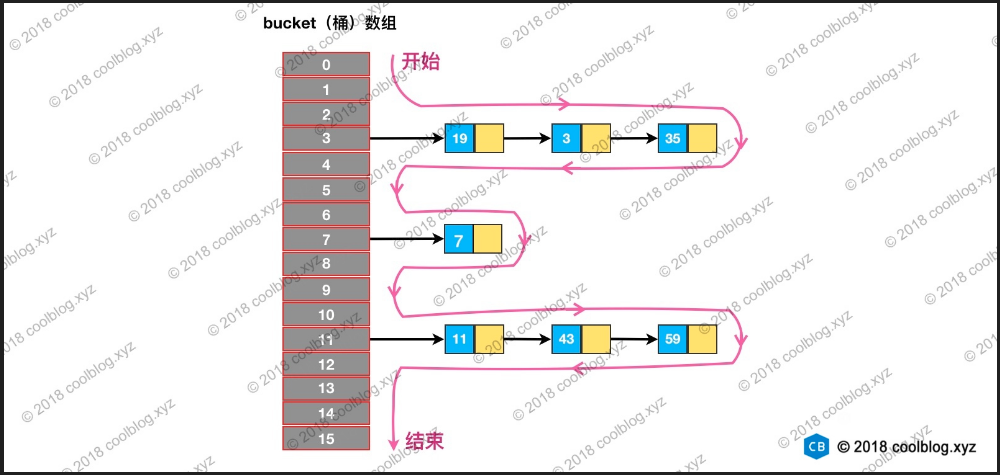
put 流程跟踪
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
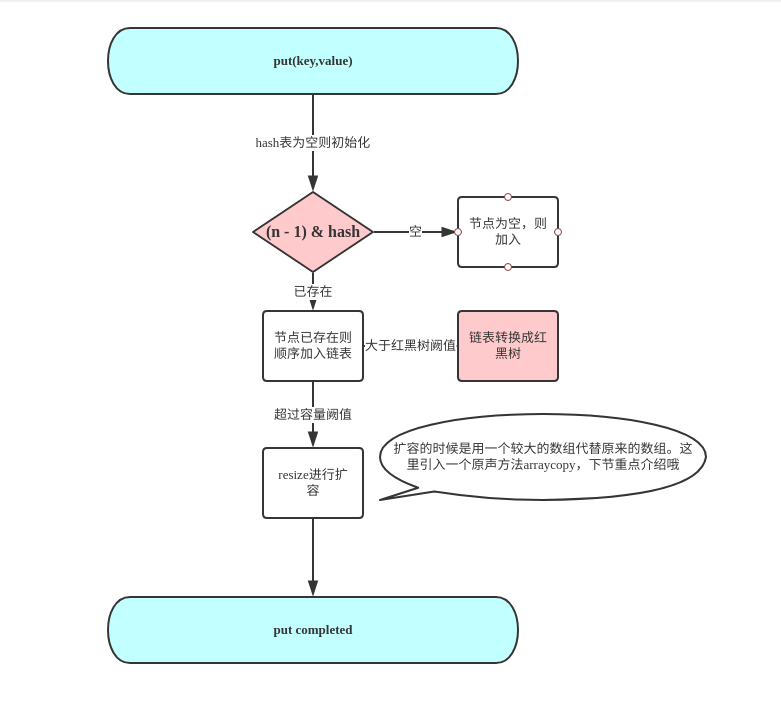
其他方法原理是相同的。值得注意的是remove后临界情况会发生红黑树转链表。所以转红黑树的这个阙值的选取有时候会影响性能的高低。下面看看put的实际源码吧。拜读下大佬的代码。
上面的代码可以看出来put实际调用的方法是putVal();
int hash : key对应的hash值
K key, : key
V value, : value
onlyIfAbsent : 如果存在则忽略,默认false表示新值会覆盖旧值
boolean evict: 表示是否在构造table时调用
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
寒暄一句
个人几天时间总结的,有网上前辈的总结,也有加入个人的想法。
再次申明:以上图片部分来自网络。
# 加入战队
微信公众号

HashMap原理。图文并茂式解读。这些注意点你一定还不了解的更多相关文章
- HashMap原理详解
HashMap 概述 HashMap 是基于哈希表的 Map 接口的非同步实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.此类不保证映射的顺序,特别是它不保证该顺序恒久不 ...
- ==和equasl、hashmap原理(***)
public class String01 { public static void main(String[] args) { String a="test"; String b ...
- Java基础-hashMap原理剖析
Java基础-hashMap原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是哈希(Hash) 答:Hash就是散列,即把对象打散.举个例子,有100000条数 ...
- etcd:从应用场景到实现原理的全方位解读 转自infoq
转自 infoq etcd:从应用场景到实现原理的全方位解读 http://www.infoq.com/cn/articles/etcd-interpretation-application-scen ...
- Java:HashMap原理与设计缘由
前言 Java中使用最多的数据结构基本就是ArrayList和HashMap,HashMap的原理也常常出现在各种面试题中,本文就HashMap的设计与设计缘由作出一一讲解,并解答面试常见的一些问题. ...
- HashMap原理(二) 扩容机制及存取原理
我们在上一个章节<HashMap原理(一) 概念和底层架构>中讲解了HashMap的存储数据结构以及常用的概念及变量,包括capacity容量,threshold变量和loadFactor ...
- java jdk 中HashMap的源码解读
HashMap是我们在日常写代码时最常用到的一个数据结构,它为我们提供key-value形式的数据存储.同时,它的查询,插入效率都非常高. 在之前的排序算法总结里面里,我大致学习了HashMap的实现 ...
- java中HashMap原理?
参考:https://www.cnblogs.com/yuanblog/p/4441017.html(推荐) https://blog.csdn.net/a745233700/article/deta ...
- 2021超详细的HashMap原理分析,面试官就喜欢问这个!
一.散列表结构 散列表结构就是数组+链表的结构 二.什么是哈希? Hash也称散列.哈希,对应的英文单词Hash,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出 这个映射的规则就是对 ...
随机推荐
- 一文带你了解Java反射机制
想要获取更多文章可以访问我的博客 - 代码无止境. 上周上班的时候解决一个需求,需要将一批数据导出到Excel.本来公司的中间件组已经封装好了使用POI生成Excel的工具方法,但是无奈产品的需求里面 ...
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- javascript基本特点,组成和应用
JavaScript 是一种基于客户端浏览器.面向(基于)对象和事件驱动式的网页脚本语言. 1. 基于客户端浏览器:静态语言,跨平台: 2. 面向(基于)对象:本身是没有类class和对象这个概念,但 ...
- 【Git】Found a swap file by the name ".git/.MERGE_MSG.swp"
最近合并分支的时候总是遇到这个问题,导致合并之后还需要再提交一次--有点烦-- 解决方案: 在项目根目录(如/StudioProjects/demo/Leave)下,找到 .git/.MERGE_MS ...
- 【iOS】iOS viewDidLoad 方法名问题
这两天在调试一个项目,跳转到一个页面的时候总是不显示标题栏(当然也没有标题栏的返回按钮),搞了好久,今天总算找到了问题:之前的开发人员竟然把 viewDidLoad 这个基本的方法名写成了 views ...
- codeforces 327 A Ciel and Dancing
题目链接 给你一串只有0和1的数字,然后对某一区间的数翻转1次(0变1 1变0),只翻转一次而且不能不翻转,然后让你计算最多可能出现多少个1. 这里要注意很多细节 比如全为1,要求必须翻转,这时候我们 ...
- 派胜OA二次开发笔记(1)重写主界面
最近从派胜OA 2018 升级到 2019,为了二次开发方便,索性花了两天,反向分析 PaiOA 2019 主界面程序,重写大部分代码,方便对菜单权限进行控制. 主界面/core/index.aspx ...
- kubeadm源码分析
k8s离线安装包 三步安装,简单到难以置信 kubeadm源码分析 说句实在话,kubeadm的代码写的真心一般,质量不是很高. 几个关键点来先说一下kubeadm干的几个核心的事: kubeadm ...
- golang学习(1)---快速hello world
很多著名的计算机语言都是一两个人在业余时间捣鼓出来的,但是Go语言是由Google的团队打造的.可能一些基础的知识点我不会细讲,因为这个时代你真的得快速学习,才能适应发展. 来看看go的hello, ...
- node爬虫的几种简易实现方式
说到爬虫大家可能会觉得很NB的东西,可以爬小电影,羞羞图,没错就是这样的.在node爬虫方面,我也是个新人,这篇文章主要是给大家分享几种实现node 爬虫的方式.第一种方式,采用node,js中的 s ...