论文笔记之:A CNN Cascade for Landmark Guided Semantic Part Segmentation
A CNN Cascade for Landmark Guided Semantic Part Segmentation
ECCV 2016
摘要:本文提出了一种 CNN cascade (CNN 级联)结构,根据一系列的定位(landmarks or keypoints),得到特定的 pose 信息,进行 语义 part 分割。前人有许多单独的工作,但是,貌似没有将这两个工作结合到一起,相互作用的 multi-task 的工作。本文就弥补这个缺口,提出一种 CNN cascade 的 tasks,首先进行 landmark的定位,然后将这个信息作为输入,用于指导 semantic part segmentation。作者将这个结构用于 facial part segmentation,取得了显著的效果。代码将会很快放出,候选连接如下:http://www.cs.nott.ac.uk/~psxasj/
引言:就像摘要里提到的差不多,就是这个意思。不废话了。看看效果图,然后看看别人怎么做的。。。

本文的创新点写的很有特色,说解决了下面的两个问题:
1. Is a CNN for facial part segmentation needed at all ?
2. Can facial landmarks be used for guiding facial part segmentation, thus reversing the result metioned above ?
我们卖个关子(其实,我是想说,先装个逼,但是,。。。,忽略这句话吧,God),先不解释,希望看完后,读者能自己领悟到答案。


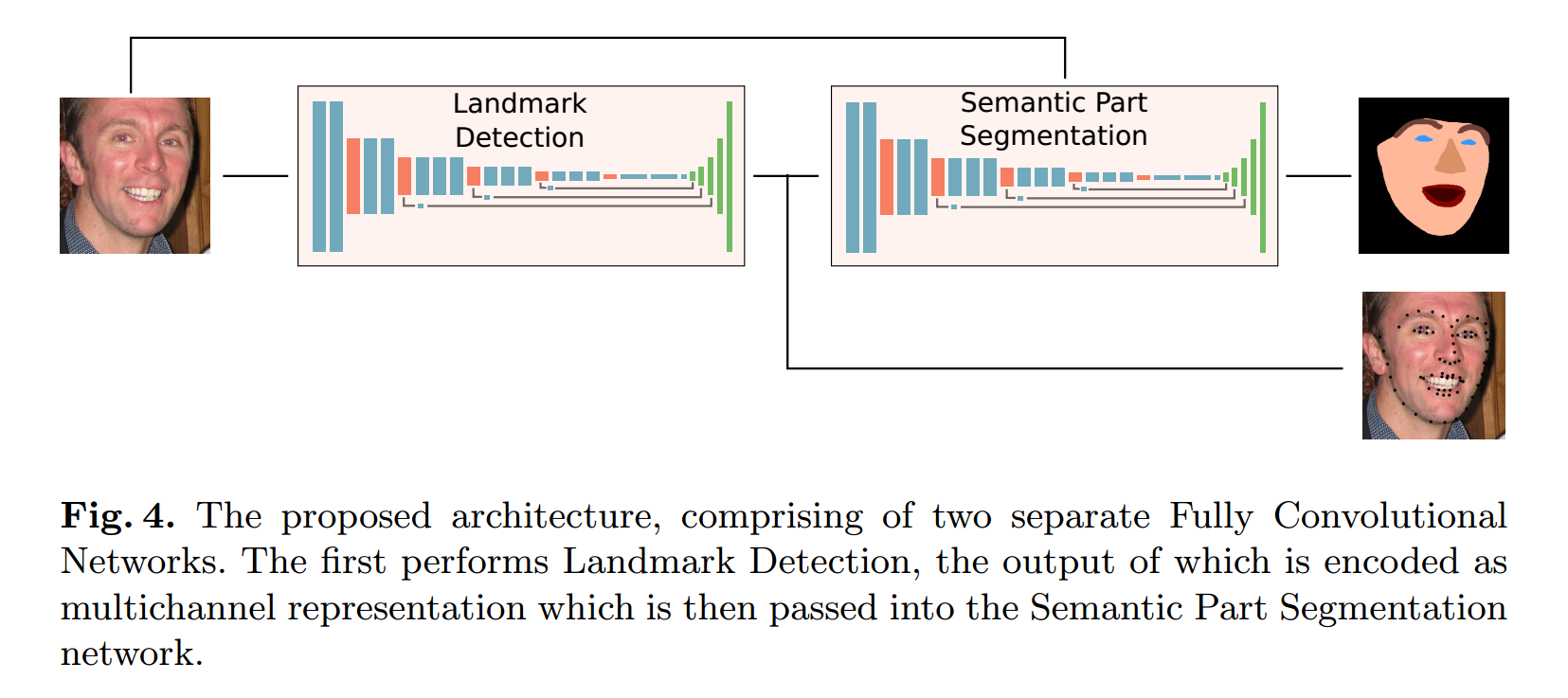
The Proposed Method :
本文提出的 CNN 级联网络结构,如上图 4 所示,是一个 landmark localisation 网络,紧跟着是一个 facial part segmentation 网络结构。这个级联网络是基于 VGG-FCN 的,基于 CAFFE ,主要由两个部分构成:
1. 利用交叉熵损失函数(Sigmoid Cross Entropy Loss)进行 facial landmarks 的检测,这是一个 FCN 网络;
2. 第二,是受到 human pose estimation method 【1】 的激发,检测到的 68 个定位点,编码成 68 个单独的 channels,这个 channels 在其对应的 landmark 位置有一个 2D Gaussian 。这 68 个channels 堆积在一起,和原始图像一起传送给 segmentation network。然后用标准的 Softmax loss 进行分割。
这里的【1】是:Human pose estimation with iterative error feedback. CVPR 2016
接下来,详细的介绍这两个网络架构:
Facial Landmark Detection:
对于 landmark detection 的训练过程类似于训练一个 FCN 用于 part segmentation。将 Landmarks 编码成位于提供的 landmarks' location 的 2D Gaussian。每一个 landmark 分配其单独的 channel 来阻止与其他 landmark 的重合,允许每一个 point 更加容易相互区分。与 part segmentation 主要的不同在于 其 loss function。Sigmoid Cross Entropy Loss 被用来回归一个像素点包含一个 point 的可能性。More concretely,给定我们的 gt Gaussians P 和 预测的 Gaussians p, 每一个相同维度是 N*W*H, 定义的损失函数为:
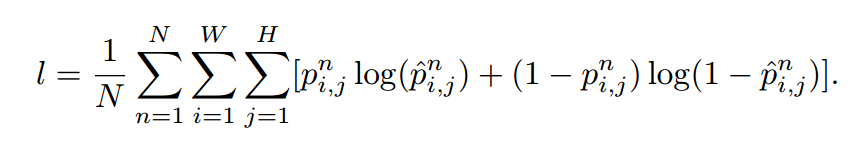
Guided Facial Part Segmentation:
采用和 FCN 类似的配置方法进行分割,利用 softmax loss 作为最后的损失函数。如果 N 是输出的个数,$p_{i, j}$ 是像素点$(i, j)$的预测输出,n 是 gt label,那么 softmax loss l 就可以表达为:
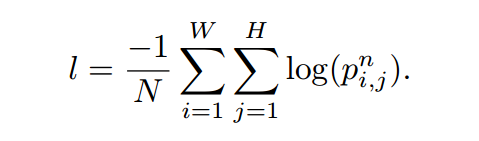
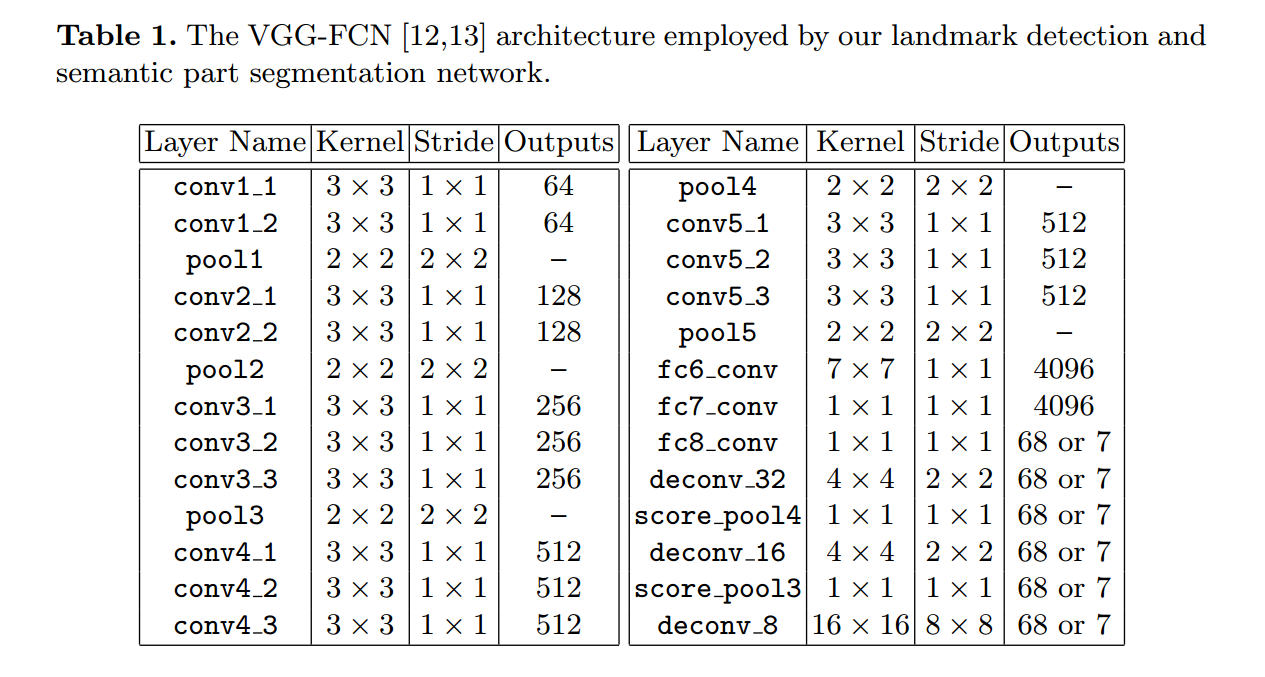
下面的表格展示了所用的 VGG-FCN 网络结构的具体参数设置:
总结:
总体而言,本文是利用 landmark 的引导去做 face part 的分割。所以,网络的设计上就是由两个网络架构来实现的,首先是 landmark detection,然后将该网络的输出,输入到后面的 semantic part segmentation。看到摘要中,有这么一段话:this is the first time in literature that the interplay between pose estimation and semantic part segmentation is investigated. 为什么感觉将其用到 face 的part 分割,并不能充分的说明 pose estimation ? 因为就仅仅是一个人脸的 landmark 而已,哪有 pose 这一说??若是将其应用到 human parsing 上,结合 pose estimation 和 segmentation 还差不多。说实话,感觉有点挂羊头卖狗肉。。。
Reference Paper:
1. Human pose estimation with iterative error feedback. CVPR 2016
2. A CNN Cascade for Landmark Guided Semantic Part Segmentation
论文笔记之:A CNN Cascade for Landmark Guided Semantic Part Segmentation的更多相关文章
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
随机推荐
- (十)Linux 网络编程之ioctl函数
1.介绍 Linux网络程序与内核交互的方法是通过ioctl来实现的,ioctl与网络协议栈进行交互,可得到网络接口的信息,网卡设备的映射属性和配置网络接口.并且还能够查看,修改,删除ARP高速缓存的 ...
- go文件操作大全
参考Go官方库的文件操作分散在多个包中,比如os.ioutil包,我本来想写一篇总结性的Go文件操作的文章,却发现已经有人2015年已经写了一篇这样的文章,写的非常好,所以我翻译成了中文,强烈推荐你阅 ...
- Spring Boot Admin的使用
http://www.jianshu.com/p/e20a5f42a395 ******************************* 上一篇文章中了解了Spring Boot提供的监控接口,例如 ...
- Ajax中return false无效 怎么解决?
var flag=0; $.ajax({ url:"widget?type=member_register&ajax=yes&action=checkname&use ...
- Python 去剑式
Python 去剑式 种种变化,用以体演总诀.共有三百六十种变化. 用以破解普天下各门各派的剑法.「破剑式」虽只一式,但其中于天下各门各派剑法要义兼收并蓄:虽说「无招」却是以普天下剑法之招数为根基,因 ...
- iOS开发拓展篇—CoreLocation地理编码
iOS开发拓展篇—CoreLocation地理编码 一.简单说明 CLGeocoder:地理编码器,其中Geo是地理的英文单词Geography的简写. 1.使用CLGeocoder可以完成“地理编码 ...
- PowerShell脚本:随机密码生成器
脚本名称:s随机密码生成器_v2.63.ps1脚本作用:产生随机密码.每密码字符个数,密码数量,存盘位置等可以自定义.脚本用法:脚本采用了硬编码,所以你需要打开脚本,修改如下变量:$生成密码总个数 = ...
- 获取本地soapUI项目路径
def projectDir = ${projectDir}
- 将字符串拆分为id
Sql : alter function [fn_splitSTR] ( ), -- 5,6,7 ) -- ',' ) )) as begin declare @splitlen int begin ...
- Jmeter—7 测试中使用到的定时器和逻辑控制器
1 测试中提交数据有延时1min,所以查询数据是否提交成功要设置定时器. 固定定时器页面:单位是毫秒 [dinghanhua] 2 集合点.Synchronizing Timer 集合点编辑:集合用户 ...