helm部署Filebeat + ELK
helm部署Filebeat + ELK
系统架构图:
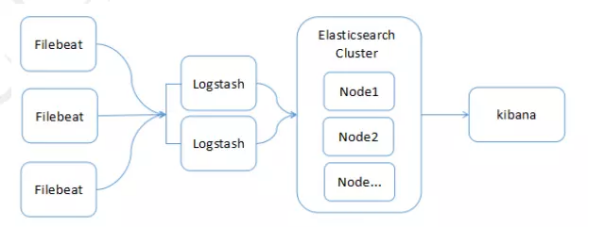
1) 多个Filebeat在各个Node进行日志采集,然后上传至Logstash
2) 多个Logstash节点并行(负载均衡,不作为集群),对日志记录进行过滤处理,然后上传至Elasticsearch集群
3) 多个Elasticsearch构成集群服务,提供日志的索引和存储能力
4) Kibana负责对Elasticsearch中的日志数据进行检索、分析
1. Elasticsearch部署
官方chart地址:https://github.com/elastic/helm-charts/tree/master/elasticsearch
创建logs命名空间
kubectl create ns logs
添加elastic helm charts 仓库
helm repo add elastic https://helm.elastic.co
安装
helm install --name elasticsearch elastic/elasticsearch --namespace logs
参数说明
image: "docker.elastic.co/elasticsearch/elasticsearch"
imageTag: "7.2.0"
imagePullPolicy: "IfNotPresent"
podAnnotations: {}
esJavaOpts: "-Xmx1g -Xms1g"
resources:
requests:
cpu: "100m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-client"
resources:
requests:
storage: 50Gi
2. Filebeat部署
官方chart地址:https://github.com/elastic/helm-charts/tree/master/filebeat
Add the elastic helm charts repo
helm repo add elastic https://helm.elastic.co
Install it
helm install --name filebeat elastic/filebeat --namespace logs
参数说明:
image: "docker.elastic.co/beats/filebeat"
imageTag: "7.2.0"
imagePullPolicy: "IfNotPresent"
resources:
requests:
cpu: "100m"
memory: "100Mi"
limits:
cpu: "1000m"
memory: "200Mi"
那么问题来了,filebeat默认收集宿主机上docker的日志路径:/var/lib/docker/containers。如果我们修改了docker的安装路径要怎么收集呢,很简单修改chart里的DaemonSet文件里边的hostPath参数:
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #改为docker安装路径
对java程序的报错异常log实现多行合并,用multiline定义正则来匹配。
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: docker
containers.ids:
- '*'
multiline.pattern: '^[0-9]'
multiline.negate: true
multiline.match: after
processors:
- add_kubernetes_metadata:
in_cluster: true output.elasticsearch:
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
3. Kibana部署
官方chart地址:https://github.com/elastic/helm-charts/tree/master/kibana
Add the elastic helm charts repo
helm repo add elastic https://helm.elastic.co
Install it
helm install --name kibana elastic/kibana --namespace logs
参数说明:
elasticsearchHosts: "http://elasticsearch-master:9200"
replicas: 1
image: "docker.elastic.co/kibana/kibana"
imageTag: "7.2.0"
imagePullPolicy: "IfNotPresent"
resources:
requests:
cpu: "100m"
memory: "500m"
limits:
cpu: "1000m"
memory: "1Gi"
4. Logstash部署
官方chart地址:https://github.com/helm/charts/tree/master/stable/logstash
安装
$ helm install --name logstash stable/logstash --namespace logs
参数说明:
image: repository: docker.elastic.co/logstash/logstash-oss tag: 7.2.0 pullPolicy: IfNotPresent persistence: enabled: true storageClass: "nfs-client" accessMode: ReadWriteOnce size: 2Gi
匹配label:json的pod日志,没有的话正常收集。
filebeatConfig:
filebeat.yml: |
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition:
equals:
kubernetes.labels.logFormat: "json"
config:
- type: docker
containers.ids:
- "${data.kubernetes.container.id}"
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
- config:
- type: docker
containers.ids:
- "${data.kubernetes.container.id}"
processors:
- add_kubernetes_metadata:
in_cluster: true
output.elasticsearch:
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
5. Elastalert部署
官方chart地址:https://github.com/helm/charts/tree/master/stable/elastalert
安装
helm install -n elastalert ./elastalert --namespace logs
效果图:
helm部署Filebeat + ELK的更多相关文章
- 5分钟部署filebeat + ELK 5.1.1
标题有点噱头,不过网络环境好的情况下也差不多了^_^ 1. 首先保证安装了jdk. elasticsearch, logstash, kibana,filebeat都可以通过yum安装,这里前 ...
- Filebeat+ELK部署文档
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的Filebeat+ELK开源实时日志分析平台的记录过程,有不对的地方还望指出. 简单介绍: 日志主要包括系统日志.应用 ...
- filebeat + ELK 部署篇
ELK Stack Elasticsearch:分布式搜索和分析引擎,具有高可伸缩.高可靠和易管理等特点.基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储.搜索和分析操作.通 ...
- linux单机部署kafka(filebeat+elk组合)
filebeat+elk组合之kafka单机部署 准备: kafka下载链接地址:http://kafka.apache.org/downloads.html 在这里下载kafka_2.12-2.10 ...
- Kafka+Zookeeper+Filebeat+ELK 搭建日志收集系统
ELK ELK目前主流的一种日志系统,过多的就不多介绍了 Filebeat收集日志,将收集的日志输出到kafka,避免网络问题丢失信息 kafka接收到日志消息后直接消费到Logstash Logst ...
- docker stack 部署 filebeat
=============================================== 2018/7/21_第3次修改 ccb_warlock 更新 ...
- Filebeat+ELK
Filebeat+ELK filebeat是logstash的升级版,从功能上来说肯定不如logstash,但是logstah比较耗费资源: filebeat安装 暂时依托于window系统 下载fi ...
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- 使用docker部署filebeat和logstash
想用filebeat读取项目的日志,然后发送logstash.logstash官网有相关的教程,但是docker部署的教程都太简洁了.自己折腾了半天,踩了不少坑,总算是将logstash和filebe ...
随机推荐
- svn checkout 单个文件
$ svn co --depth=empty file:///usr/local/svn/calc calc_new $ cd calc_new $ svn up readme.txt 其中,calc ...
- Joda学习笔记
Joda Time简介 日常业务开发中,经常需要处理日期.比如:获取当前一个月之内的开播记录,获取十分钟之内的红包记录等等.我们之前是用java.util.Calendar实现的,直到我看到占小 ...
- node.js的特点与模块化开发
node.js的代码都是构建在模块化开发的基础之上,模块化开始也是node.js的核心之一. node.js跳过了服务器,它自己不用建设在任何服务器软件之上,node.js的许多设计理念与经典架构(L ...
- java设计模式4.适配器模式、装饰器模式
适配器模式 把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够工作. 1. 类的适配器模式 目标角色:期望的接口,对于类的适配器模式,此角色不可以是具体类 ...
- P2050 [NOI2012]美食节 动态连边优化费用流
题意 类似的一道排队等候,算最小总等待时间的题目. 思路 但是这道题的边数很多,直接跑会tle,可以动态加边,就是先连上倒数第一次操作的边,跑一遍费用流,然后对使用了倒数第一条边的点,连上相应的倒数第 ...
- 杭电多校第二场 1005 hack it
题意: 构造一个n*n 的 01 矩阵, 0 < n < 2001, 矩阵需要满足没有一个子矩阵的4个角都是1,并且矩阵内1的个数至少有85000个. 题解:数论构造题 参考From 代 ...
- CodeForces 765 F Souvenirs 线段树
Souvenirs 题意:给你n个数, m次询问, 对于每次一次询问, 求出询问区间内绝对值差值的最小值. 题解:先按查询的右端点从小到大sort一下,然后对于塞入一个数的时候, 就处理出所有左端点到 ...
- 题解 bzoj 2151 种树
题意 传送门 手写堆大法好啊,题解貌似没有结构体堆的做法,思路有些像配对堆,关于配对堆请自行百度,因为本蒟蒻不会.. 以下是蒟蒻的做法:建立一个大根堆a维护最大价值里面存入它的编号以及价值.听说配对堆 ...
- 弄懂goroutine调度原理
goroutine简介 golang语言作者Rob Pike说,"Goroutine是一个与其他goroutines 并发运行在同一地址空间的Go函数或方法.一个运行的程序由一个或更多个go ...
- pip的使用
目录 一.配置pip环境变量 二.Cmd终端使用pip 三.Pycharm使用pip 四.Jupyter使用pip 如果把python假想成一部手机,那么pip就是这部手机上的应用管家/APP,他可以 ...