《利用python进行数据分析》读书笔记--第六章 数据加载、存储与文件格式
http://www.cnblogs.com/batteryhp/p/5021858.html
输入输出一般分为下面几类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据。利用Web API操作网络资源。
1、读写文本格式的数据
自己感觉读写文件有时候“需要运气”,经常需要手工调整。因为其简单的文件交互语法、直观的数据结构,以及诸如元组打包解包之类的便利功能,Python在文本和文件处理方面已经成为一门招人喜欢的语言。pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。见下表:
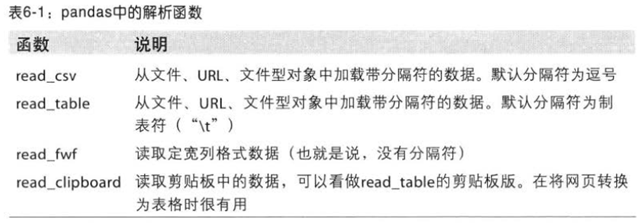
下面大致介绍一下这些函数在文本数据转换为DataFrame时的一些技术。可以分为一下几类:
- 索引:将一个或者多个列当作返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或者其他不要的东西
pandas读取文件会自动推断数据类型,不用指定。
read_csv为例
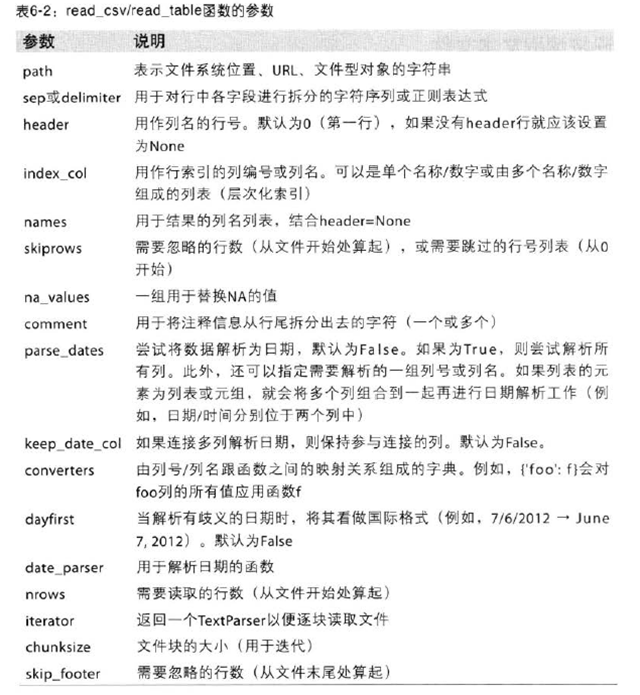
用names重新规定列名,用index_col指定索引,也可以将多个列组合作为层次化索引。可以编写正则表达式规定分隔符。用skiprows跳过某些行。pandas会用NA、-1.#IND、NULL等进行标记。用na_values用来不同的NA标记值。下面是read_csv/read_table参数:

逐块读取文本文件
处理很大的文件时,或找出大文件中的参数集以便于后续处理时,可能只想读取一部分或者逐块对文件进行迭代。nrows指定读取多少行。要逐块读取文件,需要设置chunksize(行数)。
将数据写出到文本格式
用to_csv方法写出到csv文件中。参数sep标明分隔符。na_rep标明空白字符串的代替值。index header标明是否写出行列标签,默认是写出。用cols限制并以指定顺序写出某些列。
Series也有to_csv方法。用一些整理工作(无header行,第一列作索引)就能用read_csv读取为Series,当然还有一个更方便的from_csv,Series.from_csv。
手工处理分隔符格式
有些奇葩文件需要进行处理以后再读。Python内置的csv模块可以读取任何单字符分隔符文件。将打开的文件传递给csv.reader。csv文件的形式有很多,只需定义csv.Dialect的一个子类即可定义新格式(如专门的分隔符、字符串引用约定、行结束符等):

#-*- encoding:utf-8 -*-
import numpy as np
import os
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import pandas.io.data as web
import csv f = open('ex6.csv')
reader = csv.reader(f)
for line in reader:
print line
lines = list(csv.reader(open('ex7.csv')))
header,values = lines[0],lines[1:]
print header
print values
#下面的 * 应该是取出值的意思
data_dict = {h:v for h,v in zip(header,zip(*values))}
print data_dict
class my_dialect(csv.Dialect):
lineterminator = '\n'
delimiter = ';'
quotechar = '"' reader = csv.reader(f,dialect=my_dialect)
#csv语支的参数也可以用参数的形式给出
reader = csv.reader(f,delimiter = '|')

对于那些使用复杂分隔符或多字符分隔符的文件,csv文件就无能为力了。这种情况下用split或者re.split进行拆分合整理工作。要手工输出分隔符文件,可以使用csv.writer。它接受一个已打开且可写的文件对象以及跟cav.reader相同的那些语支和格式化选项。
#-*- encoding:utf-8 -*-
import numpy as np
import os
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import pandas.io.data as web
import csv with open('mydata.csv','w') as f:
writer = csv.writer(f,lineterminator = '\n')
writer.writerow(('one','two','three'))
writer.writerow(('1','2','3'))
JSON数据
除空值null和一些其他的细微差别(如列表末尾不允许存在多余的逗号)之外,JSON非常接近有效Python代码。基本数据类型有对象(字典)、数组(列表)、字符串、数值、布尔值以及NULL。对象中所有的键都必须是字符串(非常重要)。用json模块,json.loads可以将字符串转换成Python形式,即可以将对象读取为python字典。
相反的,json.dumps可以将python对象转换为json格式。
XML和HTML:Web信息收集
lxml可以读取xml和html格式数据并处理。这部分用到的时候再研究。
2、二进制数据文件
实现数据的二进制格式最简单的方法之一是使用Python内置的pickle序列化。为了使用方便,pandas对象都有一个用于将数据以pickle形式保存到磁盘上的save方法。
#-*- encoding:utf-8 -*-
import numpy as np
import os
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import pandas.io.data as web
import csv frame = pd.read_csv('ex1.csv')
print frame
frame.save('frame_pickle') #存储为二进制文件
ok = pd.load('frame_pickle') #load函数
#ok1 = pd.read_table('frame_pickle') #不能用read_table函数
#print ok1
print ok
pickle,作者建议用作短期存储,因为会遇到解析版本问题。
使用HDF5格式
很多工具都能实现高效读写磁盘上以二进制格式存储的科学数据。HDF5就是一个流行工业级库,是一个C库,有Java、Python、MATLAB等多种接口。这部分暂时不看。
读取Excel数据
支持excel2003及更高版本的excel文件。用pandas中的ExcelFile类即可,需要安装xlrd和openpyxl包。
#-*- encoding:utf-8 -*-
import numpy as np
import os
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import pandas.io.data as web
import csv xls_file = pd.ExcelFile('ex1.xlsx')
table = xls_file.parse('ex1')
print table
使用HTML和Web API
许多网站都有一些通过JSON或其他格式提供数据的公共API。用requests包等可以实现。这部分暂时不看。
使用数据库
数据从SQL中加载到DataFrame比较简单,此外pandas还有一些能够简化该过程的函数。作者是用一款SQLite数据库,用sqlite3驱动器。作者还举了MongoDB中数据的例子。暂时不看。
《利用python进行数据分析》读书笔记--第六章 数据加载、存储与文件格式的更多相关文章
- 《利用Python进行数据分析》笔记---第6章数据加载、存储与文件格式
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 利用python进行数据分析之数据加载存储与文件格式
在开始学习之前,我们需要安装pandas模块.由于我安装的python的版本是2.7,故我们在https://pypi.python.org/pypi/pandas/0.16.2/#downloads ...
- 《利用Python进行数据分析》笔记---第5章pandas入门
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第4章NumPy基础:数组和矢量计算
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--1880-2010年间全美婴儿姓名
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--MovieLens 1M数据集
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--来自bit.ly的1.usa.gov数据
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- Knockout应用开发指南 第六章:加载或保存JSON数据
原文:Knockout应用开发指南 第六章:加载或保存JSON数据 加载或保存JSON数据 Knockout可以实现很复杂的客户端交互,但是几乎所有的web应用程序都要和服务器端交换数据(至少为了本地 ...
- 第六章:加载或保存JSON数据
加载或保存JSON数据 Knockout可以实现很复杂的客户端交互,但是几乎所有的web应用程序都要和服务器端交换数据(至少为了本地存储需要序列化数据),交换数据最方便的就是使用JSON格式 – 大多 ...
随机推荐
- java 基础二 Graphics类
一.处理图形 1.画直线 void drawLine (int startx , int starty , int endx , int endy) 参数列表:直线开始的横坐标.纵坐标,直线结束的横坐 ...
- sql存储过程中加引号
ALTER PROCEDURE [dbo].[SaveTerminaInfo] @TerminaNo NVARCHAR(50), @Name NVARCHAR(50), @Value NVARCHAR ...
- 一些NSArray,NSDictionary,NSSet相关的算法知识
iOS编程当中的几个集合类:NSArray,NSDictionary,NSSet以及对应的Mutable版本,应该所有人都用过.只是简单使用的话,相信没人会用错,但要做到高效(时间复杂度)精确(业务准 ...
- 实现一个小目标,动动小指,分享可得iphone7/ipad/U盘|奥威软件
为什么很多人喜欢冬天呢?是因为冬天有着“床边挂起长长棉袜,而你做着甜甜美梦”的平安夜?还是因为冬天有着“具有无法言述的浪漫情怀”的圣诞节? 是不是还沉浸在平安夜,圣诞节的双节狂欢中, 好像不管长到多大 ...
- 常用的WinAPI函数整理
常用的WinAPI函数整理 一.进程 创建进程: CreateProcess("C:\\windows\\notepad.exe",0,0,0,0,0,0,0,&s ...
- [总结] I/O输入,输出
I/O输入,输出第一:先判断到底是输入还是输出,站在程序的立场第二:判断是传递字节,还是字符,决定管道粗细,字节流是最基本的数据输出管道.字符类型管道专门用来传送文本数据.Java流的四大父类:1.字 ...
- 使用hbuilder编辑器实现移动app打包
作为一枚web前端来讲,需要了解的东西太多,需要学习的也太多了,那天因为公司需求,就研究了下移动网站打包成app的方法,这种东西好像是H5出来后就有推出的,因为性功能不行,就没怎么关注,但现在移动互联 ...
- SpringMVC之控制器的单例和多例管理
版权声明:本文为博主原创文章,未经博主允许不得转载. 在使用Spring3对控制器Controller进行bean管理时,如果要对控制器是否单例进行管理. 有两种方式配置多例模式: 1.springX ...
- 图片轮播器bcastr4.swf“&”符号的问题
bcastr4.swf是一个很不错的网页图片轮播器,我一直使用它作为网站首页图片轮播的控件. http://xiaogui.org/bcastr-open-source-flash-image-sil ...
- app推送中的通知和消息区别
最近在做mqtt及其他消息推送的功能,推送服务挺多的,小米推,极光推,华为推,个推等,当然还有苹果的apns.感觉都差不多,尝试了apns,小米推和个推,各个厂家都提供的有sdk,demo. 关于通知 ...