w3cschool-Apache Pig 教程
https://www.w3cschool.cn/apache_pig/
什么是Apache Pig?
Apache Pig是MapReduce的一个抽象。它是一个工具/平台,用于分析较大的数据集,并将它们表示为数据流。Pig通常与 Hadoop 一起使用;我们可以使用Apache Pig在Hadoop中执行所有的数据处理操作。
要编写数据分析程序,Pig提供了一种称为 Pig Latin 的高级语言。该语言提供了各种操作符,程序员可以利用它们开发自己的用于读取,写入和处理数据的功能。
要使用 Apache Pig 分析数据,程序员需要使用Pig Latin语言编写脚本。所有这些脚本都在内部转换为Map和Reduce任务。Apache Pig有一个名为 Pig Engine 的组件,它接受Pig Latin脚本作为输入,并将这些脚本转换为MapReduce作业。
为什么我们需要Apache Pig?
不太擅长Java的程序员通常习惯于使用Hadoop,特别是在执行任一MapReduce作业时。Apache Pig是所有这样的程序员的福音。
使用 Pig Latin ,程序员可以轻松地执行MapReduce作业,而无需在Java中键入复杂的代码。
Apache Pig使用多查询方法,从而减少代码长度。例如,需要在Java中输入200行代码(LoC)的操作在Apache Pig中输入少到10个LoC就能轻松完成。最终,Apache Pig将开发时间减少了近16倍。
Pig Latin是类似SQL的语言,当你熟悉SQL后,很容易学习Apache Pig。
Apache Pig提供了许多内置操作符来支持数据操作,如join,filter,ordering等。此外,它还提供嵌套数据类型,例如tuple(元组),bag(包)和MapReduce缺少的map(映射)。
Apache Pig的特点
Apache Pig具有以下特点:
丰富的运算符集 - 它提供了许多运算符来执行诸如join,sort,filer等操作。
易于编程 - Pig Latin与SQL类似,如果你善于使用SQL,则很容易编写Pig脚本。
优化机会 - Apache Pig中的任务自动优化其执行,因此程序员只需要关注语言的语义。
可扩展性 - 使用现有的操作符,用户可以开发自己的功能来读取、处理和写入数据。
用户定义函数 - Pig提供了在其他编程语言(如Java)中创建用户定义函数的功能,并且可以调用或嵌入到Pig脚本中。
处理各种数据 - Apache Pig分析各种数据,无论是结构化还是非结构化,它将结果存储在HDFS中。
Apache Pig与MapReduce
下面列出的是Apache Pig和MapReduce之间的主要区别。
| Apache Pig | MapReduce |
|---|---|
| Apache Pig是一种数据流语言。 | MapReduce是一种数据处理模式。 |
| 它是一种高级语言。 | MapReduce是低级和刚性的。 |
| 在Apache Pig中执行Join操作非常简单。 | 在MapReduce中执行数据集之间的Join操作是非常困难的。 |
| 任何具备SQL基础知识的新手程序员都可以方便地使用Apache Pig工作。 | 向Java公开是必须使用MapReduce。 |
| Apache Pig使用多查询方法,从而在很大程度上减少代码的长度。 | MapReduce将需要几乎20倍的行数来执行相同的任务。 |
| 没有必要编译。执行时,每个Apache Pig操作符都在内部转换为MapReduce作业。 | MapReduce作业具有很长的编译过程。 |
Apache Pig Vs SQL
下面列出了Apache Pig和SQL之间的主要区别。
| Pig | SQL |
| Pig Latin是一种程序语言。 | SQL是一种声明式语言。 |
| 在Apache Pig中,模式是可选的。我们可以存储数据而无需设计模式(值存储为$ 01,$ 02等) | 模式在SQL中是必需的。 |
| Apache Pig中的数据模型是嵌套关系。 | SQL 中使用的数据模型是平面关系。 |
| Apache Pig为查询优化提供有限的机会。 | 在SQL中有更多的机会进行查询优化。 |
除了上面的区别,Apache Pig Latin:
- 允许在pipeline(流水线)中拆分。
- 允许开发人员在pipeline中的任何位置存储数据。
- 声明执行计划。
- 提供运算符来执行ETL(Extract提取,Transform转换和Load加载)功能。
Apache Pig VS Hive
Apache Pig和Hive都用于创建MapReduce作业。在某些情况下,Hive以与Apache Pig类似的方式在HDFS上运行。在下表中,我们列出了几个重要的点区分Apache Pig与Hive。
| Apache Pig | Hive |
|---|---|
| Apache Pig使用一种名为 Pig Latin 的语言(最初创建于 Yahoo )。 | Hive使用一种名为 HiveQL 的语言(最初创建于 Facebook )。 |
| Pig Latin是一种数据流语言。 | HiveQL是一种查询处理语言。 |
| Pig Latin是一个过程语言,它适合流水线范式。 | HiveQL是一种声明性语言。 |
| Apache Pig可以处理结构化,非结构化和半结构化数据。 | Hive主要用于结构化数据。 |
Apache Pig的应用程序
Apache Pig通常被数据科学家用于执行涉及特定处理和快速原型设计的任务。使用Apache Pig:
- 处理巨大的数据源,如Web日志。
- 为搜索平台执行数据处理。
- 处理时间敏感数据的加载。
Apache Pig 架构
用于使用Pig分析Hadoop中的数据的语言称为 Pig Latin ,是一种高级数据处理语言,它提供了一组丰富的数据类型和操作符来对数据执行各种操作。
要执行特定任务时,程序员使用Pig,需要用Pig Latin语言编写Pig脚本,并使用任何执行机制(Grunt Shell,UDFs,Embedded)执行它们。执行后,这些脚本将通过应用Pig框架的一系列转换来生成所需的输出。
在内部,Apache Pig将这些脚本转换为一系列MapReduce作业,因此,它使程序员的工作变得容易。Apache Pig的架构如下所示。
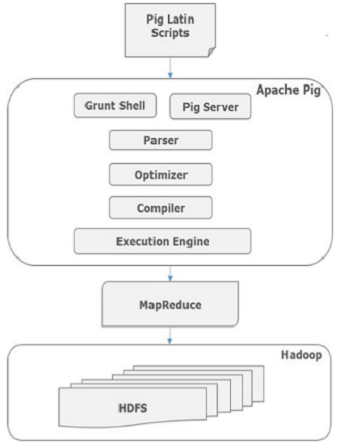
Apache Pig组件
如图所示,Apache Pig框架中有各种组件。让我们来看看主要的组件。
Parser(解析器)
最初,Pig脚本由解析器处理,它检查脚本的语法,类型检查和其他杂项检查。解析器的输出将是DAG(有向无环图),它表示Pig Latin语句和逻辑运算符。在DAG中,脚本的逻辑运算符表示为节点,数据流表示为边。
Optimizer(优化器)
逻辑计划(DAG)传递到逻辑优化器,逻辑优化器执行逻辑优化,例如投影和下推。
Compiler(编译器)
编译器将优化的逻辑计划编译为一系列MapReduce作业。
Execution engine(执行引擎)
最后,MapReduce作业以排序顺序提交到Hadoop。这些MapReduce作业在Hadoop上执行,产生所需的结果。
Pig Latin数据模型
Pig Latin的数据模型是完全嵌套的,它允许复杂的非原子数据类型,例如 map 和 tuple 。下面给出了Pig Latin数据模型的图形表示。
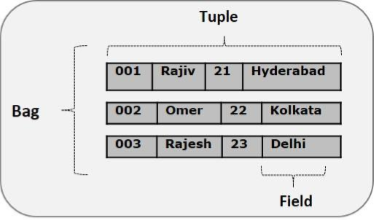
Atom(原子)
Pig Latin中的任何单个值,无论其数据类型,都称为 Atom 。它存储为字符串,可以用作字符串和数字。int,long,float,double,chararray和bytearray是Pig的原子值。一条数据或一个简单的原子值被称为字段。例:“raja“或“30"
Tuple(元组)
由有序字段集合形成的记录称为元组,字段可以是任何类型。元组与RDBMS表中的行类似。例:(Raja,30)
Bag(包)
一个包是一组无序的元组。换句话说,元组(非唯一)的集合被称为包。每个元组可以有任意数量的字段(灵活模式)。包由“{}"表示。它类似于RDBMS中的表,但是与RDBMS中的表不同,不需要每个元组包含相同数量的字段,或者相同位置(列)中的字段具有相同类型。
例:{(Raja,30),(Mohammad,45)}
包可以是关系中的字段;在这种情况下,它被称为内包(inner bag)。
例:{Raja,30, {9848022338,raja@gmail.com,} }
Map(映射)
映射(或数据映射)是一组key-value对。key需要是chararray类型,且应该是唯一的。value可以是任何类型,它由“[]"表示,
例:[name#Raja,age#30]
Relation(关系)
一个关系是一个元组的包。Pig Latin中的关系是无序的(不能保证按任何特定顺序处理元组)。
Apache Pig 执行
在上一章中,我们解释了如何安装Apache Pig。在本章中,我们将讨论如何执行Apache Pig。
Apache Pig执行模式
你可以以两种模式运行Apache Pig,即Local(本地)模式和HDFS模式。
Local模式
在此模式下,所有文件都从本地主机和本地文件系统安装和运行,不需要Hadoop或HDFS。此模式通常用于测试目的。
MapReduce模式
MapReduce模式是我们使用Apache Pig加载或处理Hadoop文件系统(HDFS)中存在的数据的地方。在这种模式下,每当我们执行Pig Latin语句来处理数据时,会在后端调用一个MapReduce作业,以对HDFS中存在的数据执行特定的操作。
Apache Pig执行机制
Apache Pig脚本可以通过三种方式执行,即交互模式,批处理模式和嵌入式模式。
交互模式(Grunt shell) - 你可以使用Grunt shell以交互模式运行Apache Pig。在此shell中,你可以输入Pig Latin语句并获取输出(使用Dump运算符)。
批处理模式(脚本) - 你可以通过将Pig Latin脚本写入具有 .pig 扩展名的单个文件中,以批处理模式运行Apache Pig。
嵌入式模式(UDF) - Apache Pig允许在Java等编程语言中定义我们自己的函数(UDF用户定义函数),并在我们的脚本中使用它们。
调用Grunt Shell
你可以使用“-x"选项以所需的模式(local/MapReduce)调用Grunt shell,如下所示。
| Local模式 | MapReduce模式 |
|---|---|
|
Command(命令) - $ ./pig -x local |
Command(命令)- $ ./pig -x mapreduce |
|
Output(输出) -
|
Output(输出)-
|
这两个命令都给出了Grunt shell提示符,如下所示。
grunt>
你可以使用“ctrl+d"退出Grunt shell。
在调用Grunt shell之后,可以通过直接输入Pig中的Pig Latin语句来执行Pig脚本。
grunt> customers = LOAD 'customers.txt' USING PigStorage(',');
在批处理模式下执行Apache Pig
你可以在文件中编写整个Pig Latin脚本,并使用 -x command 执行它。我们假设在一个名为 sample_script.pig 的文件中有一个Pig脚本,如下所示。
Sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING
PigStorage(',') as (id:int,name:chararray,city:chararray); Dump student;
现在,你可以在上面的文件中执行脚本,如下所示。
| Local模式 | MapReduce模式 |
|---|---|
| $ pig -x local Sample_script.pig | $ pig -x mapreduce Sample_script.pig |
注意:我们将详细讨论如何在批处理模式和嵌入模式中运行Pig脚本。
Pig Latin 基础
Pig Latin是用于使用Apache Pig分析Hadoop中数据的语言。在本章中,我们将讨论Pig Latin的基础知识,如Pig Latin语句,数据类型,通用运算符,关系运算符和Pig Latin UDF。
Pig Latin - 数据模型
如前面章节所讨论的,Pig的数据模型是完全嵌套的。Relation是Pig Latin数据模型的最外层结构。它是一个包其中:
- 包是元组的集合。
- 元组是有序的字段集。
- 字段是一段数据。
Pig Latin - 语句
在使用Pig Latin处理数据时,语句是基本结构。
这些语句使用关系(relation),它们包括表达式(expression)和模式(schema)。
每个语句以分号(;)结尾。
我们将使用Pig Latin提供的运算符通过语句执行各种操作。
除了LOAD和STORE,在执行所有其他操作时,Pig Latin语句采用关系作为输入,并产生另一个关系作为输出。
只要在Grunt shell中输入 Load 语句,就会执行语义检查。要查看模式的内容,需要使用 Dump 运算符。只有在执行 dump 操作后,才会执行将数据加载到文件系统的MapReduce作业。
例子
下面给出一个Pig Latin语句,它将数据加载到Apache Pig中。
grunt> Student_data = LOAD 'student_data.txt' USING PigStorage(',')as
( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Pig Latin - 数据类型
下面给出的表描述了Pig Latin数据类型。
| 序号 | 数据类型 | 说明&示例 |
|---|---|---|
| 1 | int |
表示有符号的32位整数。 示例:8 |
| 2 | long |
表示有符号的64位整数。 示例:5L |
| 3 | float |
表示有符号的32位浮点。 示例:5.5F |
| 4 | double |
表示64位浮点。 示例:10.5 |
| 5 | chararray |
表示Unicode UTF-8格式的字符数组(字符串)。 示例:‘w3cschool’ |
| 6 | Bytearray |
表示字节数组(blob)。 |
| 7 | Boolean |
表示布尔值。 示例:true / false。 |
| 8 | Datetime |
表示日期时间。 示例:1970-01-01T00:00:00.000 + 00:00 |
| 9 | Biginteger |
表示Java BigInteger。 示例:60708090709 |
| 10 | Bigdecimal |
表示Java BigDecimal 示例:185.98376256272893883 |
| 复杂类型 | ||
| 11 | Tuple |
元组是有序的字段集。 示例:(raja,30) |
| 12 | Bag |
包是元组的集合。 示例:{(raju,30),(Mohhammad,45)} |
| 13 | Map |
地图是一组键值对。 示例:['name'#'Raju','age'#30] |
Null值
所有上述数据类型的值可以为NULL。Apache Pig以与SQL类似的方式处理空值。null可以是未知值或不存在值,它用作可选值的占位符。这些空值可以自然出现或者可以是操作的结果。
Pig Latin - 算术运算符
下表描述了Pig Latin的算术运算符。假设a = 10和b = 20。
| 运算符 | 描述 | 示例 |
|---|---|---|
| + |
加 - 运算符的两侧的值相加 |
a+b将得出30 |
| − |
减 - 从运算符左边的数中减去右边的数 |
a-b将得出-10 |
| * |
乘 - 运算符两侧的值相乘 |
a*b将得出200 |
| / |
除 - 用运算符左边的数除右边的数 |
b / a将得出2 |
| % |
系数 - 用运算符右边的数除左边的数并返回余数 |
b%a将得出0 |
| ? : |
Bincond - 评估布尔运算符。它有三个操作数,如下所示。 变量 x =(expression)? value1 (如果为true): value2(如果为false)。 |
b =(a == 1)? 20:30; 如果a = 1,则b的值为20。 如果a!= 1,则b的值为30。 |
|
CASE WHEN THEN ELSE END |
Case - case运算符等效于嵌套的bincond运算符。 |
CASE f2 % 2 WHEN 0 THEN 'even' WHEN 1 THEN 'odd' END |
Pig Latin - 比较运算符
下表描述了Pig Latin的比较运算符。
| 运算符 | 描述 | 示例 |
|---|---|---|
| == |
等于 - 检查两个数的值是否相等;如果是,则条件变为true。 |
(a = b)不为true。 |
| != |
不等于 - 检查两个数的值是否相等。如果值不相等,则条件为true。 |
(a!= b)为true。 |
| > |
大于 - 检查左边数的值是否大于右边数的值。 如果是,则条件变为true。 |
(a> b)不为true。 |
| < |
小于 - 检查左边数的值是否小于右边数的值。 如果是,则条件变为true。 |
(a<b)为true。 |
| >= |
大于或等于 - 检查左边数的值是否大于或等于右边数的值。如果是,则条件变为true。 |
(a>=b)不为true。 |
| <= |
小于或等于 - 检查左边数的值是否小于或等于右边数的值。如果是,则条件变为true。 |
(a<=b)为true。 |
| matches |
模式匹配 - 检查左侧的字符串是否与右侧的常量匹配。 |
f1 matches '.* tutorial.*' |
Pig Latin - 类型结构运算符
下表描述了Pig Latin的类型结构运算符。
| 运算符 | 描述 | 示例 |
|---|---|---|
| () |
元组构造函数运算符 - 此运算符用于构建元组。 |
(Raju,30) |
| {} |
包构造函数运算符 - 此运算符用于构造包。 |
{(Raju,30),(Mohammad,45)} |
| [] |
映射构造函数运算符 - 此运算符用于构造一个映射。 |
[name#Raja,age#30] |
Pig Latin - 关系运算符
下表描述了Pig Latin的关系运算符。
| 运算符 | 描述 |
|---|---|
| 加载和存储 | |
| LOAD | 将数据从文件系统(local/ HDFS)加载到关系中。 |
| STORE | 将数据从文件系统(local/ HDFS)存储到关系中。 |
| 过滤 | |
| FILTER | 从关系中删除不需要的行。 |
| DISTINCT | 从关系中删除重复行。 |
| FOREACH,GENERATE | 基于数据列生成数据转换。 |
| STREAM | 使用外部程序转换关系。 |
| 分组和连接 | |
| JOIN | 连接两个或多个关系。 |
| COGROUP | 将数据分组为两个或多个关系。 |
| GROUP | 在单个关系中对数据进行分组。 |
| CROSS | 创建两个或多个关系的向量积。 |
| 排序 | |
| ORDER | 基于一个或多个字段(升序或降序)按排序排列关系。 |
| LIMIT | 从关系中获取有限数量的元组。 |
| 合并和拆分 | |
| UNION | 将两个或多个关系合并为单个关系。 |
| SPLIT | 将单个关系拆分为两个或多个关系。 |
| 诊断运算符 | |
| DUMP | 在控制台上打印关系的内容。 |
| DESCRIBE | 描述关系的模式。 |
| EXPLAIN | 查看逻辑,物理或MapReduce执行计划以计算关系。 |
| ILLUSTRATE | 查看一系列语句的分步执行。 |
w3cschool-Apache Pig 教程的更多相关文章
- Apache Pig中文教程集合
Apache Pig中文教程集合: http://www.codelast.com/?p=4550#more-4550
- Windows OS上安装运行Apache Kafka教程
Windows OS上安装运行Apache Kafka教程 下面是分步指南,教你如何在Windows OS上安装运行Apache Zookeeper和Apache Kafka. 简介 本文讲述了如何在 ...
- Apache Pig处理数据示例
Apache Pig是一个高级过程语言,可以调用MapReduce查询大规模的半结构化数据集. 样例执行的环境为cloudera的单节点虚拟机 读取结构数据中的指定列 在hdfs上放置一个文件 [cl ...
- Apache Flink教程
1.Apache Flink 教程 http://mp.weixin.qq.com/mp/homepage?__biz=MzIxMTE0ODU5NQ==&hid=5&sn=ff5718 ...
- Ubuntu 搭建Web服务器(MySQL+PHP+Apache)详细教程
Ubuntu 搭建Web服务器(MySQL+PHP+Apache)详细教程 看了好多人的博客,有的不全 or 有问题,整理了一下,适合小白 新手先整理几个小问题 1.为啥使用 Linux 搭建服务器? ...
- Centos6.7 安装zabbix+apache+mysql教程(第一篇)
Centos6.7 安装zabbix+apache+mysql教程 blog地址: http://www.cnblogs.com/caoguo ### 基本包安装 ### [root@ca0gu0 ~ ...
- Apache Shiro教程
跟开涛学系列: 来自开涛的Apache Shiro教程:http://jinnianshilongnian.iteye.com/blog/2018398 附带的代码例子:https://github. ...
- Apache Kafka教程
1.卡夫卡教程 今天,我们正在使用Apache Kafka Tutorial开始我们的新旅程.在这个Kafka教程中,我们将看到什么是Kafka,Apache Kafka历史以及Kafka的原因.此外 ...
- Java之Apache Tomcat教程[归档]
前言 笔记归档类博文. 本博文地址:Java之Apache Tomcat教程[归档] 未经同意或授权便复制粘贴全文原文!!!!盗文实在可耻!!!贴一个臭不要脸的:易学教程↓↓↓ Step1:安装JDK ...
- 玩转大数据系列之Apache Pig高级技能之函数编程(六)
原创不易,转载请务必注明,原创地址,谢谢配合! http://qindongliang.iteye.com/ Pig系列的学习文档,希望对大家有用,感谢关注散仙! Apache Pig的前世今生 Ap ...
随机推荐
- 多校A层冲刺NOIP2024模拟赛18
多校A层冲刺NOIP2024模拟赛18 T1 选彩笔(rgb) 签到题,但是没签上... 没想到三维前缀和,直接上了个bitset. 就是直接二分答案,然后枚举这三维每维的区间的起点,前缀和查数量是否 ...
- Flink 实战之 Real-Time DateHistogram
系列文章 Flink 实战之 Real-Time DateHistogram Flink 实战之从 Kafka 到 ES DateHistogram 用于根据日期或时间数据进行分桶聚合统计.它允许你将 ...
- 用 300 行代码手写提炼 Spring 核心原理 [3]
系列文章 用 300 行代码手写提炼 Spring 核心原理 [1] 用 300 行代码手写提炼 Spring 核心原理 [2] 用 300 行代码手写提炼 Spring 核心原理 [3] 上文 中我 ...
- 鸿蒙NEXT开发案例:随机数生成
[引言] 本项目是一个简单的随机数生成器应用,用户可以通过设置随机数的范围和个数,并选择是否允许生成重复的随机数,来生成所需的随机数列表.生成的结果可以通过点击"复制"按钮复制到剪 ...
- 拯救php性能的神器webman-打包二进制
看了看webman的官方文档,发现居然还能打包为二进制,这样太厉害了吧! 先执行这个 composer require webman/console ^1.2.24 安装这个console的包,然后 ...
- java中并发包简要分析01
参考<分布式java应用>一书,简单过一遍并发包(java.util.concurrent) ConcurrentHashMap ConcurrentHashMap是线程安全的HashMa ...
- Codeforces Round 890 (Div. 2)
Tales of a Sort 题解 找到最大的能够产生逆序对的数即可 暴力\(O(n^2)\)枚举即可 const int N = 2e5 + 10, M = 4e5 + 10; int n; in ...
- 【3分钟学会】一招禁用表单中input输入框回车键自动触发提交事件!
知其然知其所以然 在前端项目开发中,偶尔会有表单提交的问题: 用户输入表单后,不小心按了回车键,导致提前触发了提交事件? 问题概述 当表单中仅有一个input输入框时,按下回车键就会自动触发提交事件, ...
- c#之示波器功能
c#上位机:示波器功能 好久没有更新了,因为最近主要学习了如何用c#去做一个示波器功能,这里的示波器主要是用于单片机的调试.下面,我主要分享一下我做示波器的一些心得: 我这里示波器是用winform做 ...
- IOS快捷指令代码分享
IOS快捷指令分享 制作快捷指令 首先在快捷指令APP上制作快捷指令 添加一些逻辑,具体可以自己体验 然后点击共享,获取iCloud链接 类似于这种 https://www.icloud.com/sh ...