Spark知识点汇总
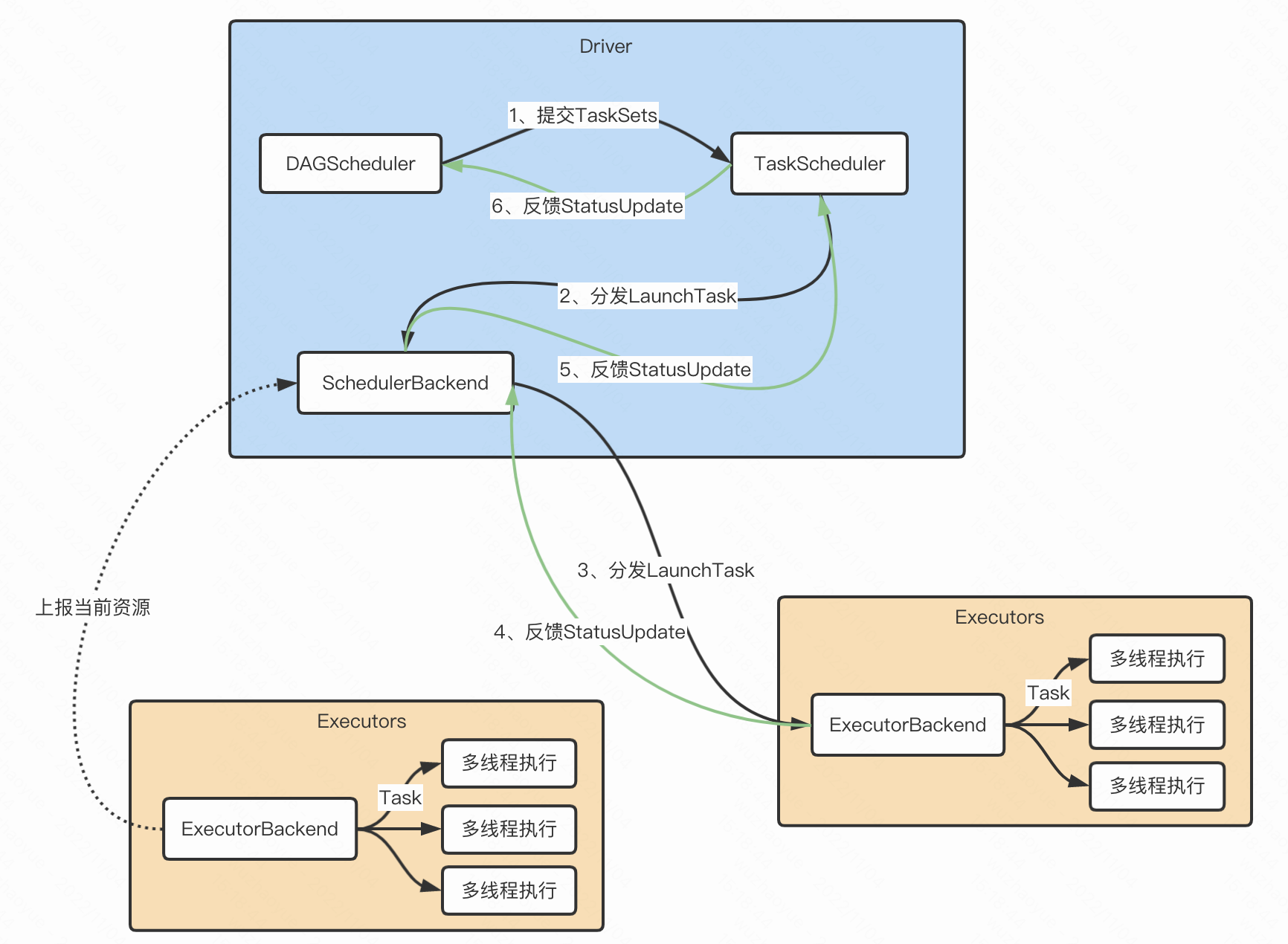
一、Spark架构设计
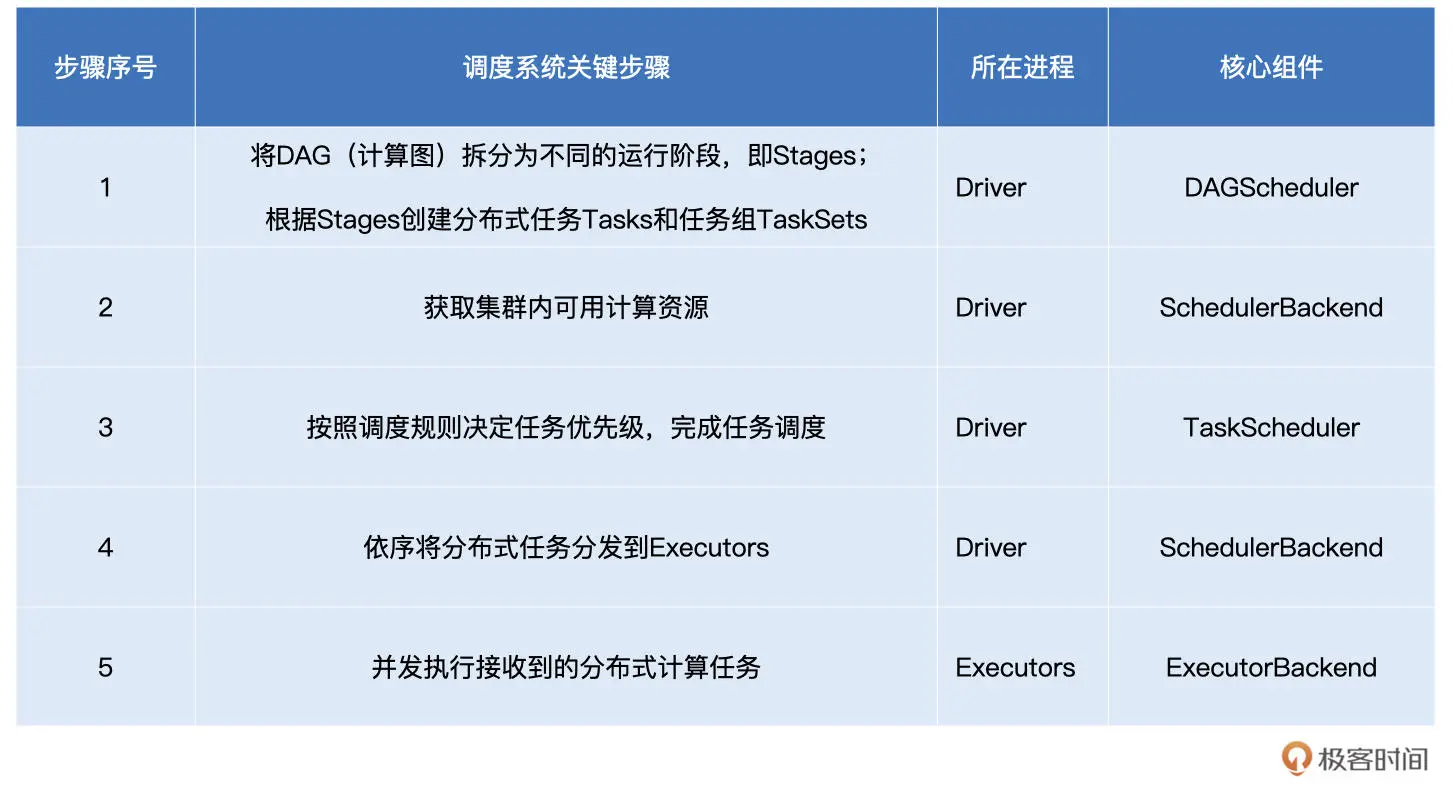
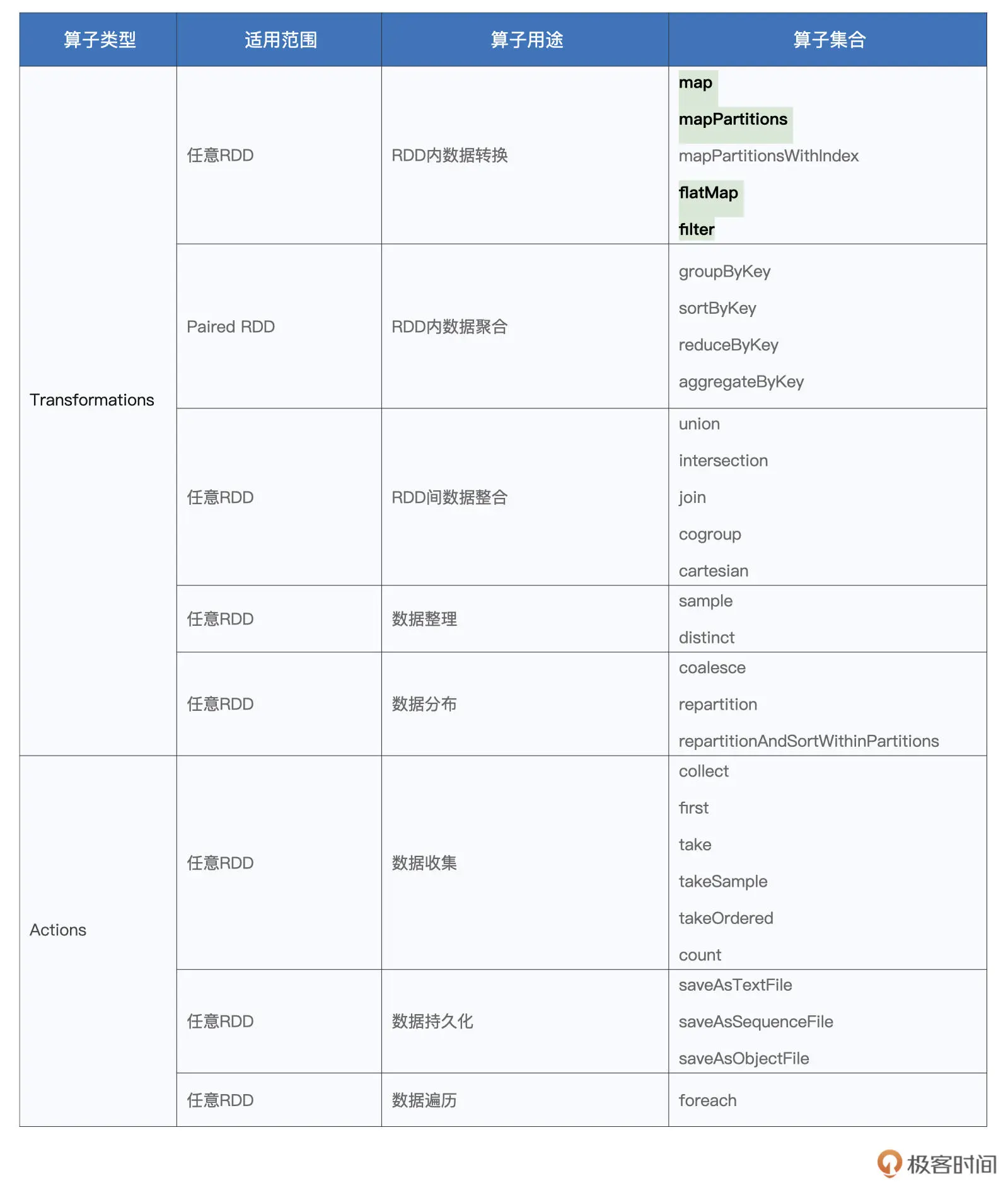
二、Spark常用算子
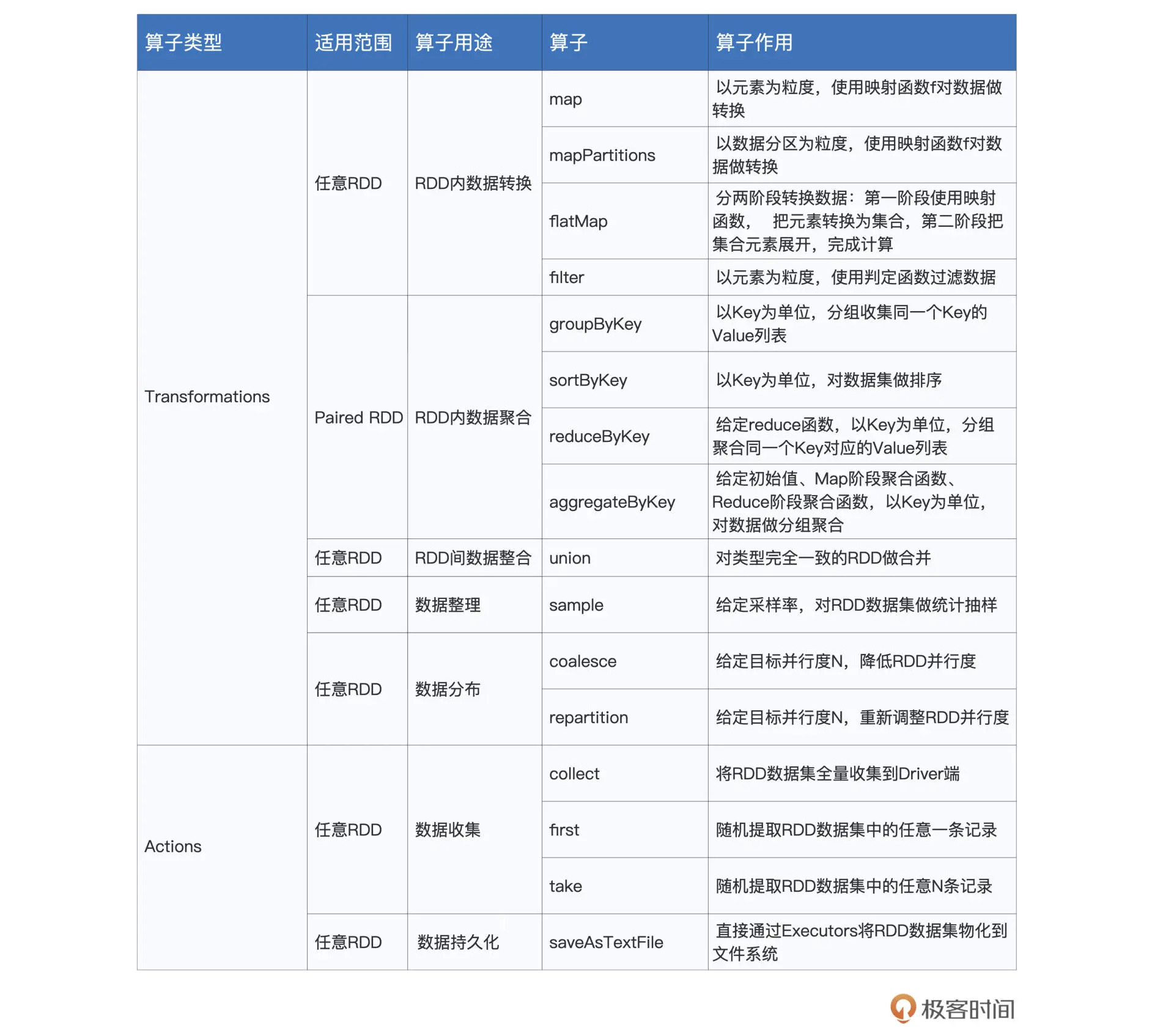
tips1: 数据处理的生命周期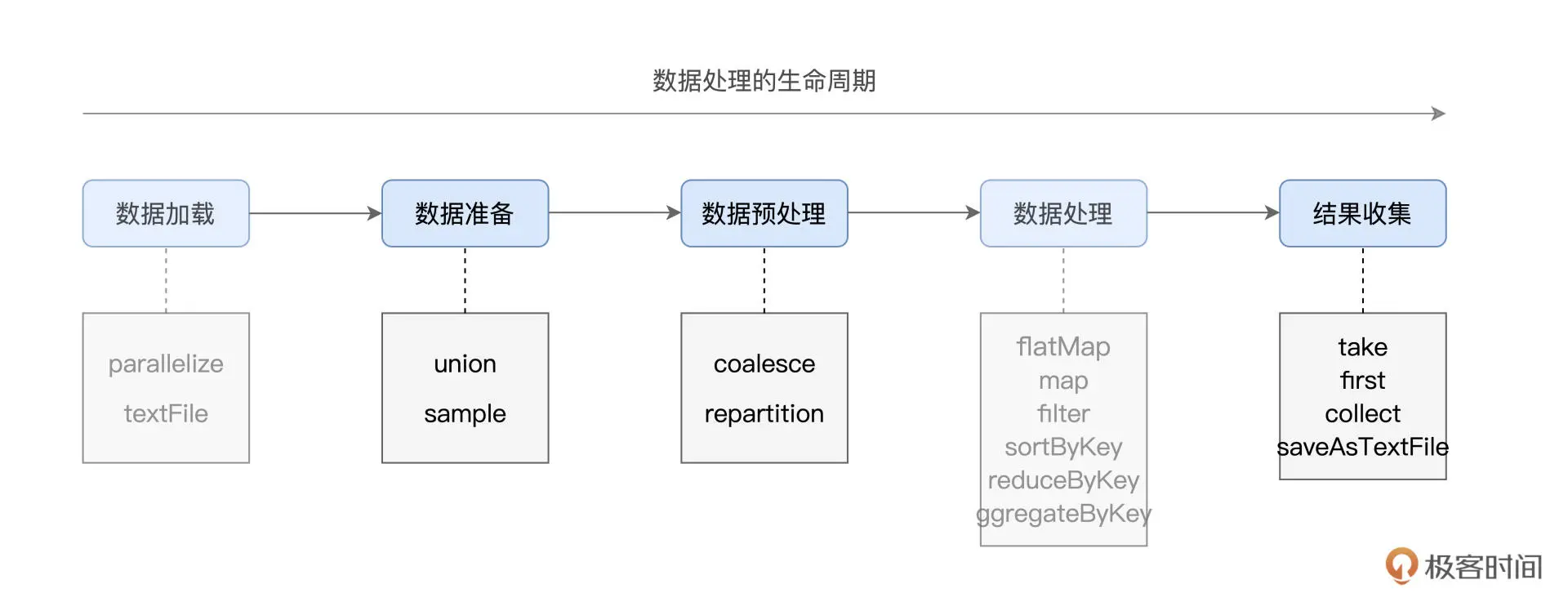
tips2: repartition vs coalesce区别:
- 可以使用 repartition 算子随意调整(提升或降低)RDD 的并行度,而 coalesce 算子则只能用于降低 RDD 并行度
- repartitionrepartition的计算过程都是先哈希、再取模,得到的结果便是该条数据的目标分区索引。对于绝大多数的数据记录,目标分区往往坐落在另一个 Executor、甚至是另一个节点之上,所以避免不了shuffle
- coalesce在降低并行度的计算中,它采取的思路是把同一个 Executor 内的不同数据分区进行合并(只会在当前进程内进行数据合并),不会存在shuffle
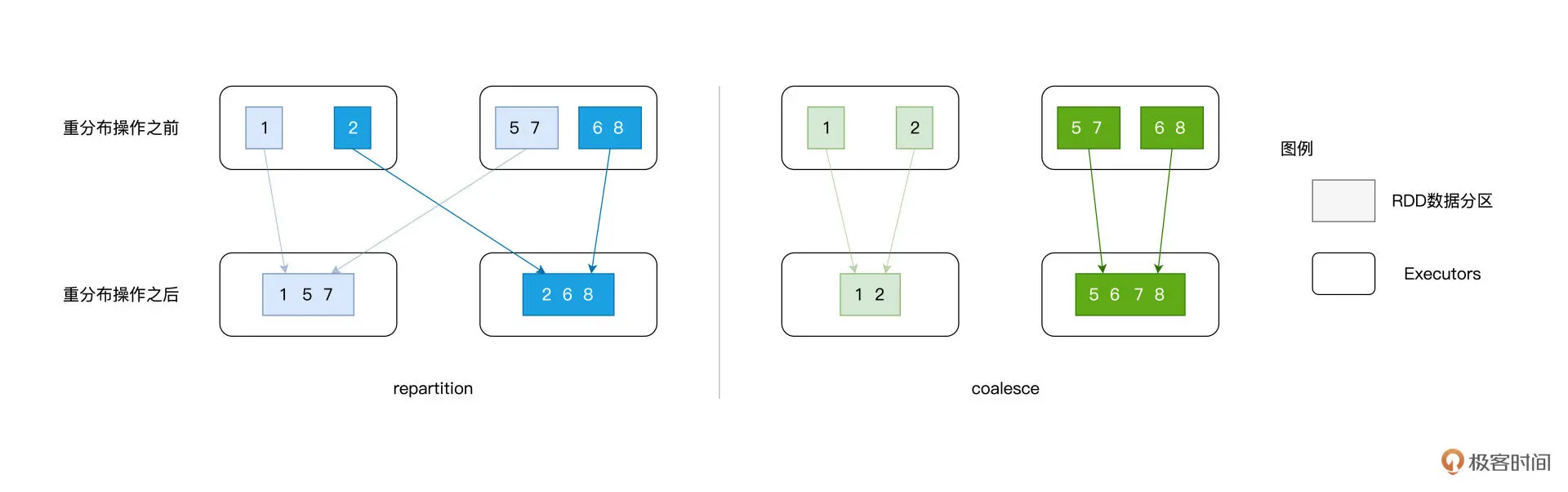
参考:https://time.geekbang.org/column/article/423131
三、Shuffle机制
Shuffle 的本意是扑克的“洗牌”,在分布式计算场景中,它被引申为集群范围内跨节点、跨进程的数据分发
Map 阶段与 Reduce 阶段,通过生产与消费 Shuffle 中间文件的方式,来完成集群范围内的数据交换。换句话说,Map 阶段生产 Shuffle 中间文件,Reduce 阶段消费 Shuffle 中间文件,二者以中间文件为媒介,完成数据交换
在 Map 执行阶段,每个Map Task都会生成包含 data 文件与 index 文件的 Shuffle 中间文件。Shuffle 文件的生成,是以 Map Task 为粒度的,Map 阶段有多少个 Map Task,就会生成多少份(注意:这里是份,不是个) Shuffle 中间文件
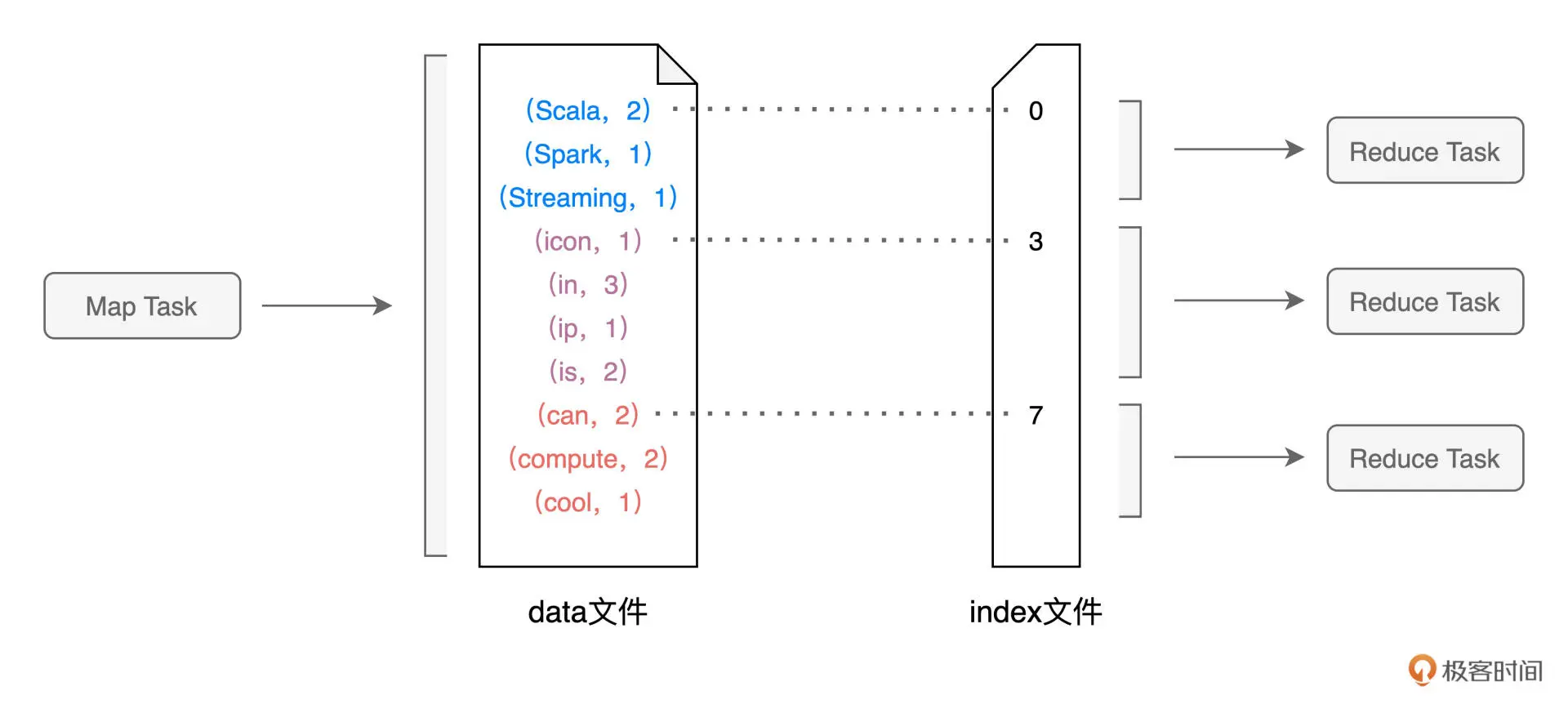
Shuffle Write:在生成中间文件的过程中,Spark 会借助一种类似于 Map 的数据结构,来计算、缓存并排序数据分区中的数据记录。Spark 读取分区内容并向 Map 结构中插入数据,直到 Map 结构被灌满而溢出,如此往复,直到数据分区中所有的数据记录都被处理完毕。对所有临时文件和内存数据结构中剩余的数据记录做归并排序,生成数据文件和索引文件
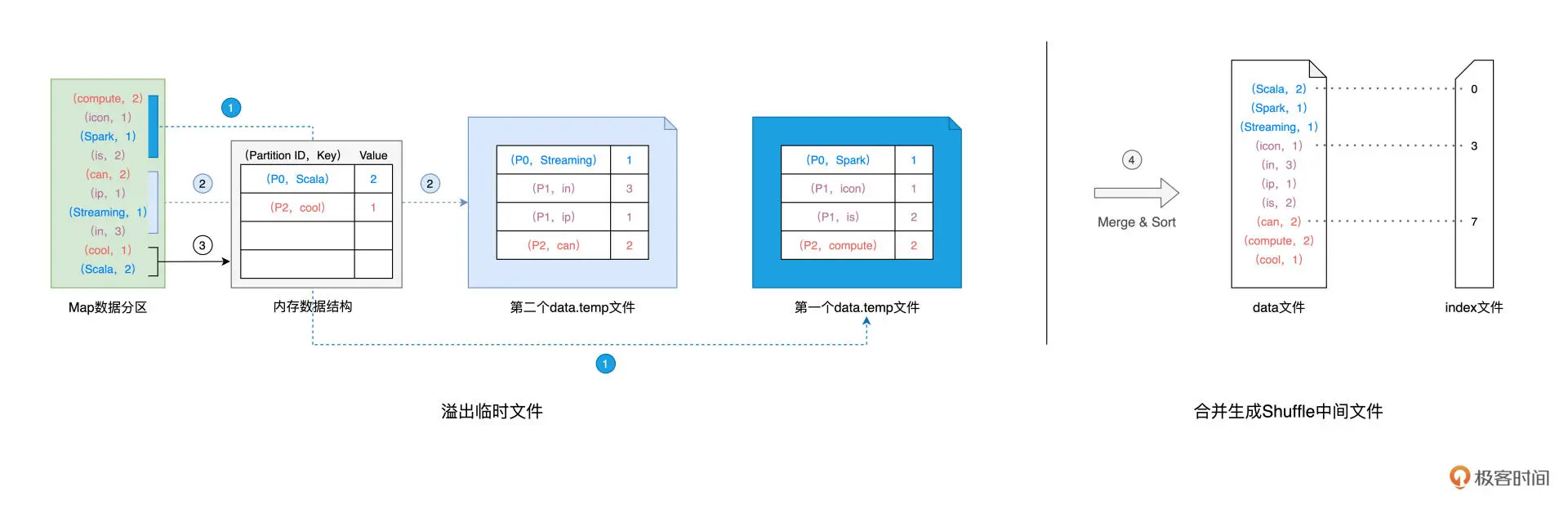
Shuffle Read:对于所有 Map Task 生成的中间文件,Reduce Task 需要通过网络从不同节点的硬盘中下载并拉取属于自己的数据内容。不同的 Reduce Task 正是根据 index 文件中的起始索引来确定哪些数据内容是“属于自己的”。
分区计算公式:P = Hash(Record Key) % N;N是reduce task数量,P是reduce task的分区编号,每个reduce task根据各自的分区编号拉取中间文件
问:假设5个map task,3个reduce task,会生成多少个中间文件?
答:每个map task根据Hash(Record Key)) % 3,生成3个中间文件,共5个map task,最多生成15个中间文件
参考:https://time.geekbang.org/column/article/420399
四、Spark运行时-内存管理及分配
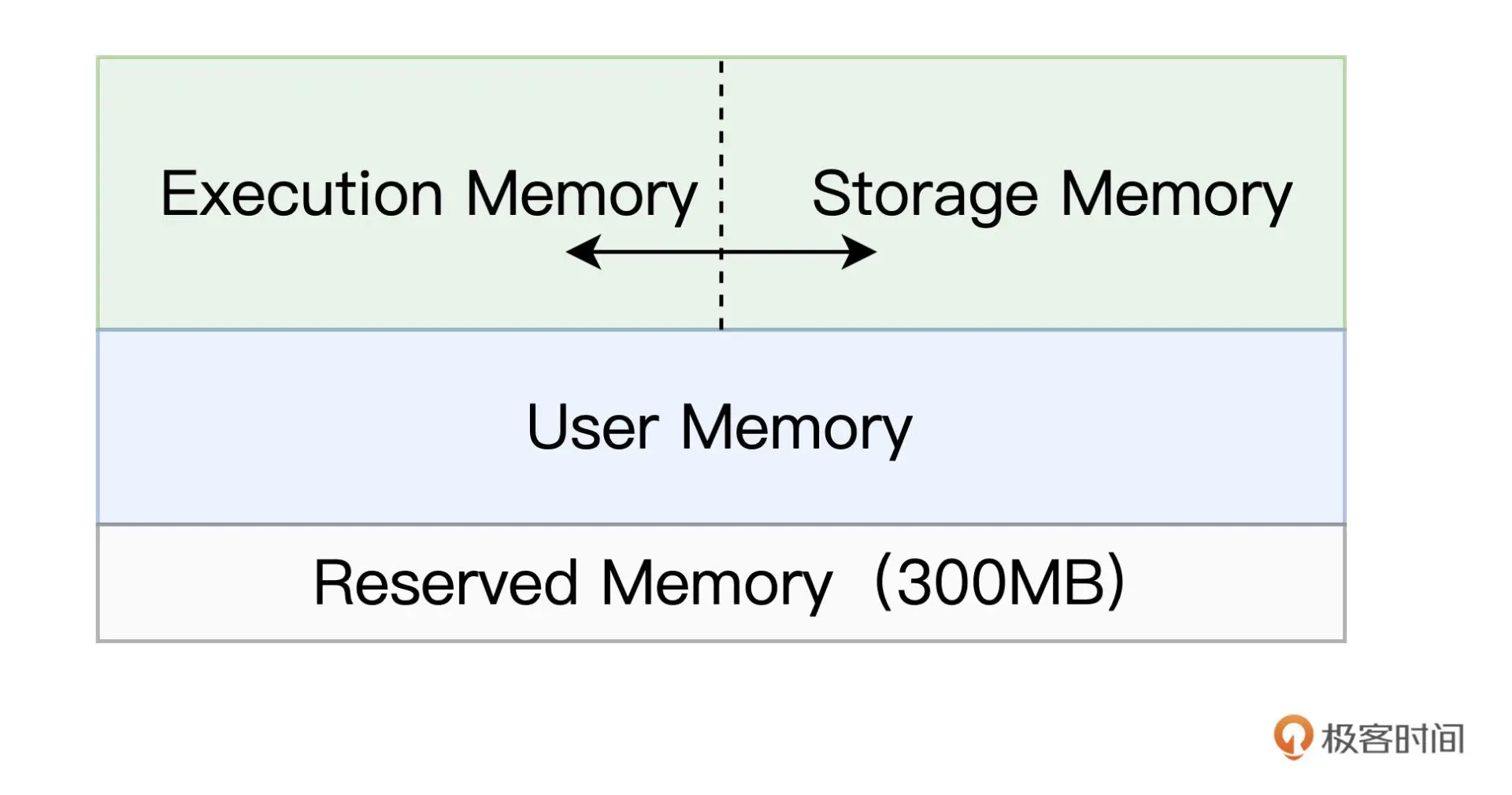
Reserved Memory:固定为 300MB,不受开发者控制,它是 Spark 预留的、用来存储各种 Spark 内部对象的内存区域
User Memory:用于存储开发者自定义的数据结构,例如 RDD 算子中引用的数组、列表、映射等等
Execution Memory:用来执行分布式任务。分布式任务的计算,主要包括数据的转换、过滤、映射、排序、聚合、归并等环节,而这些计算环节的内存消耗,统统来自于 Execution Memory
Storage Memory:用于缓存分布式数据集,比如 RDD Cache、广播变量等等。RDD Cache 指的是 RDD 物化到内存中的副本。在一个较长的 DAG 中,如果同一个 RDD 被引用多次,那么把这个 RDD 缓存到内存中,往往会大幅提升作业的执行性能
在 1.6 版本之后,Spark 推出了统一内存管理模式,在这种模式下,Execution Memory 和 Storage Memory 之间可以相互转化
- 如果对方的内存空间有空闲,双方可以互相抢占;
- 对于 Storage Memory 抢占的 Execution Memory 部分,当分布式任务有计算需要时,Storage Memory 必须立即归还抢占的内存,涉及的缓存数据要么落盘、要么清除;
- 对于 Execution Memory 抢占的 Storage Memory 部分,即便 Storage Memory 有收回内存的需要,也必须要等到分布式任务执行完毕才能释放。
RDD Cache使用
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
wordCounts.cache // 使用cache算子告知Spark对wordCounts加缓存
wordCounts.count // 触发wordCounts的计算,并将wordCounts缓存到内存
// wordCounts.persist(MEMORY_ONLY) // 或者这样写,比较推荐
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
// 将分组计数结果落盘到文件
val targetPath: String = _
wordCounts.saveAsTextFile(targetPath)
参考:https://time.geekbang.org/column/article/422400
五、Spark运行时-数据存储与管理
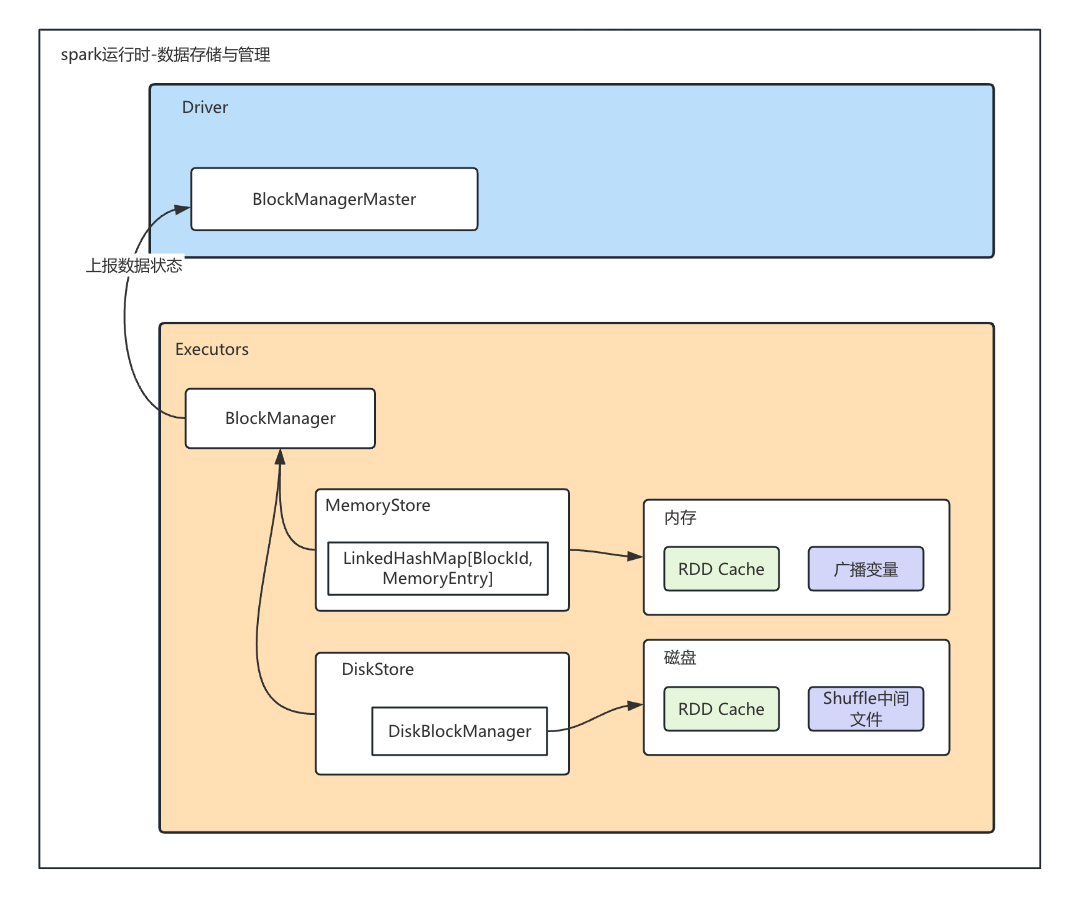
BlockManagerMaster负责与BlockManager交互,获取每个节点的数据信息
BlockManager 通过 MemoryStore 来完成内存的数据存取。MemoryStore 通过一种特殊的数据结构:LinkedHashMap 来完成 BlockId 到 MemoryEntry 的映射。其中,BlockId 记录着数据块的元数据,而 MemoryEntry 则用于封装数据实体
BlockManager 通过 DiskStore 来实现磁盘数据的存取与访问。DiskStore 并不直接维护元数据列表,而是通过 DiskBlockManager 这个对象,来完成从数据库到磁盘文件的映射,进而完成数据访问
参考:https://time.geekbang.org/column/article/424203
Spark知识点汇总的更多相关文章
- nginx几个知识点汇总
WHY? 为什么用Nginx而不用LVS? 7点理由足以说明一切:1 .高并发连接: 官方测试能够支撑 5 万并发连接,在实际生产环境中跑到 2 - 3 万并发连接数.?2 .内存消耗少: 在 3 万 ...
- python全栈开发 * 10知识点汇总 * 180612
10 函数进阶 知识点汇总 一.动态参数 形参的第三种1.动态接收位置传参 表达:*args (在参数位置编写 * 表⽰接收任意内容) (1)动态位置参数def eat(*args): print(a ...
- 清华大学OS操作系统实验lab1练习知识点汇总
lab1知识点汇总 还是有很多问题,但是我觉得我需要在查看更多资料后回来再理解,学这个也学了一周了,看了大量的资料...还是它们自己的80386手册和lab的指导手册觉得最准确,现在我就把这部分知识做 ...
- c++ 函数知识点汇总
c++ 函数知识点汇总 swap函数 交换两个数组元素 比如 swap(a[i],a[j]); 就是交换a[i] 和 a[j] 的值 strcpy() 复制一个数组元素的值到另一个数组元素里 strc ...
- 前端开发 JavaScript 干货知识点汇总
很多初学的朋友经常问我,前端JavaScript都需要学习哪些东西呀?哪些是JavaScript的重点知识啊? 其实做前端开发工程师,所有的知识点都是我们学习必备的东西,只有扎实的技术基础才是高薪的关 ...
- BBS项目知识点汇总
目录 bbs项目知识点汇总 一. JavaScript 1 替换头像 2 form表单拿数据 3 form组件error信息渲染 4 添加html代码 5 聚焦操作 二 . html在线编辑器 三 . ...
- Java面试知识点汇总
Java面试知识点汇总 置顶 2019年05月07日 15:36:18 温柔的谢世杰 阅读数 21623 文章标签: 面经java 更多 分类专栏: java 面试 Java面试知识汇总 版权声明 ...
- 离散数学 II(最全面的知识点汇总)
离散数学 II(知识点汇总) 目录 离散数学 II(知识点汇总) 代数系统 代数系统定义 例子 二元运算定义 运算及其性质 二元运算的性质 封闭性 可交换性 可结合性 可分配性 吸收律 等幂性 消去律 ...
- ECMAScript版本知识点汇总
ECMAScript版本知识点汇总 ES5 btoa.atob 对参数进行base64格式编码.解码 /** * btoa() * base64编码 * @param {string} str * @ ...
- c++常考算法知识点汇总
前言:写这篇博客完全是给自己当做笔记用的,考虑到自己的c++基础不是很踏实,只在大一学了一学期,c++的面向对象等更深的知识也一直没去学.就是想当遇到一些比较小的知识,切不值得用一整篇 博客去记述的时 ...
随机推荐
- 卸载重装vscode
最近工作需要长期用到python,但我的老电脑又实在拉不起pycharm那配置,干脆就用vscode了,但本来我的vscode是用来写c/c++的,安装配置一通乱搞,现在也不知道怎么配置回来了. 干脆 ...
- Google发布A2A开源协议:“MCP+A2A”成未来标配?
就在刚刚Google Cloud Next 25大会上,谷歌重磅开源Agent2Agent(A2A)协议,这项被类比为"AI界的HTTP协议"的技术标准,彻底打破了智能体间的信息孤 ...
- 【docker】4种网络模式
bridge模式 使用--net=bridge指定,Docker的默认设置,这种模式创建出来的docker容器链接到Dcoker网桥上(docker0网桥或者其它自定义的网桥): 1)创建一对虚拟网卡 ...
- 凯亚IOT平台在线测试MQTT接入设备
一.概述 凯亚 (Kayak)开通了MQTT端口425,以便给感兴趣的同僚进行测试,下面将在此篇文章讲解如何平台接入设备进行MQTT通信 凯亚 (Kayak) 是什么? 凯亚(Kayak)是基于.NE ...
- Java三大特性 封装、继承、多态
封装 概念: 封装指的是将类的某些信息隐藏在类内部,不允许外部程序直接访问,只能通过该类提供的方法来实现对隐藏信息的操作和访问. 封装实现的步骤: 1.修改属性的可见性来显示属性的访问,一般设为pri ...
- GUI development with Rust and GTK4 阅读笔记
简记 这是我第二次从头开始阅读,有第一次的印象要容易不少. 如果只关心具体的做法,而不思考为什么这样做,以及整体的框架,阅读的过程将会举步维艰. 简略记录 gtk-rs 的书中提到的点.对同一个问题书 ...
- 【工具】Vscode插件推荐(不用谷歌api、支持短句英汉互译、支持查词、支持自动补全、不需要浏览器)
需求: 1)偶尔需要查英文生词: 2)有时候想不起来中文对应的英文: 3)不想回到浏览器打开一堆网页: 4)谷歌翻译挂了. 偶尔需要的需求: 1)短句翻译. 因为谷歌翻译挂了,首先,排除最热门的翻译插 ...
- Linux命令之剪切
一.格式 mv source dest 二.介绍 mv: 命令 source: 源文件 dest: 目的地址 三.案例 剪切conf 文件到 /home/data 文件下 目前conf 文件是在/h ...
- vue3 基础-具名插槽 & 作用域插槽
上篇对 slot 的基本概念和使用有一个初步的认识, 即通过 slot 的这种设计, 父组件可以在调用子组件的时候, 给组件之间传递一波 dom, 子组件通过 slot 标签来进行接收. slot 默 ...
- Alexander ——2024年报
Alexander --2024年报 小总结 知己知彼,百战不殆.2024下半年找到了自己学习的方向,也认识很多的师傅,深入领域学习,无时不刻不在CTF的路上,逐渐建立一个完整的知识库体系. 今年的成 ...