超简单!教你用C语言手搓LLM模型
本文由 愚人猫(Idiomeo) 编写
建议查看博客原文
一.LLM 的数学基础
大语言模型 (LLM) 的底层实现离不开扎实的数学基础,这部分将系统梳理支撑 LLM 的核心数学理论,为后续的代码实现奠定理论基础。
线性代数:LLM 的基础语言
线性代数是理解和实现 LLM 的基础,特别是矩阵运算构成了神经网络的核心操作。在 LLM 中,文本被表示为向量或矩阵形式,模型通过矩阵变换和运算来提取特征和进行预测。
矩阵乘法是神经网络前向传播的核心运算。对于两个矩阵 A 和 B,其乘积 C 的元素计算为:
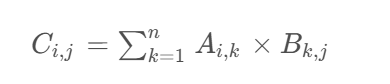
这一简单的数学操作在 LLM 中被反复应用,是模型计算的性能瓶颈之一,后续我们将讨论如何在 C 语言中优化这一操作。
向量空间理论为语言模型提供了数学基础。在词嵌入技术中,每个单词被映射为高维向量空间中的一个点,语义相似的单词在空间中距离较近。这使得模型可以通过向量运算来理解和生成语言。
概率与统计:语言模型的理论基础
概率论为语言模型提供了数学框架,特别是条件概率是理解语言模型预测下一个词的基础。语言模型的目标是估计序列概率为:
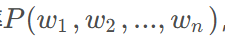
通过链式法则可以将其分解为:
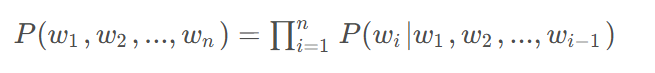
贝叶斯定理是模型参数更新的理论依据。在训练过程中,模型根据观测数据不断调整参数分布,以最大化后验概率。
微积分:优化的数学工具
微积分是 LLM 训练过程中优化算法的基础,特别是导数和梯度是反向传播算法的数学基础。
导数与梯度:梯度是导数向多元函数的推广,它指向函数增长最快的方向。在神经网络中,我们需要计算损失函数关于各个参数的梯度,以更新参数使损失最小化。
链式法则是计算复合函数导数的关键,也是反向传播算法的核心。对于复合函数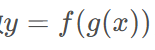
,其导数为:
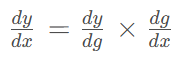
在神经网络中,复杂的计算图由许多简单函数复合而成,链式法则允许我们高效地计算梯度,这是训练深度神经网络的基础。
二.Transformer 架构
Transformer 架构是现代 LLM 的基础,本节将深入解析其数学原理和结构设计。
Transformer 概述
Transformer 是一种基于注意力机制的神经网络架构,由 Vaswani 等人于 2017 年提出。与传统的 RNN 和 LSTM 不同,Transformer 具有以下优势:
- 并行处理能力:Transformer 可以并行处理整个序列,大大加快了训练速度
- 长距离依赖建模:通过自注意力机制,Transformer 能够有效捕捉序列中长距离的依赖关系
- 无需人工标记:通过数学方法发现元素之间的关系,适用于海量互联网数据
Transformer 架构主要由编码器和解码器两部分组成,在 LLM 中通常只使用解码器部分,并通过堆叠多层解码器来提高模型能力。
自注意力机制:Transformer 的核心
自注意力机制是 Transformer 的核心组件,它允许模型在处理序列时关注不同位置的信息。自注意力的数学表达式为:
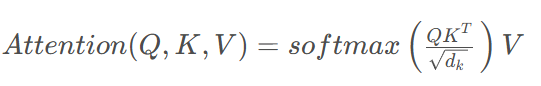
其中:
![]() 是输入序列经过线性变换得到的矩阵,维度为
是输入序列经过线性变换得到的矩阵,维度为![]()
![]() 是键向量的维度,用于缩放以防止数值溢出
是键向量的维度,用于缩放以防止数值溢出softmax函数用于归一化注意力权重,确保权重和为 1
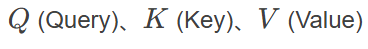 是输入序列经过线性变换得到的矩阵,维度为
是输入序列经过线性变换得到的矩阵,维度为
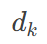 是键向量的维度,用于缩放以防止数值溢出
是键向量的维度,用于缩放以防止数值溢出自注意力机制的计算过程可以分为以下几个步骤:
- 计算相似度:将 Query 与所有 Key 进行点积,得到未归一化的注意力分数
- 缩放:除以$\sqrt{d_k}$以稳定梯度
- 归一化:通过 softmax 函数将注意力分数转换为概率分布
- 加权求和:将 Value 与注意力权重相乘并求和,得到最终的注意力输出
在代码实现中,这一过程需要高效的矩阵运算支持,后续我们将展示如何在 C 语言中实现这一机制。
多头注意力机制:增强特征表达
多头注意力机制通过并行计算多个注意力头,增强模型对语法、语义、上下文等多维特征的建模能力。其数学表达式为:
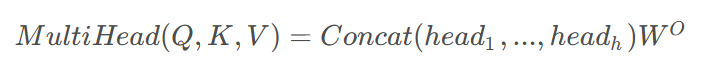
其中每个头的计算为:
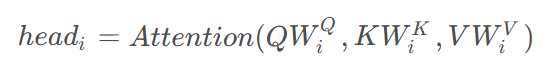
多头机制允许模型在不同的子空间中学习不同的注意力模式,显著增强了模型的表达能力。在实际应用中,通常使用 8 或 16 个注意力头。
位置编码:序列顺序的数学表达
由于自注意力机制本身不包含序列顺序信息,Transformer 需要额外的位置编码来捕捉单词的顺序信息。位置编码可以分为绝对位置编码和相对位置编码两种。
绝对位置编码通常采用正弦和余弦函数的组合:
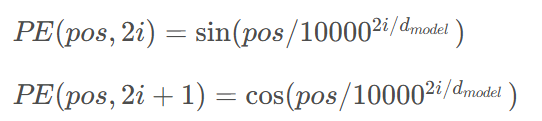
其中,pos是位置索引,i是维度索引,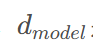
是模型维度。这种位置编码的优势是可以推广到比训练时更长的序列。
相对位置编码则考虑单词之间的相对距离,在某些模型中表现更好。
三.从数学到代码:C 语言实现 LLM 核心组件
现在我们已经掌握了 LLM 的数学基础,接下来将使用 C 语言实现 LLM 的核心组件,包括矩阵运算、注意力机制和 Transformer 块。
矩阵运算:C 语言实现与优化
矩阵运算是 LLM 的核心操作,高效的矩阵乘法实现对模型性能至关重要。
基础矩阵乘法实现
首先,我们实现一个基础的矩阵乘法函数:
void matrix_multiply(float *A, float *B, float *C, int m, int n, int p) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < p; j++) {
float sum = 0.0;
for (int k = 0; k < n; k++) {
sum += A[i * n + k] * B[k * p + j];
}
C[i * p + j] = sum;
}
}
}
这个实现虽然直观,但性能不佳,特别是对于大矩阵。在实际应用中,我们需要对其进行优化。
矩阵乘法优化策略
在 C 语言中优化矩阵乘法可以从以下几个方面入手:
- 循环展开:减少循环控制的开销,提高指令级并行性
- 缓存优化:调整循环顺序,提高缓存利用率。例如,按列优先访问输入矩阵可以提高缓存利用率
- 利用硬件加速:使用 CPU 支持的特定指令集扩展,如 Intel 的 AVX 指令集,提高运算速度
- 分块处理:将大矩阵分解为小的块进行计算,减少缓存未命中
下面是一个优化后的矩阵乘法实现:
void optimized_matrix_multiply(float *A, float *B, float *C, int m, int n, int p) {
for (int i = 0; i < m; i++) {
for (int k = 0; k < n; k++) {
float a = A[i * n + k];
for (int j = 0; j < p; j++) {
C[i * p + j] += a * B[k * p + j];
}
}
}
}
这个版本通过改变循环顺序,将 A 的访问从按行改为按列,提高了缓存利用率。在实际测试中,这种优化可以带来 2-3 倍的性能提升。
矩阵运算库的选择
在实际工程中,我们通常会选择成熟的矩阵运算库来实现高性能计算,如 BLAS、cuBLAS、MKL 等。这些库经过高度优化,能够充分利用硬件特性。
在 C 语言中使用 BLAS 库进行矩阵乘法非常简单:
#include <cblas.h>
void blas_matrix_multiply(float *A, float *B, float *C, int m, int n, int p) {
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, p, n, 1.0, A, n, B, p, 0.0, C, p);
}
这种实现通常比手动优化的代码更快,因为它利用了底层硬件的特性,如向量指令和缓存优化。
自注意力机制的 C 语言实现
基于前面的矩阵运算基础,我们可以实现自注意力机制。
基础自注意力实现
void self_attention(float *Q, float *K, float *V, float *output, int seq_len, int d_k) {
// 计算QK^T
float *scores = (float *)malloc(seq_len * seq_len * sizeof(float));
matrix_multiply(Q, K, scores, seq_len, d_k, seq_len);
// 缩放
for (int i = 0; i < seq_len; i++) {
for (int j = 0; j < seq_len; j++) {
scores[i * seq_len + j] /= sqrt(d_k);
}
}
// Softmax归一化
float *exp_scores = (float *)malloc(seq_len * seq_len * sizeof(float));
float max_score;
for (int i = 0; i < seq_len; i++) {
max_score = -INFINITY;
for (int j = 0; j < seq_len; j++) {
if (scores[i * seq_len + j] > max_score) {
max_score = scores[i * seq_len + j];
}
}
for (int j = 0; j < seq_len; j++) {
exp_scores[i * seq_len + j] = exp(scores[i * seq_len + j] - max_score);
}
}
float *probs = (float *)malloc(seq_len * seq_len * sizeof(float));
for (int i = 0; i < seq_len; i++) {
float sum = 0.0;
for (int j = 0; j < seq_len; j++) {
sum += exp_scores[i * seq_len + j];
}
for (int j = 0; j < seq_len; j++) {
probs[i * seq_len + j] = exp_scores[i * seq_len + j] / sum;
}
}
// 计算probs * V
matrix_multiply(probs, V, output, seq_len, seq_len, d_k);
free(scores);
free(exp_scores);
free(probs);
}
这个实现展示了自注意力机制的基本流程,但存在一些性能问题,如多次内存分配和释放,以及低效的 Softmax 计算。
自注意力优化策略
为了提高自注意力的性能,可以采取以下优化策略:
- 内存预分配:在初始化阶段一次性分配所有所需内存,避免训练过程中频繁的内存创建与销毁操作
- 合并操作:将多个矩阵运算合并为一个,减少中间结果的存储
- 批处理:同时处理多个序列,提高并行效率
- 利用 GPU 加速:在支持 CUDA 的 GPU 上,可以使用 GPU 加速计算
掩码自注意力
在语言模型中,我们通常使用掩码自注意力来避免在预测下一个词时查看它之后的词。掩码自注意力的实现需要在计算 scores 后、Softmax 之前应用掩码:
void masked_self_attention(float *Q, float *K, float *V, float *output, int seq_len, int d_k) {
// 计算QK^T
float *scores = (float *)malloc(seq_len * seq_len * sizeof(float));
matrix_multiply(Q, K, scores, seq_len, d_k, seq_len);
// 应用掩码
for (int i = 0; i < seq_len; i++) {
for (int j = i + 1; j < seq_len; j++) {
scores[i * seq_len + j] = -INFINITY;
}
}
// 缩放和Softmax
// ... 与基础自注意力实现相同 ...
// 计算probs * V
matrix_multiply(probs, V, output, seq_len, seq_len, d_k);
free(scores);
free(exp_scores);
free(probs);
}
多头自注意力机制实现
多头自注意力机制可以通过并行计算多个自注意力头并将结果拼接来实现。
void multi_head_attention(float *Q, float *K, float *V, float *output,
int seq_len, int d_model, int num_heads) {
int d_k = d_model / num_heads;
float *output_heads = (float *)malloc(seq_len * d_model * sizeof(float));
for (int h = 0; h < num_heads; h++) {
float *Q_head = Q + h * d_k;
float *K_head = K + h * d_k;
float *V_head = V + h * d_k;
float *output_head = output_heads + h * d_k;
self_attention(Q_head, K_head, V_head, output_head, seq_len, d_k);
}
// 拼接所有头的输出
for (int i = 0; i < seq_len; i++) {
for (int h = 0; h < num_heads; h++) {
for (int j = 0; j < d_k; j++) {
output[i * d_model + h * d_k + j] = output_heads[i * d_model + h * d_k + j];
}
}
}
free(output_heads);
}
这个实现展示了多头自注意力的基本逻辑,但在实际工程中需要考虑更多优化,如内存布局和并行计算。
前馈神经网络实现
前馈神经网络是 Transformer 的另一个核心组件,它为模型提供了非线性变换能力:
void feed_forward(float *input, float *output, int d_model, int d_ff) {
// 第一层线性变换
float *intermediate = (float *)malloc(d_ff * sizeof(float));
matrix_multiply(input, W1, intermediate, 1, d_model, d_ff);
// GELU激活函数
for (int i = 0; i < d_ff; i++) {
intermediate[i] = 0.5 * intermediate[i] * (1 + tanh(sqrt(2/PI) * (intermediate[i] + 0.044715 * pow(intermediate[i], 3))));
}
// 第二层线性变换
matrix_multiply(intermediate, W2, output, 1, d_ff, d_model);
free(intermediate);
}
这里使用了 GELU 激活函数,它在现代 LLM 中表现优于传统的 ReLU 函数。
Transformer 块的整合
将自注意力、前馈网络和其他组件整合,形成完整的 Transformer 块:
void transformer_block(float *input, float *output, int seq_len, int d_model, int num_heads, int d_ff) {
// 自注意力
float *attn_output = (float *)malloc(seq_len * d_model * sizeof(float));
multi_head_attention(input, input, input, attn_output, seq_len, d_model, num_heads);
// 残差连接和层归一化
float *residual_attn = (float *)malloc(seq_len * d_model * sizeof(float));
for (int i = 0; i < seq_len * d_model; i++) {
residual_attn[i] = input[i] + attn_output[i];
}
layer_norm(residual_attn, seq_len * d_model);
// 前馈网络
float *ff_output = (float *)malloc(seq_len * d_model * sizeof(float));
feed_forward(residual_attn, ff_output, d_model, d_ff);
// 最终残差连接和层归一化
for (int i = 0; i < seq_len * d_model; i++) {
output[i] = residual_attn[i] + ff_output[i];
}
layer_norm(output, seq_len * d_model);
free(attn_output);
free(residual_attn);
free(ff_output);
}
这个实现展示了 Transformer 块的基本结构,但在实际工程中需要考虑更多细节,如参数初始化、层归一化的具体实现等。
四.LLM 训练与推理:从数学原理到工程实践
损失函数与优化算法
LLM 的训练过程需要定义合适的损失函数,并选择有效的优化算法来最小化损失。
交叉熵损失函数是语言模型中最常用的损失函数:
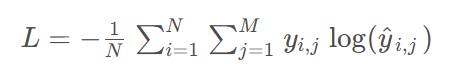
其中,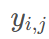
是真实标签,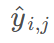
是模型预测的概率分布。
梯度下降是优化神经网络的基本算法,其数学表达式为:
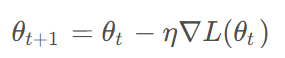
其中,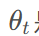
是当前参数,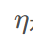
是学习率,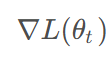
是损失函数关于参数的梯度。
在 LLM 中,通常使用AdamW 优化器,它结合了 Adam 算法和权重衰减机制。AdamW 的更新规则为:
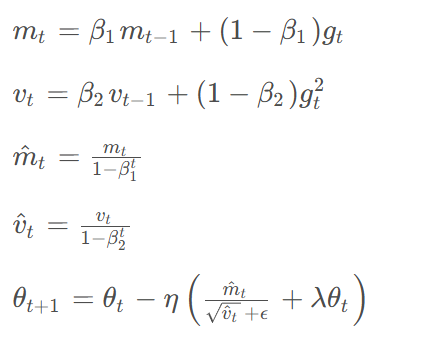
其中,m_t和v_t是动量项和速度项,
是衰减系数,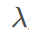
是权重衰减系数。
反向传播算法实现
反向传播是计算梯度的核心算法,它基于链式法则,从输出层向输入层反向传播误差。
以简单的神经网络为例,假设网络结构为:
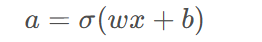
其中,
是激活函数,如 sigmoid。
输出a对权重w的导数为:
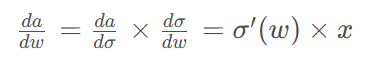
在更深的网络中,导数计算更为复杂,需要递归地应用链式法则。
在 C 语言中实现反向传播需要手动计算每个层的梯度,并正确地将它们连接起来。这是一个复杂但关键的过程,直接影响模型的训练效果。
层归一化实现
层归一化是 Transformer 架构中的关键组件,它有助于稳定训练过程并加速收敛。GPT-2 调整了 LayerNorm 的位置,将其置于每个模块的前端,即所谓的预归一化版本,显著增强了训练稳定性。
层归一化的数学表达式为:
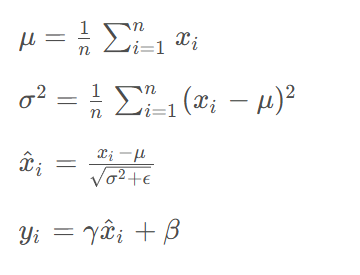
在 C 语言中实现层归一化:
void layer_norm(float *input, int size) {
// 计算均值
float mean = 0.0;
for (int i = 0; i < size; i++) {
mean += input[i];
}
mean /= size;
// 计算方差
float variance = 0.0;
for (int i = 0; i < size; i++) {
float diff = input[i] - mean;
variance += diff * diff;
}
variance /= size;
// 标准化
float epsilon = 1e-5;
float std = sqrt(variance + epsilon);
for (int i = 0; i < size; i++) {
input[i] = (input[i] - mean) / std;
}
// 缩放和偏移
for (int i = 0; i < size; i++) {
input[i] = gamma[i] * input[i] + beta[i];
}
}
混合精度训练
混合精度训练是提高 LLM 训练效率的重要技术,它使用不同精度的数据类型来存储和计算模型参数。在 C 语言中实现混合精度训练需要仔细管理不同精度的数据转换和运算。
损失缩放是混合精度训练中的关键技术,它通过放大损失值来避免小梯度的舍入误差:
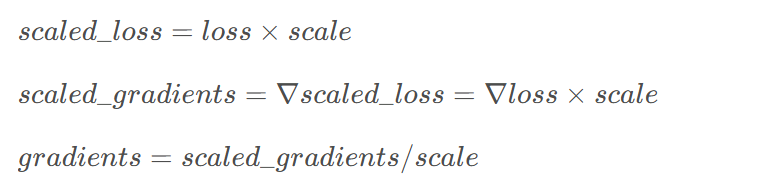
在训练过程中,我们需要动态调整缩放因子以平衡梯度的稳定性和精度。
五.工程优化:C 语言实现 LLM 的关键技术
内存管理优化
在 C 语言中实现 LLM 时,内存管理是性能优化的关键环节。
统一内存分配
统一内存分配是一种高效的内存管理策略,它在初始化阶段一次性为所有所需内存分配一个大的 1D 内存块,避免了训练过程中频繁的内存创建与销毁操作,从而维持恒定的内存占用。
#define MODEL_SIZE 1000000
float *memory_pool = (float *)malloc(MODEL_SIZE * sizeof(float));
float *ptr = memory_pool;
// 分配内存块
float *allocate_memory(int size) {
float *result = ptr;
ptr += size;
return result;
}
// 使用示例
float *A = allocate_memory(100);
float *B = allocate_memory(200);
这种方法不仅减少了内存碎片,还提高了缓存利用率,因为相关的数据可以连续存储。
内存对齐
内存对齐指的是数据地址相对于内存管理单元边界的对齐。对齐的数据可以提高访问速度,减少处理器的加载时间。
在 C 语言中,可以使用 aligned_alloc函数或编译器特定的属性来实现内存对齐:
float *aligned_array = (float *)aligned_alloc(64, 1000 * sizeof(float));
这将分配一个 64 字节对齐的数组,适合现代 CPU 的缓存行大小,提高访问效率。
内存池技术
内存池是管理相同类型对象的有效方法,它可以减少内存分配的开销。在 LLM 中,可以为频繁分配的对象(如激活值、梯度)创建内存池:
typedef struct {
float *data;
int size;
int capacity;
} MemoryPool;
MemoryPool *create_memory_pool(int initial_size) {
MemoryPool *pool = (MemoryPool *)malloc(sizeof(MemoryPool));
pool->data = (float *)malloc(initial_size * sizeof(float));
pool->size = 0;
pool->capacity = initial_size;
return pool;
}
float *allocate_from_pool(MemoryPool *pool, int size) {
if (pool->size + size > pool->capacity) {
// 扩容逻辑
int new_capacity = pool->capacity * 2;
float *new_data = (float *)realloc(pool->data, new_capacity * sizeof(float));
if (!new_data) {
// 处理错误
}
pool->data = new_data;
pool->capacity = new_capacity;
}
float *result = pool->data + pool->size;
pool->size += size;
return result;
}
编译器优化选项
编译器优化对 LLM 的性能有显著影响,正确选择优化选项可以大幅提高模型的运行速度。
GCC 提供了一系列的优化选项,通过不同的等级来调整编译过程中的优化程度:
-O0:无优化,程序编译速度最快,但运行速度较慢-O1:基本优化,平衡编译时间和执行速度-O2:较高程度的优化,牺牲一定的编译时间以换取更快的运行速度-O3:更高级别的优化,包括循环展开、内联函数等-Os:针对代码大小的优化-Ofast:启用-O3优化,并开启一些可能不完全遵循标准的优化
在实际开发中,根据项目的需要选择合适的优化等级至关重要。例如,如果开发阶段需要频繁调试,可能会选择 -O1或 -O2来平衡编译速度和运行速度。如果目标是发布产品,则可能会选择 -O2或 -O3来获得更好的性能。
此外,还可以使用特定于硬件的优化选项,如 -march=native,它会根据当前 CPU 的特性生成优化代码。
并行计算与多线程优化
在深度学习模型,特别是大型模型如 GPT-2 的训练和推理过程中,数据和计算量巨大,单线程执行往往成为瓶颈。并行计算成为提升性能的关键技术。
数据并行策略
数据并行是一种常见的并行策略,它将数据集分为多个子集,每个子集由不同的处理器或计算节点处理。在 GPT-2 中,这通常意味着每个 GPU 处理一批输入数据的一部分,并进行前向传播和反向传播。所有 GPU 共享模型参数,因此需要在每个梯度更新步骤中同步模型参数。
在 C 语言中,可以使用多线程或多进程来实现数据并行。例如,使用 POSIX 线程库 (pthread) 创建多个线程,每个线程处理不同的数据批次:
#include <pthread.h>
typedef struct {
float *data;
int start;
int end;
} ThreadArgs;
void *process_data(void *args) {
ThreadArgs *thread_args = (ThreadArgs *)args;
// 处理数据范围[start, end)
return NULL;
}
int main() {
pthread_t threads[4];
ThreadArgs args[4];
for (int i = 0; i < 4; i++) {
args[i].data = data;
args[i].start = i * batch_size;
args[i].end = (i + 1) * batch_size;
pthread_create(&threads[i], NULL, process_data, &args[i]);
}
for (int i = 0; i < 4; i++) {
pthread_join(threads[i], NULL);
}
return 0;
}
模型并行策略
模型并行策略将模型的不同部分分配到不同的处理器或计算节点上。对于 GPT-2 来说,一个模型的层数可能非常多,模型并行意味着将不同的层分配给不同的 GPU。这种方法可以处理单个 GPU 内存不足的问题,但也可能导致 GPU 之间的通信开销增大。
在 C 语言中实现模型并行需要仔细管理层之间的数据传递,确保每个层在正确的设备上执行,并正确地将结果传递给下一层。
多线程编程技巧
多线程编程是实现并行计算的有效手段。在 C 语言中,可以利用 POSIX 线程库来实现多线程编程。
以下是一些多线程编程技巧:
- 线程安全:确保多个线程在访问同一资源时,不会出现数据竞争或资源冲突。可以通过锁 (mutexes)、信号量 (semaphores)、条件变量 (condition variables) 等同步机制来保证线程安全。
- 线程池:线程池能够管理多个线程,重用线程以避免频繁创建和销毁线程的开销。在处理大量独立任务时,线程池特别有效。
- 任务划分:合理划分任务以适应线程工作,同时考虑负载均衡和减少同步开销。
- 避免死锁:在编写多线程代码时,要特别注意避免死锁,即两个或多个线程相互等待对方释放资源,从而无限期阻塞。通常通过锁定资源的顺序性和超时机制来预防死锁。
张量运算优化
张量运算是 LLM 的核心操作,其性能直接影响模型的训练和推理速度。
利用硬件加速
当前的 CPU 和 GPU 通常支持特定的指令集扩展,比如 Intel 的 AVX 指令集,以及 NVIDIA 的 CUDA 技术。确保算法和代码充分利用这些硬件特性,能够大幅度提升运算速度。
在 C 语言中,可以使用内联汇编或编译器特定的内置函数来利用这些指令。例如,使用 AVX 指令进行向量加法:
#include <immintrin.h>
void vector_add(float *A, float *B, float *C, int n) {
int i;
for (i = 0; i < n - 7; i += 8) {
__m256 a = _mm256_loadu_ps(A + i);
__m256 b = _mm256_loadu_ps(B + i);
__m256 c = _mm256_add_ps(a, b);
_mm256_storeu_ps(C + i, c);
}
// 处理剩余元素
for (; i < n; i++) {
C[i] = A[i] + B[i];
}
}
这种实现可以显著提高向量运算的速度,特别是对于大数组。
内存访问模式优化
内存访问模式对于张量运算的性能至关重要。例如,对于矩阵乘法,按列优先访问输入矩阵可以提高缓存利用率。
考虑以下矩阵乘法的循环顺序:
for (int i = 0; i < m; i++) {
for (int j = 0; j < p; j++) {
float sum = 0.0;
for (int k = 0; k < n; k++) {
sum += A[i * n + k] * B[k * p + j];
}
C[i * p + j] = sum;
}
}
在这种顺序下,矩阵 B 是按列访问的,这可能导致缓存未命中。通过调整循环顺序,可以改善这一问题:
for (int i = 0; i < m; i++) {
for (int k = 0; k < n; k++) {
float a = A[i * n + k];
for (int j = 0; j < p; j++) {
C[i * p + j] += a * B[k * p + j];
}
}
}
这种调整使得矩阵 B 按行访问,提高了缓存利用率,从而加速了计算。
张量核优化
在支持张量核的 GPU 中,使用专门设计的张量运算单元可以进一步加速大规模的浮点运算。GPT-2 的训练和推理过程中,这种运算单元能带来显著的速度提升。
在 C 语言中使用 CUDA 进行张量核优化需要编写专门的核函数,并利用 CUDA 的并行计算模型。这是一个复杂但值得的优化方向,可以显著提高模型的运行效率。
编译时优化与代码生成
在 C 语言中实现 LLM 时,编译时优化和代码生成是提高性能的有效手段。
循环展开
循环展开是一种常见的编译器优化技术,也可以手工实现。它可以减少循环的开销,增加指令级并行性,同时提高缓存的利用率。
例如,将一个简单的循环:
for (int i = 0; i < 1000; i++) {
result[i] = a[i] * b[i];
}
展开为:
for (int i = 0; i < 1000; i += 4) {
result[i] = a[i] * b[i];
result[i+1] = a[i+1] * b[i+1];
result[i+2] = a[i+2] * b[i+2];
result[i+3] = a[i+3] * b[i+3];
}
这种方法减少了循环控制的开销,并可能允许编译器生成更高效的指令。
内联函数
内联函数可以减少函数调用的开销,特别是对于小函数。在 C 语言中,可以使用 inline关键字提示编译器进行内联:
inline float square(float x) {
return x * x;
}
编译器可能会忽略这个提示,但大多数现代编译器在优化级别较高时会自动内联合适的函数。
自动向量化
现代编译器可以自动将某些标量操作转换为向量操作,这称为自动向量化。通过编写适合向量化的代码,可以利用这一特性提高性能。
适合向量化的代码通常具有以下特点:
- 简单的循环结构
- 无依赖的操作
- 连续的内存访问
例如,以下代码可能无法被有效地向量化:
for (int i = 0; i < n; i++) {
if (a[i] > 0) {
b[i] = a[i] * c[i];
}
}
而以下代码更容易被向量化:
for (int i = 0; i < n; i++) {
b[i] = a[i] * c[i];
}
通过避免条件语句和复杂的控制流,可以提高编译器自动向量化的成功率。
六.GPT-2 实战:C 语言实现与优化
GPT-2 架构概述
GPT-2 是基于变换器 (Transformer) 架构的预训练语言模型,它通过大量的文本数据学习语言的深层特征。GPT-2 由多个 Transformer 解码器组成,每个解码器具有自注意力机制,能够捕捉输入序列之间的长距离依赖关系。
GPT-2 的核心架构特点包括:
- 掩码自注意力:确保在预测下一个词时不会查看它之后的词
- 预归一化:将 LayerNorm 置于每个模块的前端,增强训练稳定性
- 更大的模型规模:从 1.17 亿到 15 亿参数的不同版本
- 更多的数据:使用了大量的文本数据进行预训练
从 PyTorch 到 C 语言的转换
将 PyTorch 实现的 GPT-2 转换为 C 语言需要理解 PyTorch 张量的内存布局和操作原理。
在 PyTorch 中,张量是对底层 1D 内存存储的多维视图。以一个 2x3x4 张量为例,其实际内存布局是一维数组,大小为 2×3×4=24。访问张量元素时,如 a[1,2,3],PyTorch 会计算出在 1D 数组中的偏移量(此处为 23),返回该位置的值。
在 C 语言实现中,需要明确理解这种内存布局,并运用类似指针偏移规则来访问数据。
以下是一个简化的代码示例,展示了如何使用 C 语言实现一个简单的自回归模型的一部分功能:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void predict_next_word(char *text, int context_length) {
// 这里的实现是高度简化的,实际的GPT-2模型要复杂得多
// 假设模型根据前面的context_length个词预测下一个词
printf("下一个词是: %s\n", text + strlen(text) - context_length);
}
int main() {
char text[] = "The quick brown fox jumps over the lazy dog";
predict_next_word(text, 10); // 预测基于最后10个词
return 0;
}
完整 GPT-2 模型的 C 语言实现
实现完整的 GPT-2 模型需要整合前面讨论的所有组件,包括自注意力、前馈网络、层归一化等,并处理好内存管理和计算流程。
以下是一个简化的 GPT-2 模型结构:
typedef struct {
int vocab_size;
int d_model;
int num_heads;
int num_layers;
int seq_len;
// 模型参数
float *embedding_table;
float *positional_embeddings;
TransformerBlock *blocks;
float *final_layer_norm;
float *lm_head;
} GPT2Model;
GPT2Model *create_gpt2_model(int vocab_size, int d_model, int num_heads, int num_layers, int seq_len) {
GPT2Model *model = (GPT2Model *)malloc(sizeof(GPT2Model));
model->vocab_size = vocab_size;
model->d_model = d_model;
model->num_heads = num_heads;
model->num_layers = num_layers;
model->seq_len = seq_len;
// 初始化参数
model->embedding_table = allocate_memory(vocab_size * d_model);
model->positional_embeddings = allocate_memory(seq_len * d_model);
model->blocks = (TransformerBlock *)malloc(num_layers * sizeof(TransformerBlock));
for (int i = 0; i < num_layers; i++) {
model->blocks[i] = create_transformer_block(d_model, num_heads, d_model * 4);
}
model->final_layer_norm = allocate_memory(d_model);
model->lm_head = allocate_memory(d_model * vocab_size);
return model;
}
float *gpt2_forward(GPT2Model *model, int *input_ids) {
// 嵌入层
float *embeddings = embed_tokens(model->embedding_table, input_ids, model->seq_len, model->d_model);
add_positional_embeddings(embeddings, model->positional_embeddings, model->seq_len, model->d_model);
// 层归一化
layer_norm(embeddings, model->d_model);
// 堆叠Transformer块
float *hidden_state = embeddings;
for (int i = 0; i < model->num_layers; i++) {
hidden_state = transformer_block_forward(&model->blocks[i], hidden_state, model->seq_len);
}
// 最终层归一化
layer_norm(hidden_state, model->d_model);
// 线性层
float *logits = (float *)malloc(model->seq_len * model->vocab_size * sizeof(float));
matrix_multiply(hidden_state, model->lm_head, logits, model->seq_len, model->d_model, model->vocab_size);
return logits;
}
这只是一个简化的实现,实际的 GPT-2 模型要复杂得多,需要处理更多的细节,如注意力掩码、参数初始化、梯度计算等。
性能优化案例研究
Karpathy 的 llm.c 项目展示了如何使用纯 C 实现 GPT-2 的训练过程,仅用约 1000 行代码,并精确复现了 PyTorch 参考实现的结果。
该项目的关键优化策略包括:
- 统一内存分配:在初始化阶段一次性为所有所需内存分配一个大的 1D 内存块,避免了训练过程中频繁的内存创建与销毁操作。
- 手动实现前向与反向传播:手动编写每个独立层的前向与反向传播函数,并将它们有序地串联起来。例如,精心实现 LayerNorm 层的前向与反向计算。
- 精细的指针运算:对内存中的每个位置进行极为细致的指针运算,确保数据访问的正确性。
- CUDA 移植:将现有 CPU 实现逐步迁移到 CUDA 平台,利用 GPU 加速计算,提升效率。
- 精度降低:将精度由 fp32 降至 fp16 及更低,以减少内存需求与提高计算速度。
通过这些优化,llm.c 项目实现了高效的 GPT-2 训练,证明了 C 语言在 LLM 实现中的潜力。
七.LLM 部署与应用优化
模型量化与压缩
模型量化是将模型参数从高精度(如 32 位浮点数)转换为低精度(如 16 位、8 位或 4 位)表示的过程,这可以显著减少模型的内存占用和计算需求。
在 C 语言中实现模型量化需要仔细处理精度损失和数值范围:
void float_to_int8(float *input, int8_t *output, int size, float scale) {
for (int i = 0; i < size; i++) {
output[i] = (int8_t)(input[i] / scale + 0.5);
}
}
void int8_to_float(int8_t *input, float *output, int size, float scale) {
for (int i = 0; i < size; i++) {
output[i] = (float)input[i] * scale;
}
}
其中,scale是缩放因子,用于将浮点数值映射到整数范围内。
模型压缩技术,如 QLoRA 技术,可以实现 4-bit 量化微调,结合梯度检查点技术将显存消耗降低至原始需求的 1/8。
推理优化策略
推理优化的目标是在保持模型精度的前提下,提高模型的运行速度和降低资源消耗。
模型剪枝是一种常用的优化技术,它通过移除对模型性能影响较小的参数来减小模型大小。在 C 语言中实现模型剪枝需要修改模型参数结构,并调整计算流程以跳过被剪枝的连接。
混合推理架构是生产环境中常用的部署方案:针对高频请求部署 Triton 推理服务器(GPU 加速),低频长尾需求使用 vLLM+CPU 集群降本。
监控与性能分析
在生产环境中部署 LLM 时,监控与性能分析是确保系统稳定运行的关键。
服务监控体系应构建 Prometheus+Grafana 监控面板,实时跟踪 P99 延迟、Token 生成速率等 12 项核心指标。
在 C 语言中,可以实现简单的性能分析工具,记录关键操作的执行时间:
#include <time.h>
typedef struct {
clock_t start;
clock_t end;
} Timer;
Timer *start_timer() {
Timer *timer = (Timer *)malloc(sizeof(Timer));
timer->start = clock();
return timer;
}
float stop_timer(Timer *timer) {
timer->end = clock();
float duration = ((float)(timer->end - timer->start)) / CLOCKS_PER_SEC;
free(timer);
return duration;
}
// 使用示例
Timer *t = start_timer();
// 执行需要计时的操作
float duration = stop_timer(t);
printf("操作耗时: %f秒\n", duration);
这些工具可以帮助识别性能瓶颈,并指导进一步的优化工作。
超简单!教你用C语言手搓LLM模型的更多相关文章
- 超简单!教你如何修改源列表(sources.list)来提高软件访问速度
因为Ubuntu官方的源地址不在国内,所以在国内的访问速度非常慢,比如:我们要下载或是更新软件那速度比蜗牛还慢.所以,我们需要改成国内的镜像服务器,这样,我们在下载或更新软件的时候就会很快了. 配置步 ...
- 教你如何使用Java手写一个基于链表的队列
在上一篇博客[教你如何使用Java手写一个基于数组的队列]中已经介绍了队列,以及Java语言中对队列的实现,对队列不是很了解的可以我上一篇文章.那么,现在就直接进入主题吧. 这篇博客主要讲解的是如何使 ...
- 把C#程序(含多个Dll)合并成一个Exe的超简单方法
开发程序的时候经常会引用一些第三方的DLL,然后编译生成的exe文件就不能脱离这些DLL独立运行了. 但是,很多时候我们本想开发一款只需要一个exe就能完美运行的小工具.那该怎么办呢? 下文介绍一种超 ...
- 【elasticsearch】(2)centos7 超简单安装elasticsearch 的监控、测试的集群工具elasticsearch head
elasticsearch-head是elasticsearch(下面称ES)比较普遍使用的可监控.测试等功能的集群管理工具,是由H5编写的单独的网页程序.使用方法网上很多,这里教大家一个超简单安装h ...
- 打造支持apk下载和html5缓存的 IIS(配合一个超简单的android APP使用)具体解释
为什么要做这个看起来不靠谱的东西呢? 由于刚学android开发,还不能非常好的熟练控制android界面的编辑和操作,所以我的一个急着要的运用就改为html5版本号了,反正这个运用也是须要从serv ...
- python超简单的web服务器
今天无意google时看见,心里突然想说,python做web服务器,用不用这么简单啊,看来是我大惊小怪了. web1.py 1 2 3 #!/usr/bin/python import Simp ...
- 超简单的全新win10安装
1.准备工作! 这里说一下需要装系统的东西: 至少8G的U盘或内存卡 一台Windows电脑 在要安装的电脑上至少有16G的空间,最好至少64G. 2.现成电脑下载文件(已经有重装系统U盘跳过这一步) ...
- Junit使用的超简单介绍
Junit使用的超简单介绍 前言:我对Junit了解的并不多,只是今天突然听到有人提到了它,而且现在时间还早,所以我觉得我不妨更一篇关于Junit4的超级超级简单的用法,全当是为了省去看官网demo的 ...
- ECharts.js 超简单入门(本质canvas)
ECharts.js 超简单入门(本质canvas) 一.总结 一句话总结:echarts这些图标的本质都是canvas. 二.ECharts.js学习(一) 简单入门 EChart.js 简单入门 ...
- 超简单的OpenGL & WebGL & Three.js介绍_1
专业解释 什么是OpenGL OpenGL(Open Graphics Library即开放图形库或者“开放式图形库”)是用于渲染2D.3D矢量图形的跨语言.跨平台的应用程序编程接口(API). 这个 ...
随机推荐
- AgenticSeek - 完全本地的AI助手替代方案
English | 中文 | 繁體中文 | Français | 日本語 | Português (Brasil) 100%本地运行的Manus AI替代品,支持语音的AI助手,可自主浏览网页.编写代 ...
- 开源公开课丨ChengYing安装原理剖析
一.直播介绍 之前的内容,我们为大家分享了ChengYing入门介绍,以及ChengYing部署Hadoop集群实战,本期我们为大家分享ChengYing安装原理. 本次直播我们将详细介绍ChengY ...
- 开源直播课丨高效稳定易用的数据集成框架——ChunJun类加载原理与实现
一.直播介绍 前几期,我们为大家分享了ChunJun的数据还原.Hive事务表及传输模块的一些内容,本期我们为大家分享ChunJun类加载原理与实现. 本次直播我们将从Java 类加载器解决类冲突基本 ...
- window10本地搭建DeepSeek R1(一)
本章介绍在window上部署 DeepSeek R1-8B + Open WebUI :需要安装的有:Ollama,python 3.11,DeepSeek ,Open WebUI. 一:环境:我的w ...
- ET框架运行(Mac环境)--客户端
1:环境 Mac电脑,安装.net cor2 2.2 ,JetBrains Rider编辑器,Unity环境(2018.4.28f1) 终端运行: dotnet --version 查看是否安装n ...
- Spring AI 实现让你的 AI “三思而后行”
你是否遇到过这样的情况:精心设计的 AI 应用,在面对稍微复杂点的问题时,给出的答案却驴唇不对马嘴?感觉它好像"看了一眼就答",根本没仔细"阅读理解". 别急, ...
- Kamailio 5.8.3与rtpengine双网卡SBC集成要点
本文档总结了将Kamailio 5.8.3与rtpengine(配置为双网卡模式)集成以实现SIP+RTP媒体流转发(包括音视频和RTCP)的关键配置要点和最佳实践.用户场景包括:无NAT.公私网双向 ...
- CLTX 笔试题目预览
error: multiple storage classes in declaration of `i' 代理服务器常用以下端口: (1). HTTP协议代理服务器常用端口号:80/8080/312 ...
- QT 新建子窗口注意事项
简介 新建子窗口注意事项 要保持类名一致 例如 Log.ui class Log 都是Log
- iPaaS集成系统,统一管理企业API
RestCloud iPaaS是一个集成平台,一个集成系统,也是一套可全面解决企业面临的以目前传统集成技术无法突破的难点的集成方案产品.RestCloud新一代的混合集成平台,以API为中心,基于微服 ...