读书摘要,Hackable Projects
完整读完Google的三篇谈Hackable Projects的文章,以及一篇从Test Pyramid看UnitTest的比重、一篇谈Optimal Logging的文章,感觉这5篇在测试、日志两个方面对工程的速度、大小、解耦三个方面做了深入而系统的解读,非常值得一看,专业的测试角度剖析工程,有一种解剖学的感觉,这刷新了我对测试的理解,我估计职业的开发工程师里能有这么全面的视角的估计比例本就不高。此处简要摘录做个笔记,结合自己的经验体会,在这方面会有系统化的视角。
Hackable Projects - Pillar 1: Code Health
- Readable Code
- Code Style: google code style guid
- Code Review
- Presubmit Test
- Single Branch And Reducing Risk
- Loose Couping
- SOLID
- Aggressively Reduce Technical Debt
- dependency enforcement
Hackable Projects - Pillar 2: Debuggability
- Principle
- Debuggability means being able to easily find what’s wrong with a piece of software
- through logs, statistics or debugger tools
- Debuggability doesn’t happen by accident: you need to design it into your product
- Debuggability means being able to easily find what’s wrong with a piece of software
- Running on Localhost
- need some kind of script that brings up your server stack on localhost
- Debugging Mobile Apps
- mobile is hard
- unit tests are great for hackability here
- Test-Drive Your Android Code:Robolectric
- Android Testing Support Library:Espresso test
- Create and run unit tests, performance tests, and UI tests for your Xcode project: XCTest
- iOS UI Automation Test Framework:EarlGrey
- When Debugging gets Tricky
- debugging flags and instructions
- you need to build these kinds of things into your product
- Proper Logging
- It’s hackability to get the right logs when you need them
- Logs are also useful for development
- Optimal Logging
- Monitoring and Statistics
- System Under Test (SUT) Size
Hackable Projects - Pillar 3: Infrastructure
- Build Systems Speed
- Replace make with ninja
- Use the gold linker instead of ld
- Detect and delete dead code in your project
- Reduce the number of dependencies
- enforce dependency rules so new ones are not added lightly
- Give the developers faster machines
- Use distributed build, which is available with many open-source continuous integration systems
- feedback cycles kill hackability, for many reasons:
- Build and test times longer than a handful of seconds cause many developers’ minds to wander, taking them out of the zone.
- Excessive build or release times* makes tinkering and refactoring much harder.
- The main axes of improvement are:
- Reduce the amount of code being compiled.
- Replace tools with faster counterparts.
- Increase processing power, maybe through parallelization or distributed systems.
- Continuous Integration and Presubmit Queues
- You should build and run tests on all platforms you release on.
- At a minimum, you should build and test on all platforms, but it’s even better if you do it in presubmit.
- Chromium:It has developed over the years so that a normal patch builds and tests on about 30 different build configurations before commit.
- Test Speed:
- if it takes more than a minute to execute, its value is greatly diminished
- Sharding and parallelization.
- Continuously measure how long it takes to run one build+test cycle in your continuous build, and have someone take action when it gets slower.
- Remove tests that don’t pull their weight.
- If you have tests that bring up a local server stack, for instance inter-server integration tests, making your servers boot faster is going to make the tests faster as well.
- Workflow Speed
- You need to keep track of your core workflows as your project grows.
- Your version control system may work fine for years, but become too slow once the project becomes big enough.
- Release Often
- It aids hackability to deploy to real users as fast as possible.
- Easy Reverts:
- If you look in the commit log for the Chromium project, you will see that a significant percentage of the commits are reverts of a previous commits.
- Performance Tests: Measure Everything:
- Is it critical that your app starts up within a second?
- Should your app always render at 60 fps when it’s scrolled up or down?
- Should your web server always serve a response within 100 ms?
- Should your mobile app be smaller than 8 MB?
Just Say No to More End-to-End Tests
Good ideas often fail in practice, and in the world of testing, one pervasive good idea that often fails in practice is a testing strategy built around end-to-end tests.
What Went Wrong for End-to-End test:
- The team completed their coding milestone a week late (and worked a lot of overtime).
- Finding the root cause for a failing end-to-end test is painful and can take a long time.
- Partner failures and lab failures ruined the test results on multiple days.
- Many smaller bugs were hidden behind bigger bugs.
- End-to-end tests were flaky at times.
- Developers had to wait until the following day to know if a fix worked or not.
The True Value of Tests:
- A failing test does not directly benefit the user.
- A bug fix directly benefits the user.
Building the Right Feedback Loop:
- It's fast
- It's reliable(smaller)
- It isolates failures
Think Smaller, Not Larger
Unit Test
Unit tests take a small piece of the product and test that piece in isolation.
- Unit tests are fast.
- Unit tests are reliable.
- Unit tests isolate failures.
Writing effective unit tests requires skills in areas:
- dependency management
- mocking
- hermetic testing
With end-to-end tests, you have to wait: first for the entire product to be built, then for it to be deployed, and finally for all end-to-end tests to run.
Although end-to-end tests do a better job of simulating real user scenarios, this advantage quickly becomes outweighed by all the disadvantages of the end-to-end feedback loop:
- NOT fast
- NOT Reliable
- NOT Isolates Failures
Integration Tests
Unit tests do have one major disadvantage: even if the units work well in isolation, you do not know if they work well together.
But even then, you do not necessarily need end-to-end tests. For that, you can use an integration test.
An integration test takes a small group of units, often two units, and tests their behavior as a whole, verifying that they coherently work together.
Testing Pyramid
Even with both unit tests and integration tests, you probably still will want a small number of end-to-end tests to verify the system as a whole.
To find the right balance between all three test types, the best visual aid to use is the testing pyramid:
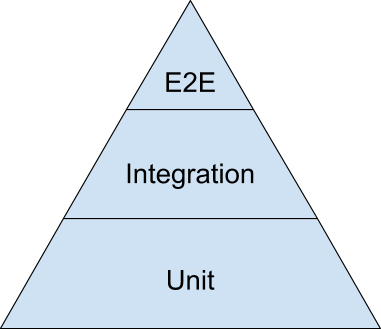
As a good first guess, Google often suggests a 70/20/10 split: 70% unit tests, 20% integration tests, and 10% end-to-end tests.
Optimal Logging
Channeling Goldilocks:
Massive, disk-quota burning logs are a clear indicator that little thought was put in to logging.
- Never log too much:
Goals of logging:
- help with bug investigation
- event confirmation
If your log can’t explain the cause of a bug or whether a certain transaction took place, you are logging too little.
- The only thing worse than logging too much is logging too little.
Good things to log:
- Important startup configuration
- Errors
- Warnings
- Changes to persistent data
- Requests and responses between major system components
- Significant state changes
- User interactions
- Calls with a known risk of failure
- Waits on conditions that could take measurable time to satisfy
- Periodic progress during long-running tasks
- Significant branch points of logic and conditions that led to the branch
- Summaries of processing steps or events from high level functions - Avoid logging every step of a complex process in low-level functions.
Bad things to log:
- Function entry - Don’t log a function entry unless it is significant or logged at the debug level.
- Data within a loop - Avoid logging from many iterations of a loop. It is OK to log from iterations of small loops or to log periodically from large loops.
- Content of large messages or files - Truncate or summarize the data in some way that will be useful to debugging.
- Benign errors - Errors that are not really errors can confuse the log reader. This sometimes happens when exception handling is part of successful execution flow.
- Repetitive errors - Do not repetitively log the same or similar error. This can quickly fill a log and hide the actual cause. Frequency of error types is best handled by monitoring. Logs only need to capture detail for some of those errors.
There is More Than One Level
Test logs should always contain:
- Test execution environment
- Initial state
- Setup steps
- Test case steps
- Interactions with the system
- Expected results
- Actual results
- Teardown steps
Conditional Verbosity With Temporary Log Queues
to create temporary, in-memory log queues. Throughout processing of a transaction, append verbose details about each step to the queue. If the transaction completes successfully, discard the queue and log a summary. If an error is encountered, log the content of the entire queue and the error.
Failures and Flakiness Are Opportunities
If you have a hard time determining the cause of an error, it's a great opportunity to improve your logging. Before fixing the problem, fix your logging so that the logs clearly show the cause.
Might As Well Log Performance Data
Logged timing data can help debug performance issues.
Following the Trail Through Many Threads and Processes
You should create unique identifiers for transactions that involve processing across many threads and/or processes
Monitoring and Logging Complement Each Other
a monitoring alert is simply a trigger for you to start an investigation. Monitoring shows the symptoms of problems. Logs provide details and state on individual transactions
读书摘要,Hackable Projects的更多相关文章
- 《Effective C++》读书摘要
http://www.cnblogs.com/fanzhidongyzby/archive/2012/11/18/2775603.html 1.让自己习惯C++ 条款01:视C++为一个语言联邦 条款 ...
- 读书摘要:第七章 闩Suan锁和自旋锁
摘要: 1.闩锁就像是内存上的锁,随着越来越多的线程参与进来,他们争相访问同一块内存,导致堵塞.2.自旋锁就是闩锁,不同之处是如果访问的内存不可用,它将继续检查轮询一段时间.3.拴锁和自旋锁是我们无法 ...
- JAVA 技术手册 卷1 第十四章『多线程』 读书摘要
什么是线程 进程受CPU时间片的轮转调度,进而予人多任务并发的感觉. 线程在更低层次上扩展多任务概念,一个进程通常包含多个线程. 进程各自数据独立,而线程共享数据. 数据独立使进程相互通信变得繁难,共 ...
- 读书摘要,一种新的黑客文化:programming is forgetting
http://opentranscripts.org/transcript/programming-forgetting-new-hacker-ethic/ 这篇文章非常有意思,作者是一个计算机教师, ...
- 《Java多线程核心技术》读书摘要
Chapter1: 进程是操作系统管理的基本单元,线程是CPU调到的基本单元. 调用myThread.run()方法,JVM不会生成新的线程,myThread.start()方法调用两次JVM会报错. ...
- Java设计模式(Design Patterns In Java)读书摘要——第1章 绪论
为何需要模式 模式是做事的方法,是实现目标,研磨技术的方法.通俗点说,模式是为了解决某个行业的某个问题的有效的方法或技艺. 为何需要设计模式 为了提升代码的水准,是代码变得简洁而易用.模式是一种思想, ...
- JAVA设计模式(DESIGN PATTERNS IN JAVA)读书摘要 第1部分接口型模式——第4章 外观(Facade)模式
外观模式就类似于一个工具包,一个类对应一个功能. 外观模式的意图是为子系统提供一个接口,便于它的使用. 书中给出的例子是画一个哑弹的飞行路径, 初始的类的设计是这样的,看下图, ShowFlight类 ...
- HeadFirst SQL 读书摘要
数据库都是用 圆柱形表示的. 数据库中包含表 表中包含行和列 行又叫记录record, 列又叫 字段field 创建数据库 create database mypipe_l; 选择数据库 use m ...
- Tomcat权威指南-读书摘要系列10
Tomcat集群 一些集群技术 DNS请求分配 TCP网络地址转换请求分配 Mod_proxy_balance负载均衡与故障复原 JDBC请求分布与故障复原
随机推荐
- jQuery 更改checkbox的状态,无效
今天写页面遇到复选框动态全选或全不选问题,正常写法如下: $("#tb").find("input[type='checkbox']").attr(" ...
- mysql substring_index substring left right方法
函数简介: SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos F ...
- PHP curl https访问问题
PHP curl https访问问题,原代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 /* @String url URL地址 * @Array data P ...
- XAML中的特殊符号几空白字符处理
阅读目录 介绍 详细 处理 Demo下载 介绍 XAML标记语言是基于xml的,所以很多xml中的特殊符号在XAML也是需要处理的. 详细 (取自msdn) 字符 Entity 注释 &(“a ...
- 10个开源的PHP网站内容管理系统
1. DEDE -这是一款国内开源的cms,作者是一个个人,能做出如此功能的cms,是相当不错的.2007版功能十分强大,希望能改善之前数据量一大,更新静态页就很慢的缺点.因为开源,有较多的玩家和拥护 ...
- linux权限补充:rwt rwT rws rwS 特殊权限
众所周知,Linux的文件权限如: 777:666等,其实只要在相应的文件上加上UID的权限,就可以用到加权限人的身份去运行这个文件.所以我们只需要将bash复制出来到另一个地方,然后用root加上U ...
- android Timer使用方法
Timer属性:http://www.apihome.cn/api/java/Timer.html 声明创建: private Timer mTimer; protected void onCreat ...
- C# 中的占位符本质
占位符本质 1.占位符是相对于String字符串类型而言的. 2.占位符其实就是调用String.Format()方法.把指定的变量拼接到定义好的字符串模板中组成新的字符串.
- OpenCV 之 图像平滑
1 图像平滑 图像平滑,可用来对图像进行去噪 (noise reduction) 或 模糊化处理 (blurring),实际上图像平滑仍然属于图像空间滤波的一种 (低通滤波) 既然是滤波,则图像中任 ...
- BNUOJ 52325 Increasing or Decreasing 数位dp
传送门:BNUOJ 52325 Increasing or Decreasing题意:求[l,r]非递增和非递减序列的个数思路:数位dp,dp[pos][pre][status] pos:处理到第几位 ...