vivo Pulsar 万亿级消息处理实践(2)-从0到1建设 Pulsar 指标监控链路
作者:vivo 互联网大数据团队- You Shuo
本文是《vivo Pulsar万亿级消息处理实践》系列文章第2篇,Pulsar支持上报分区粒度指标,Kafka则没有分区粒度的指标,所以Pulsar的指标量级要远大于Kafka。在Pulsar平台建设初期,提供一个稳定、低时延的监控链路尤为重要。
系列文章:
本文是基于Pulsar 2.9.2/kop-2.9.2展开的。
一、背景
作为一种新型消息中间件,Pulsar在架构设计及功能特性等方面要优于Kafka,所以我们引入Pulsar作为我们新一代的消息中间件。在对Pulsar进行调研的时候(比如:性能测试、故障测试等),针对Pulsar提供一套可观测系统是必不可少的。Pulsar的指标是面向云原生的,并且官方提供了Prometheus作为Pulsar指标的采集、存储和查询的方案,但是使用Prometheus采集指标面临以下几个问题:
Prometheus自带的时序数据库不是分布式的,它受单机资源的限制;
Prometheus 在存储时序数据时消耗大量的内存,并且Prometheus在实现高效查询和聚合计算的时候会消耗大量的CPU。
除了以上列出的可观测系统问题,Pulsar还有一些指标本身的问题,这些问题包括:
Pulsar的订阅积压指标单位是entry而不是条数,这会严重影响从Kafka迁移过来的用户的使用体验及日常运维工作;
Pulsar没有bundle指标,因为Pulsar自动均衡的最小单位是bundle,所以bundle指标是调试Pulsar自动均衡参数时重要的观测依据;
kop指标上报异常等问题。
针对以上列出的几个问题,我们在下面分别展开叙述。
二、Pulsar监控告警系统架构
在上一章节我们列出了使用Prometheus作为观测系统的局限,由于Pulsar的指标是面向云原生的,采用Prometheus采集Pulsar指标是最好的选择,但对于指标的存储和查询我们使用第三方存储来减轻Prometheus的压力,整个监控告警系统架构如下图所示:
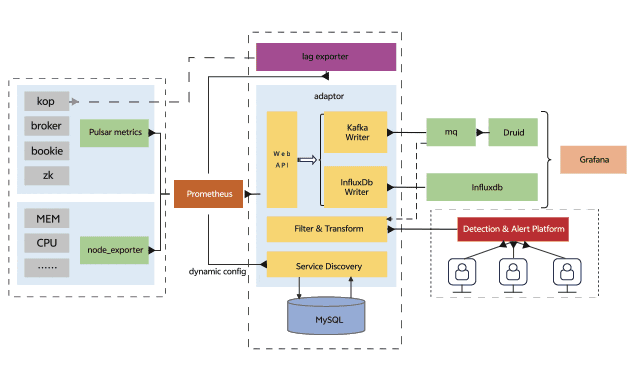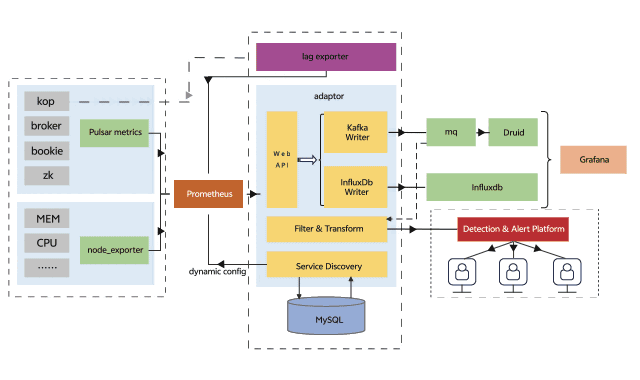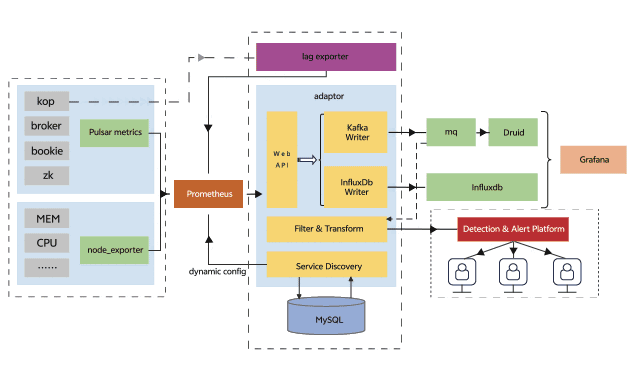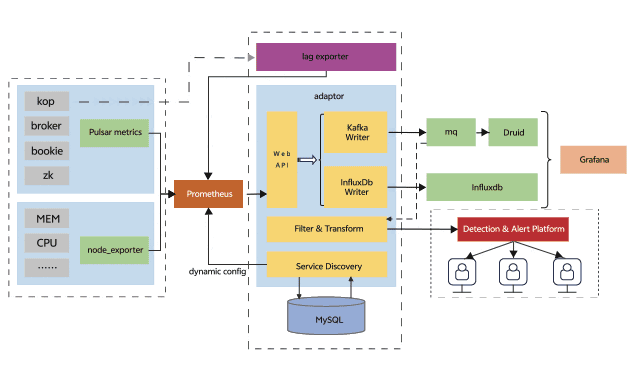
在整个可观测系统中,各组件的职能如下:
Pulsar、bookkeeper等组件提供暴露指标的接口
Prometheus访问Pulsar指标接口采集指标
adaptor提供了服务发现、Prometheus格式指标的反序列化和序列化以及指标转发远端存储的能力,这里的远端存储可以是Pulsar或Kafka
Druid消费指标topic并提供数据分析的能力
vivo内部的检测告警平台提供了动态配置检测告警的能力
基于以上监控系统的设计逻辑,我们在具体实现的过程中遇到了几个比较关键的问题:
一、adaptor需要接收Pulsar所有线上服务的指标并兼容Prometheus格式数据,所以在调研Prometheus采集Pulsar指标时,我们基于Prometheus的官方文档开发了adaptor,在adaptor里实现了服务加入集群的发现机制以及动态配置prometheus采集新新加入服务的指标:
Prometheus动态加载配置:Prometheus配置-官方文档
Prometheus自定义服务发现机制:Prometheus自定义服务发现-官方文档
在可以动态配置Prometheus采集所有线上正在运行的服务指标之后,由于Prometheus的指标是基于protobuf协议进行传输的,并且Prometheus是基于go编写的,所以为了适配Java版本的adaptor,我们基于Prometheus和go提供的指标格式定义文件(remote.proto、types.proto和gogo.proto)生成了Java版本的指标接收代码,并将protobuf格式的指标反序列化后写入消息中间件。
二、Grafana社区提供的Druid插件不能很好的展示Counter类型的指标,但是bookkeeper上报的指标中又有很多是Counter类型的指标,vivo的Druid团队对该插件做了一些改造,新增了计算速率的聚合函数。
druid插件的安装可以参考官方文档(详情)
三、由于Prometheus比较依赖内存和CPU,而我们的机器资源组又是有限的,在使用远端存储的基础上,我们针对该问题优化了一些Prometheus参数,这些参数包括:
--storage.tsdb.retention=30m:该参数配置了数据的保留时间为30分钟,在这个时间之后,旧的数据将会被删除。
--storage.tsdb.min-block-duration=5m:该参数配置了生成块(block)的最小时间间隔为5分钟。块是一组时序数据的集合,它们通常被一起压缩和存储在磁盘上,该参数间接控制Prometheus对内存的占用。
--storage.tsdb.max-block-duration=5m:该参数配置了生成块(block)的最大时间间隔为5分钟。如果一个块的时间跨度超过这个参数所设的时间跨度,则这个块将被分成多个子块。
--enable-feature=memory-snapshot-on-shutdown:该参数配置了在Prometheus关闭时,自动将当前内存中的数据快照写入到磁盘中,Prometheus在下次启动时读取该快照从而可以更快的完成启动。
三、Pulsar 指标优化
Pulsar的指标可以成功观测之后,我们在日常的调优和运维过程中发现了一些Pulsar指标本身存在的问题,这些问题包括准确性、用户体验、以及性能调优等方面,我们针对这些问题做了一些优化和改造,使得Pulsar更加通用、易维护。
3.1 Pulsar消费积压指标
原生的Pulsar订阅积压指标单位是entry,从Kafka迁移到Pulsar的用户希望Pulsar能够和Kafka一样,提供以消息条数为单位的积压指标,这样可以方便用户判断具体的延迟大小并尽量不改变用户使用消息中间件的习惯。
在确保配置brokerEntryMetadataInterceptors=
org.apache.pulsar.common.intercept.AppendIndexMetadataInterceptor情况下,Pulsar broker端在往bookkeeper端写入entry前,通过拦截器往entry的头部添加索引元数据,该索引在同一分区内单调递增,entry头部元数据示例如下:
biz-log-partition-1 -l 24622961 -e 6
Batch Message ID: 24622961:6:0
Publish time: 1676917007607
Event time: 0
Broker entry metadata index: 157398560244
Properties:
"X-Pulsar-batch-size 2431"
"X-Pulsar-num-batch-message 50"
以分区为指标统计的最小单位,基于last add confirmed entry和last consumed entry计算两个entry中的索引差值,即是订阅在每个分区的数据积压。下面是cursor基于订阅位置计算订阅积压的示意图,其中last add confirmed entry在拦截器中有记录最新索引,对于last consumed entry,cursor需要从bookkeeper中读取,这个操作可能会涉及到bookkeeper读盘,所以在收集延迟指标的时候可能会增加采集的耗时。
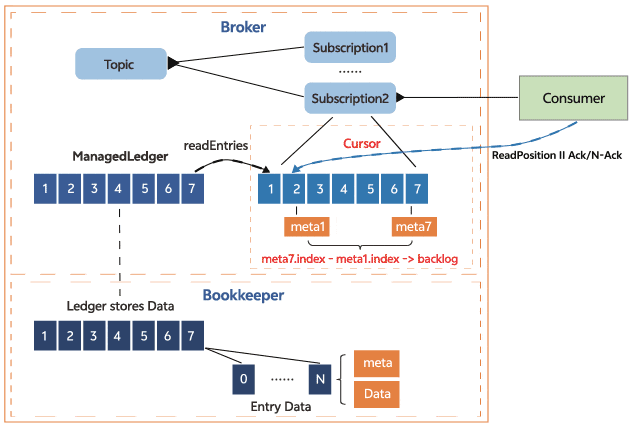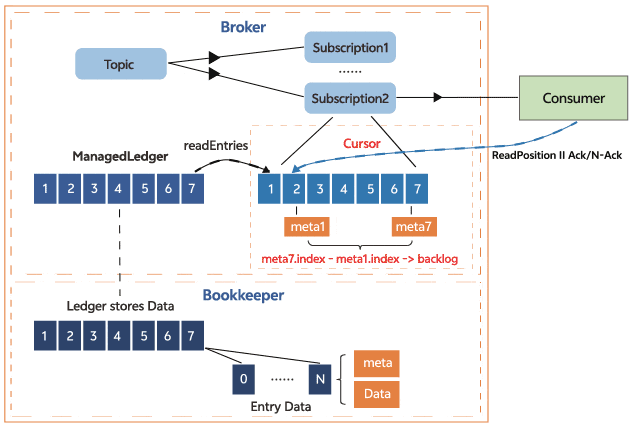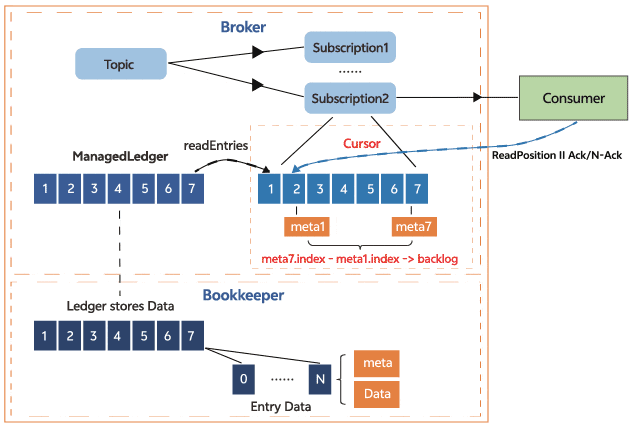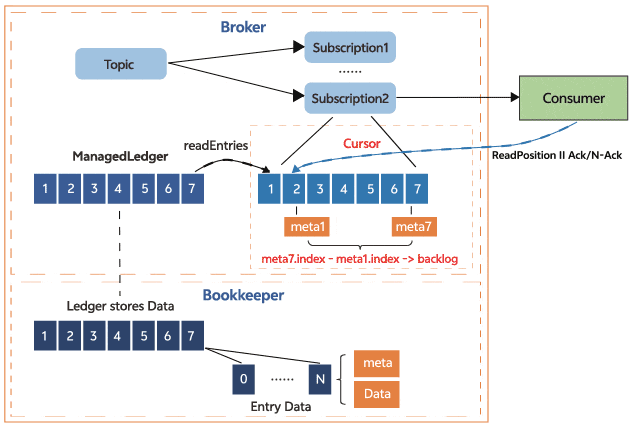
效果
上图是新订阅积压指标和原生积压指标的对比,新增的订阅积压指标单位是条,原生订阅积压指标单位是entry。在客户端指定单条发送100w条消息时,订阅积压都有明显的升高,当客户端指定批次发送100w条消息的时候,新的订阅积压指标会有明显的升高,而原生订阅积压指标相对升高幅度不大,所以新的订阅积压指标更具体的体现了订阅积压的情况。

3.2 Pulsar bundle指标
Pulsar相比于Kafka增加了自动负载均衡的能力,在Pulsar里topic分区是绑定在bundle上的,而负载均衡的最小单位是bundle,所以我们在调优负载均衡策略和参数的时候比较依赖bunlde的流量分布指标,并且该指标也可以作为我们切分bundle的参考依据。我们在开发bundle指标的时候做了下面两件事情:
统计当前Pulsar集群非游离状态bundle的负载情况对于处于游离状态的bundle(即没有被分配到任何broker上的bundle),我们指定Pulsar leader在上报自身bundle指标的同时,上报这些处于游离状态的bundle指标,并打上是否游离的标签。
效果

上图就是bundle的负载指标,除了出入流量分布的情况,我们还提供了生产者/消费者到bundle的连接数量,以便运维同学从更多角度来调优负载均衡策略和参数。
3.3 kop消费延迟指标无法上报
在我们实际运维过程中,重启kop的Coordinator节点后会偶发消费延迟指标下降或者掉0的问题,从druid查看上报的数据,我们发现在重启broker之后消费组就没有继续上报kop消费延迟指标。
(1)原因分析
由于kop的消费延迟指标是由Kafka lag exporter采集的,所以我们重点分析了Kafka lag exporter采集消费延迟指标的逻辑,下图是Kafka-lag-exporter采集消费延迟指标的示意图:
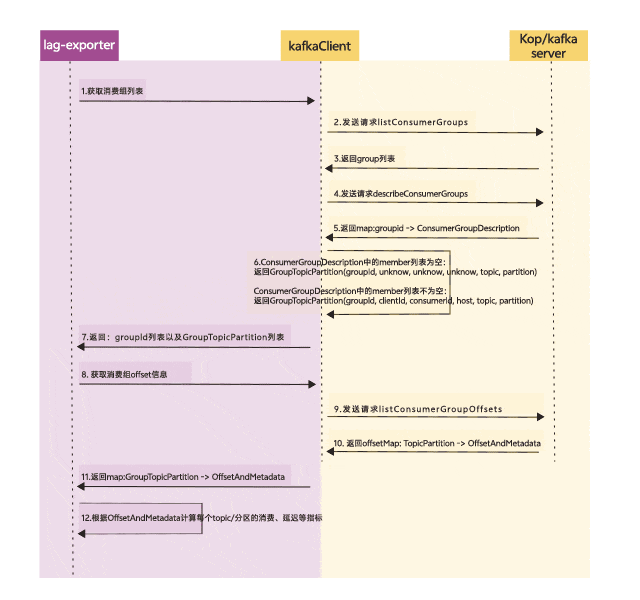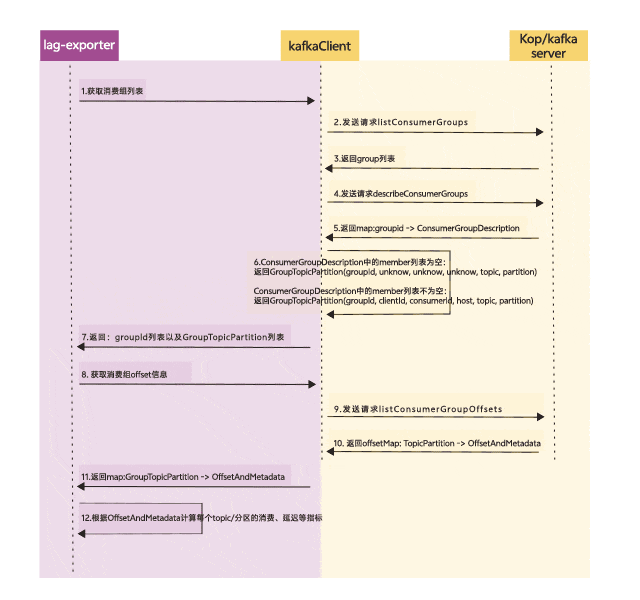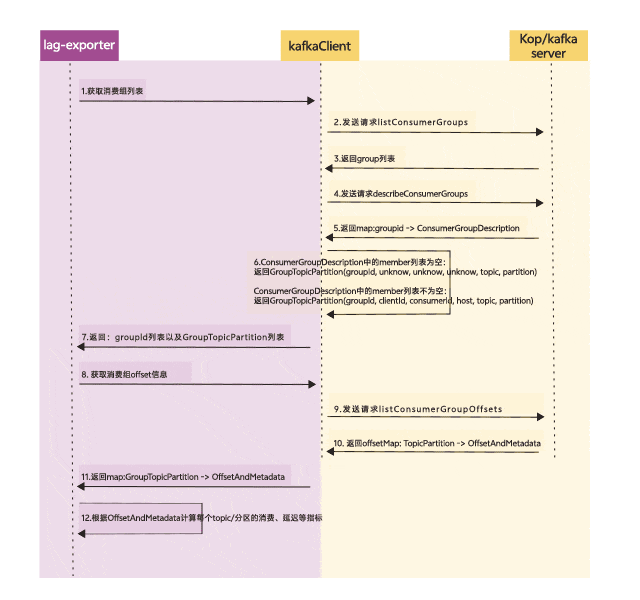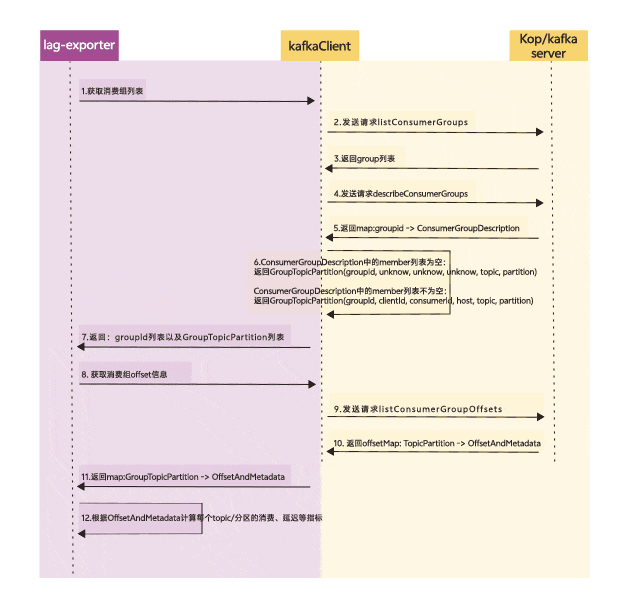
其中,kafka-lag-exporter计算消费延迟指标的逻辑会依赖kop的describeConsumerGroups接口,但是当GroupCoordinator节点重启后,该接口返回的member信息中assignment数据缺失,kafka-lag-exporter会将assignment为空的member给过滤掉,所以最终不会上报对应member下的分区指标,代码调试如下图所示:


为什么kop/Kafka describeConsumerGroups接口返回member的assignment是空的?因为consumer在启动消费时会通过groupManager.storeGroup写入__consumer_
offset,在coordinator关闭时会转移到另一个broker,但另一个broker并没有把assignment字段反序列化出来(序列化为groupMetadataValue,反序列化为readGroupMessageValue),如下图:
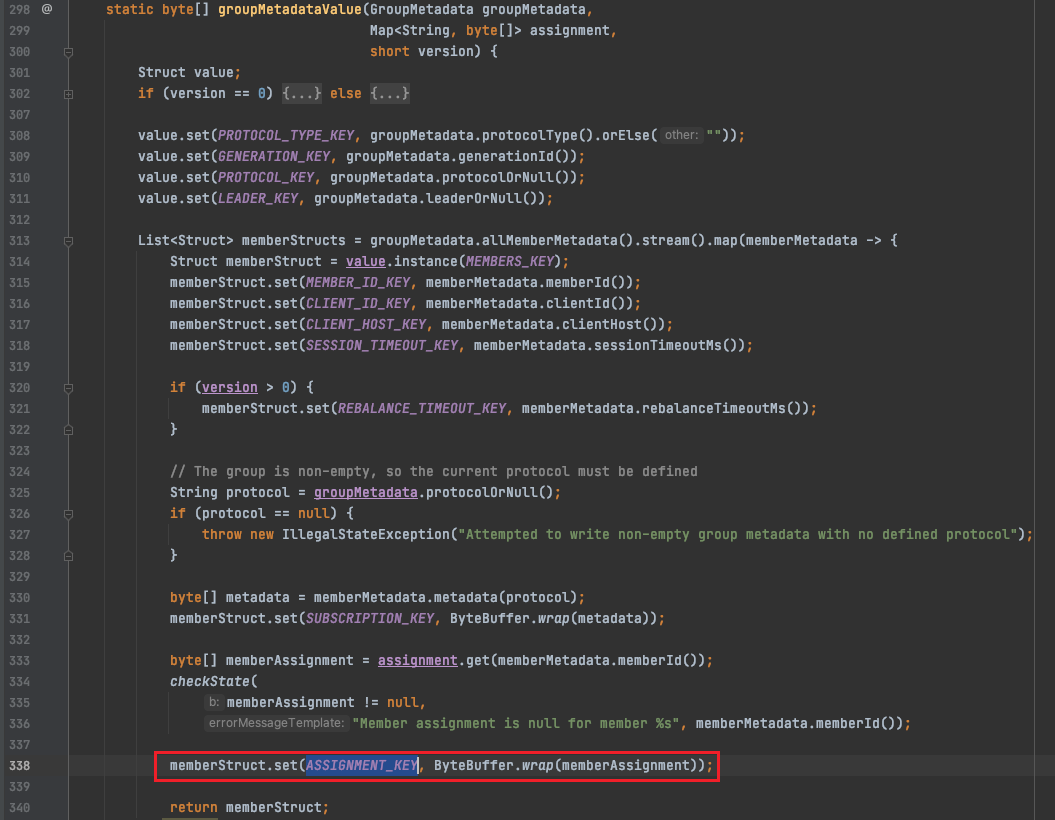
(2)解决方案
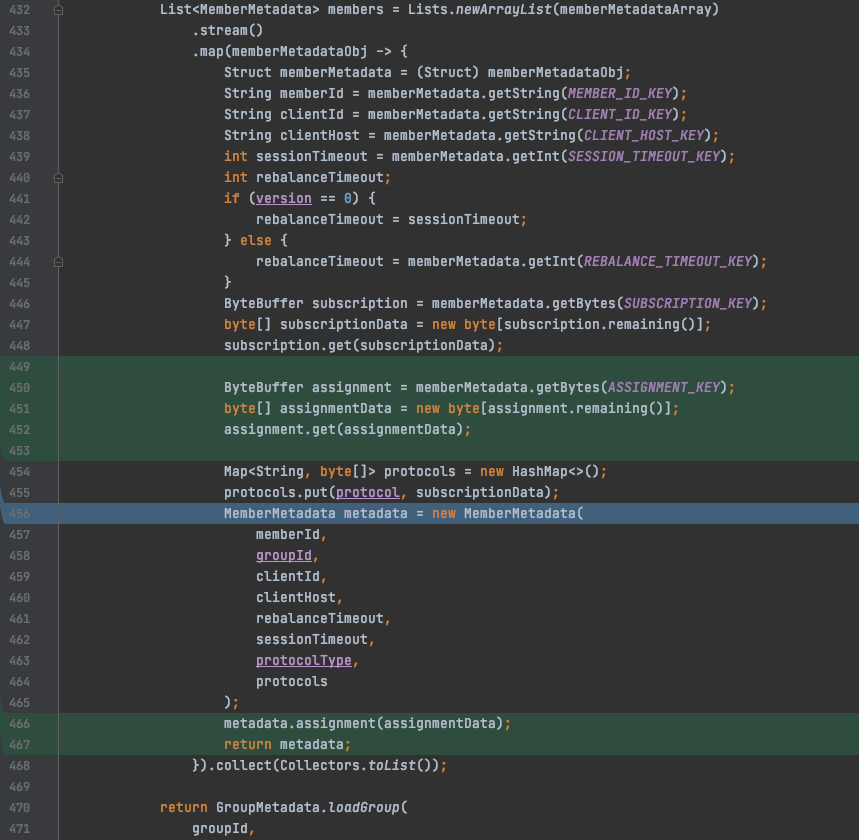
在GroupMetadataConstants#readGroup-
MessageValue()方法对coordinator反序列化消费组元数据信息时,将assignment字段读出来并设置(序列化为groupMetadataValue,反序列化为readGroupMessageValue),如下图:
四、总结
在Pulsar监控系统构建的过程中,我们解决了与用户体验、运维效率、Pulsar可用性等方面相关的问题,加快了Pulsar在vivo的落地进度。虽然我们在构建Pulsar可观测系统过程中解决了一部分问题,但是监控链路仍然存在单点瓶颈等问题,所以Pulsar在vivo的发展未来还会有很多挑战。
vivo Pulsar 万亿级消息处理实践(2)-从0到1建设 Pulsar 指标监控链路的更多相关文章
- Kafka 万亿级消息实践之资源组流量掉零故障排查分析
作者:vivo 互联网服务器团队-Luo Mingbo 一.Kafka 集群部署架构 为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下我们 Kafka 集群的部署架构及服 ...
- 腾讯自研万亿级消息中间件TubeMQ为什么要捐赠给Apache?
导语 | 近日,云+社区技术沙龙“腾讯开源技术”圆满落幕.本次沙龙邀请了多位腾讯技术专家围绕腾讯开源与各位开发者进行探讨,深度揭秘了腾讯开源项目TencentOS tiny.TubeMQ.Kona J ...
- Kafka万亿级消息实战
一.Kafka应用 本文主要总结当Kafka集群流量达到 万亿级记录/天或者十万亿级记录/天 甚至更高后,我们需要具备哪些能力才能保障集群高可用.高可靠.高性能.高吞吐.安全的运行. 这里总结内容主 ...
- 杂文笔记《Redis在万亿级日访问量下的中断优化》
杂文笔记<Redis在万亿级日访问量下的中断优化> Redis在万亿级日访问量下的中断优化 https://mp.weixin.qq.com/s?__biz=MjM5ODI5Njc2MA= ...
- 如何基于MindSpore实现万亿级参数模型算法?
摘要:近来,增大模型规模成为了提升模型性能的主要手段.特别是NLP领域的自监督预训练语言模型,规模越来越大,从GPT3的1750亿参数,到Switch Transformer的16000亿参数,又是一 ...
- 万亿级KV存储架构与实践
一.KV 存储发展历程 我们第一代的分布式 KV 存储如下图左侧的架构所示,相信很多公司都经历过这个阶段.在客户端内做一致性哈希,在后端部署很多的 Memcached 实例,这样就实现了最基本的 KV ...
- 腾讯万亿级分布式消息中间件TubeMQ正式开源
TubeMQ是腾讯在2013年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条.较之于众多明星的开源MQ组件,T ...
- js万亿级数字转汉字的封装方法
要求如图: 实现方法: function changeBillionToCN(c) { // 对传参进行类型处理,非字符串进行转换 if(typeof(c) != "string" ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
- 【HBase调优】Hbase万亿级存储性能优化总结
背景:HBase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对HBase的认识经历了懵懂到熟的过程.为了应对业务数据的压力,HBase入 ...
随机推荐
- MAMP PRO教程
简单使用 第一步 创建新主机,按主机表左下角的"+"按钮. 第二步 配置域名和项目地址 第三步 选择你要使用的web服务器 第四步 配置URL重写规则 第五步 检查端口号 第六步 ...
- 冒泡排序(LOW)
博客地址:https://www.cnblogs.com/zylyehuo/ # _*_coding:utf-8_*_ import random def bubble_sort(li): for i ...
- 多维度实测DeepSeek新模型DeepSeek-V3-0324,编程能力超强!
大家好,我是六哥!今天必须给大伙唠唠DeepSeek全新v3.就在昨晚,DeepSeek悄没声儿地在Huggingface上发布了DeepSeek-V3-0324.虽说不是全新模型,可能力提升那叫一个 ...
- C# Office COM 加载项
Office COM 加载项开发笔记 一.实现接口 IDTExtensibility2 这是实现 Office COM 加载项最基本的接口 添加 COM 引用 Microsoft Add-In Des ...
- DeepseekScanner deepseek+python实现代码审计实战
一.功能概述 DeepseekScanner实现了扫描源代码项目中的所有代码文件发送给deepseek进行安全审计的功能.具体细节包括扫描所有子目录中的代码文件,然后依次将代码文件切片发送到deeps ...
- IDEA target中没有class文件/target中有class没有yml文件/yml文件不显示叶子
target中没有class文件.表现为文件显示红波浪线,但是点进去自己又好了,但是编译会说找不到.点进入target文件夹发现没有class文件,只有yml文件或者什么都没有 解决方法:rebuil ...
- 记一次 .NET某工控任务调度系统 卡死分析
一:背景 1. 讲故事 前段时间有位朋友加我微信,来了就要进我的训练营,并且附带着纠结了他几个月的一个疑难杂症,让我帮忙看下怎么回事,问题描述截图如下: 由于这个定时任务是 furion 写的,刚好这 ...
- 块设备驱动、bio理解
别人写过的内容,我就不写了.贴一下大佬的博客,写的非常好: 块设备驱动实战基础篇一 (170行代码构建一个逻辑块设备驱动) 块设备驱动实战基础篇二 (继续完善170行过滤驱动代码至200行) 块设备驱 ...
- 关于μkeil v5.40(keil5) 如何使用STM32(ARM)虚拟下载器进行Proteus联调
最近我心血来潮,想用Proteus+keil5进行联调,但仔细在网上一找,全是某SDN扒下来的陈年老黑X,都快转出数字包浆了还在用,完完全全跟不上时代,也全是51单片机的版本,STM32(ARM)根本 ...
- 11.7K Star!这个分布式爬虫管理平台让多语言协作如此简单!
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 分布式爬虫管理平台Crawlab,支持任何编程语言和框架的爬虫管理,提供可视化界面.任务调度 ...