Design3:使用HierarchyID构建数据的分层结构
1,传统的分层结构是父子结构,表结构中有一个ParentID字段自引用表的主键,表示“归属”关系,例如
create table dbo.emph
(
ID int not null primary key,
ParentID int foreign key references dbo.emph(id),
Descr varchar(100) not null
)
示例数据是一个简单的HR职称结构,Boss,M表示的Mananger,L表示的是Leader,E表示的是Employee。

2,将父子结构转换为使用HierarchyID的结构
2.1 首先创建一个新表 dbo.emph2,代码以下
create table dbo.emph2
(
idpath hierarchyid not null primary key,
id int not null,
--parentpath as idpath.GetAncestor(1) persisted foreign key references dbo.emph2(idpath),
descr varchar(100)
) create unique nonclustered index idx_emph2_unique on dbo.emph2(id)
代码分析:
- 不需要ParentID字段,因为HierarchyID类型能够获取Ancestor(1)函数来获取ParentID,所以不需要通过外键关系来限制。
- IDPath能够标识每一行在分层结构中的位置,但是不能标识每一行的ID,所以ID字段是必须的。
- 创建一个唯一索引,强制ID唯一。
2.2 将父子结构的数据填充到使用HierarchyID构建的表中
;with cte(idpath,id,descr) as
(
select cast(HierarchyID::GetRoot().ToString() as Varchar(max)) as idpath,ID,Descr
from dbo.emph
where ParentID is null union all select cast(c.idpath+cast(e.id as varchar)+'/' as varchar(max)) as idpath,e.id,e.descr
from dbo.emph e
inner join cte c on e.parentid=c.id
)
insert dbo.emph2 (idpath,id,descr)
select idpath,id,descr
from cte
HierarchyID类型的字符串格式如:‘/1/2/3/’,字符串以‘/’开头,并以‘/’结尾;
HierarchyID类型不会自动生成节点的位置,需要在代码中将父子关系拼接成字符串,
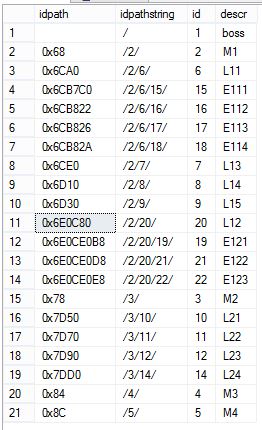
2.3 查询新表dbo.emph2,将HierarchyID类型转换为字符串,能更直观地看出其结构和位置。例如,idpathstring='/2/6/15/'的上一级父节点的path是‘/2/6/’,idpath=‘/2/6/’的ID是6。
select idpath, idpath.ToString() as idpathstring,id,descr
from dbo.emph2
2.4 查看某一个节点的父节点,@NodeID是一个节点ID,@Upcnt是指@Node向上的第几个父节点,如果为Null,那么查询出所有的父节点。
alter procedure dbo.usp_GetAncestor
@NodeID int,
@Upcnt int=null
as
begin declare @node HierarchyID select @node=idpath
from dbo.emph2
where id=@NodeID --get all ancestors
if @Upcnt is null
begin
set @Upcnt=@node.GetLevel() --;with cte(idpath,id,descr,Level) as
--(
-- select idpath,id,descr, 0 as Level
-- from dbo.emph2
-- where id=@NodeID
-- union all -- select e.idpath,e.id,e.descr,c.Level+1 as Level
-- from dbo.emph2 e
-- inner join cte c on e.idpath=c.idpath.GetAncestor(1)
-- where c.Level<@Upcnt
--)
--select idpath,idpath.ToString() as idpathstring,id,descr
--from cte declare @rt table(idpath hierarchyid,idpathstring varchar(max),id int ,descr varchar(100))
declare @i int=0 while @i<=@Upcnt
begin
insert into @rt
select idpath, idpath.ToString() as idpathstring,id,descr
from dbo.emph2
where idpath=@node.GetAncestor(@i); set @i=@i+1
end
select idpath, idpath.ToString() as idpathstring,id,descr
from @rt
end
else
begin
select idpath, idpath.ToString() as idpathstring,id,descr
from dbo.emph2
where idpath=@node.GetAncestor(@Upcnt);
end
end
2.5 查询子节点
alter procedure dbo.usp_GetDescendant
@NodeID int,
@Downcnt int=null
as
begin
declare @Node hierarchyid select @node=idpath
from dbo.emph2
where id=@NodeID select idpath, idpath.ToString() as idpathstring,id,descr
from dbo.emph2
where idpath.IsDescendantOf(@Node)=1
and (@Downcnt is null or (idpath.GetLevel()=@Node.GetLevel()+@Downcnt))
end
2.6 增加一个节点,有时节点的idpath是有顺序的,为了保证顺序,必须使用GetDescendant函数。
--在子节点序列的末尾加入新节点 create procedure dbo.usp_addnode
@parentid int,
@id int,
@descr varchar(100)
as
begin
declare @parentnode hierarchyid
declare @maxchildnode hierarchyid select @parentnode=idpath
from dbo.emph2
where id=@parentid select @maxchildnode=max(idpath)
from dbo.emph2
where idpath.GetAncestor(1)=@parentnode insert into dbo.emph2(idpath,id,descr)
select @parentnode.GetDescendant(@maxchildnode,null),@id,@descr
end
--按照一定的顺序插入子节点 alter procedure dbo.usp_addnode_order
@parentid int,
@childleft int,
@childright int,
@id int,
@descr varchar(100)
as
begin declare @childrightnode hierarchyid
declare @childleftnode hierarchyid
declare @parentnode hierarchyid select @childleftnode=idpath
from dbo.emph2
where id=@childleft select @childrightnode=idpath
from dbo.emph2
where id=@childright select @parentnode=idpath
from dbo.emph2
where id=@parentid insert into dbo.emph2(idpath,id,descr)
select @parentnode.GetDescendant(@childleftnode,@childrightnode),@id,@descr end
对stored procedure 进行测试,并对查询结果进行排序,如下图
exec dbo.usp_addnode 5,25,'L41'
exec dbo.usp_addnode 5,26,'L42'
exec dbo.usp_addnode_order 5,25,26,27,'L43' select idpath, idpath.ToString() as idpathstring,id,descr
from dbo.emph2
order by idpath

2.7 删除一个节点
如果删除的是叶子节点,非常简单,删除叶子节点不会影响其他节点,但是,如果删除的是非叶子节点,必须处理好其子节点,否则,其子节点将会从层次结构游离出来,成为非法存在,所以在删除一个节点的同时,必须为其可能存在的子节点指定一个新的父节点。
alter procedure dbo.usp_deletenode
@deleteid int,
@childnewparentid int
as
begin
declare @deletenode hierarchyid select @deletenode=idpath
from dbo.emph2
where id=@deleteid declare @id int
declare @descr varchar(100) declare cur_child cursor
for select id,descr from dbo.emph2
where idpath.IsDescendantOf(@deletenode)=1 and id!=@deleteid open cur_child fetch next from cur_child into @id,@descr while @@FETCH_STATUS=0
begin
delete dbo.emph2 where id=@id
exec dbo.usp_addnode @childnewparentid,@id,@descr fetch next from cur_child into @id,@descr
end close cur_child
deallocate cur_child delete dbo.emph2 where id=@deleteid
end
注意:IsDescendantOf函数包含当前节点,要想获取当前节点的所有子孙节点,必须将当前节点过滤掉。
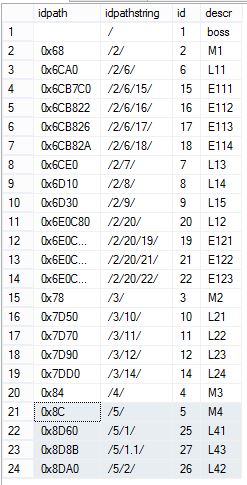
测试,将id=5的节点删除,并将其子节点挂在id=4的节点下。
exec dbo.usp_deletenode 5,4
查询结果
select idpath, idpath.ToString() as idpathstring,id,descr
from dbo.emph2
order by idpath

使用存储过程查询id=4的子孙节点
exec dbo.usp_getdescendant 4
2.8 更新一个节点
更新一个节点,变更其父节点,同样面临如何处理其子节点的问题。
create procedure dbo.usp_updatenode
@id int,
@parentid int,
@childnewparentid int
as
begin
--获取节点的idpath
declare @deletenode hierarchyid select @deletenode=idpath
from dbo.emph2
where id=@id --删除旧节点,并变更节点的父节点
declare @descr varchar(100) select @descr=descr
from dbo.emph2
where id=@id delete dbo.emph2 where id=@id exec dbo.usp_addnode @parentid,@id,@descr --逐个变更子节点的父节点
declare @childid int
declare @childdescr varchar(100) declare cur_child cursor
for select id,descr from dbo.emph2
where idpath.IsDescendantOf(@deletenode)=1 and id!=@id open cur_child
fetch next from cur_child into @childid,@childdescr while @@FETCH_STATUS=0
begin
delete dbo.emph2 where id=@childid
exec dbo.usp_addnode @childnewparentid,@childid,@childdescr fetch next from cur_child into @childid,@childdescr
end close cur_child
deallocate cur_child
end
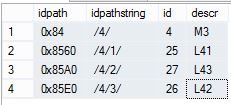
测试数据如下
测试的目的是将id=5的所有子节点挂在id=4的节点下,并强id=5的父节点变更为id=8的节点
exec dbo.usp_updatenode 5,8,4
查询结果
select idpath, idpath.ToString() as idpathstring,id,descr
from dbo.emph2
order by idpath

Design3:使用HierarchyID构建数据的分层结构的更多相关文章
- Design2:使用HierarchyID构建数据的分层结构
1,传统的分层结构是父子结构,表结构中有一个ParentID字段自引用表的主键,表示“归属”关系,例如 create table dbo.emph ( ID int not null primary ...
- 基于腾讯云存储COS的ClickHouse数据冷热分层方案
一.ClickHouse简介 ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),支持PB级数据量的交互式分析,ClickHouse最初是为YandexMetrica ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 内核中用于数据接收的结构体struct msghdr(转)
内核中用于数据接收的结构体struct msghdr(转) 我们从一个实际的数据包发送的例子入手,来看看其发送的具体流程,以及过程中涉及到的相关数据结构.在我们的虚拟机上发送icmp回显请求包,pin ...
- H264的句法和语法总结(一)分层结构
在H.264 中,句法元素共被组织成 序列.图像.片.宏块.子宏块五个层次.在这样的结构中,每一层的头部和它的数据部分形成管理与被管理的强依赖关系,头部的句法元素是该层数据的核心,而一旦头部丢失,数 ...
- 【驱动】网卡驱动·linux内核网络分层结构
Preface Linux内核对网络驱动程序使用统一的接口,并且对于网络设备采用面向对象的思想设计. Linux内核采用分层结构处理网络数据包.分层结构与网络协议的结构匹配,既能简化数据包处理流程 ...
- [转]linux内核网络分层结构
Preface Linux内核对网络驱动程序使用统一的接口,并且对于网络设备采用面向对象的思想设计. Linux内核采用分层结构处理网络数据包.分层结构与网络协议的结构匹配,既能简化数据包处理流程 ...
- Linux 网络设备驱动开发(一) —— linux内核网络分层结构
Preface Linux内核对网络驱动程序使用统一的接口,并且对于网络设备采用面向对象的思想设计. Linux内核采用分层结构处理网络数据包.分层结构与网络协议的结构匹配,既能简化数据包处理流程,又 ...
- JS函数动作分层结构详解及Document.getElementById 释义 js及cs数据类型区别 事件 函数 变量 script标签 var function
html +css 静态页面 js 动态 交互 原理: js就是修改样式, 比如弹出一个对话框. 弹出的过程就是这个框由disable 变成display:enable. 又或者当鼠标指向 ...
随机推荐
- Cobbler学习之一--Fedora17下配置Cobbler安装环境
1:Cobbler是什么 Cobbler是一大Linux装机利器,可以快速的建立网络安装环境. 2:安装Cobbler需要的组件 createrepo httpd (apache2 for Debia ...
- 【C-运算符】
一.基本运算符 (1)赋值运算符:= a=2002; //将值2002赋给变量a,动作从右到左 赋值运算左边必须指向一个存储位置(变量名——指针) (2)加法.减法运算符:+.—(二元或双目运算 ...
- NFS挂载操作指南
NFS 全称 network file system,其功能是实现将某台服务器的某个目录下资源共享给其他服务器.被共享的服务器作为nfs服务端,需要开启和配置nfs server服务.共享他人资源的服 ...
- 读入一个c程序,并按字母表顺序分组打印变量名,每组前N个字符相同(TCPL 练习6-2)
在建立结构tnode的过程中,我们没有预设门槛.这道题目就设置了门槛,必须根据前N个字符来进行分组,于是排除了长度小于N的变量,以便减轻负担. 因为要求对变量名分组打印,组别理所应当地应该按照至少是升 ...
- linux-8 基本命令---date
2,date命令用于显示.设置系统的时间或日期,格式如下: date[选项][+指定格式]. date的详细格式如下: date命令格式 参数 作用 %t 跳个[tab]键 %H 小时(00-23) ...
- SQL入门经典(十) 之事务
事务是什么?事务关键在与其原子性.原子性概念是指可以把一些事情当作一个执行单元来看待.从数据库角度看待.他是指应该全部执行或者全部不执行一条或多条语句的最小组合.当处理数据时候经常确保一件事发生另一件 ...
- 使用扩展方法简化RadAjaxManager设置
相对于RadAjaxPanel,RadAjaxManager提供了更精确控制更新目标的设置,特别是在某些场景下,使用RadAjaxManager能够获得更好的性能. 但是,由于要明确设置目标,配置的代 ...
- RCP:美化基于eclipse3.7.2的RCP界面
从e4开始,eclipse rcp界面具备了深度自定义的能力. 但是在eclipse3.7.2上,几乎没有提供能够用于修改界面的外部接口. 这里介绍一种方式来自定义你自己的eclipse rcp. 先 ...
- UWP的一种下拉刷新实现
简介 我们最近实现了一个在UWP中使用的下拉刷新功能,以满足用户的需求,因为这是下拉刷新是一种常见的操作方式,而UWP本身并不提供这一机制. 通过下拉刷新这一机制,可以让移动端的界面设计变得更加简单, ...
- python的高性能web应用的开发与测试实验
python的高性能web应用的开发与测试实验 tornado“同步和异步”网络IO模型实验 引言 python语言一直以开发效率高著称,被广泛地应用于自动化领域: 测试自动化 运维自动化 构建发布自 ...