# SpringBoot3 多数据源配置与实战指南
SpringBoot3 多数据源配置与实战指南
在实际开发中,多数据源场景越来越常见,比如读写分离、数据分片等。本文将基于SpringBoot3,结合MyBatis-Plus和dynamic-datasource,详细介绍多数据源的配置与使用方法。
环境准备
数据库设计
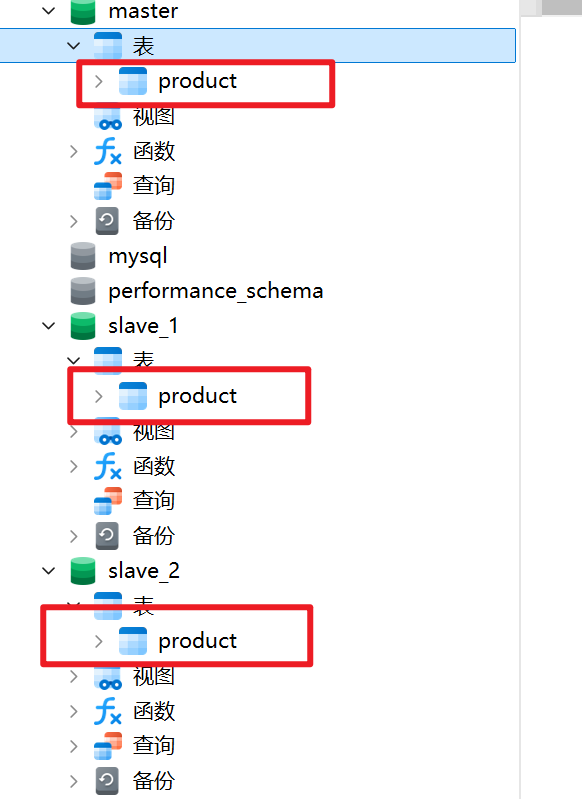
首先需要准备三个数据库:master、slave_1、slave_2,其中:
master库需要创建表并插入测试数据slave_1和slave_2只需要创建表结构,不插入数据
创建商品表SQL:
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '商品ID',
`product_code` varchar(50) NOT NULL COMMENT '商品编码',
`product_name` varchar(200) NOT NULL COMMENT '商品名称',
`category_id` bigint NOT NULL COMMENT '分类ID',
`category_name` varchar(100) NOT NULL COMMENT '分类名称',
`price` decimal(10,2) NOT NULL COMMENT '销售价格',
`stock` int NOT NULL DEFAULT 0 COMMENT '库存数量',
`status` tinyint NOT NULL DEFAULT 1 COMMENT '状态(0-下架,1-上架)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`create_by` bigint DEFAULT NULL COMMENT '创建人ID',
`update_by` bigint DEFAULT NULL COMMENT '更新人ID',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_product_code` (`product_code`),
KEY `idx_category_id` (`category_id`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
向master库插入测试数据:
INSERT INTO `product` (`product_code`, `product_name`, `category_id`, `category_name`, `price`, `stock`, `status`, `create_by`, `update_by`) VALUES
('P2025001', 'Apple iPhone 16 Pro', 101, '智能手机', 7999.00, 235, 1, 1, 1),
('P2025002', '华为Mate 70 Pro', 101, '智能手机', 6799.00, 189, 1, 1, 1),
('P2025003', '小米15 Ultra', 101, '智能手机', 5299.00, 312, 1, 1, 1),
('P2025004', 'MacBook Pro 16', 102, '笔记本电脑', 18999.00, 78, 1, 1, 1),
('P2025005', '联想拯救者Y9000P', 102, '笔记本电脑', 12999.00, 105, 1, 1, 1),
('P2025006', '索尼WH-1000XM6', 103, '耳机', 2499.00, 93, 1, 1, 1),
('P2025007', '大疆DJI Mini 5', 104, '无人机', 4788.00, 45, 1, 1, 1),
('P2025008', '任天堂Switch OLED', 105, '游戏机', 2099.00, 67, 1, 1, 1),
('P2025009', '三星Galaxy Tab S11', 106, '平板电脑', 5499.00, 52, 1, 1, 1),
('P2025010', '佳能EOS R5', 107, '相机', 25999.00, 18, 1, 1, 1);
实体类定义
创建对应的Product实体类:
import com.baomidou.mybatisplus.annotation.*;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
/**
* 商品表实体类
*/
@Data
@TableName("product")
public class Product {
/**
* 商品ID
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 商品编码
*/
@TableField("product_code")
private String productCode;
/**
* 商品名称
*/
@TableField("product_name")
private String productName;
/**
* 分类ID
*/
@TableField("category_id")
private Long categoryId;
/**
* 分类名称
*/
@TableField("category_name")
private String categoryName;
/**
* 销售价格
*/
@TableField("price")
private BigDecimal price;
/**
* 库存数量
*/
@TableField("stock")
private Integer stock;
/**
* 状态(0-下架,1-上架)
*/
@TableField("status")
private Integer status;
/**
* 创建时间
*/
@TableField(value = "create_time", fill = FieldFill.INSERT)
private LocalDateTime createTime;
/**
* 更新时间
*/
@TableField(value = "update_time", fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
/**
* 创建人ID
*/
@TableField(value = "create_by", fill = FieldFill.INSERT)
private Long createBy;
/**
* 更新人ID
*/
@TableField(value = "update_by", fill = FieldFill.INSERT_UPDATE)
private Long updateBy;
}
项目配置
依赖配置
需要注意的是我这里使用的是SpringBoot3,对应的各种依赖版本都比较高,请你按照你现在的SpringBoot版本选择合适的依赖
在pom.xml中添加相关依赖(SpringBoot3版本):
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.2.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.14</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot3-starter</artifactId>
<version>4.3.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>
数据源配置
在application.yml中配置多数据源:
spring:
datasource:
dynamic:
primary: master # 默认数据源
strict: false # 不严格匹配数据源,不存在时使用默认数据源
datasource:
master:
url: jdbc:mysql://localhost:3306/master?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 12345678
driver-class-name: com.mysql.cj.jdbc.Driver
# Druid 连接池配置
druid:
initial-size: 5
min-idle: 5
max-active: 20
max-wait: 60000
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
filters: stat,wall,log4j2
use-global-data-source-stat: true
connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
slave_1:
url: jdbc:mysql://localhost:3306/slave_1?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 12345678
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
# 配置与master相同,省略...
slave_2:
url: jdbc:mysql://localhost:3306/slave_2?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 12345678
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
# 配置与master相同,省略...
数据源监控
为了方便我们在日志中观察我们到底是操作的什么数据库所以我们需要拦截器打印我们每一次数据库操作时的连接串信息,看看我们到底是执行的哪一个数据库下面是需要添加的代码:
我们在你的项目下新建一个interceptor的包,然后新建下面的拦截器
实现拦截器
import org.apache.ibatis.executor.statement.StatementHandler;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.reflection.MetaObject;
import org.apache.ibatis.reflection.SystemMetaObject;
import java.sql.Connection;
import java.util.Properties;
/**
* MyBatis拦截器:打印执行SQL所属的数据库URL
*/
@Intercepts({
@Signature(
type = StatementHandler.class,
method = "prepare",
args = {Connection.class, Integer.class}
)
})
public class SqlDataSourceInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 获取当前执行的SQL语句
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
MetaObject metaObject = SystemMetaObject.forObject(statementHandler);
String sql = (String) metaObject.getValue("delegate.boundSql.sql");
if (sql == null || sql.trim().isEmpty()) {
return invocation.proceed();
}
// 获取当前数据库连接及URL
Connection connection = (Connection) invocation.getArgs()[0];
String dbUrl = connection.getMetaData().getURL();
String dbProduct = connection.getMetaData().getDatabaseProductName();
// 打印SQL及所属数据源信息
System.out.println("==============================================");
System.out.println("数据库类型: " + dbProduct);
System.out.println("数据库URL: " + dbUrl);
System.out.println("执行SQL: " + sql.trim().replaceAll("\\s+", " "));
System.out.println("==============================================");
// 继续执行原操作
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
// 只拦截StatementHandler类型的对象
if (target instanceof StatementHandler) {
return Plugin.wrap(target, this);
}
return target;
}
@Override
public void setProperties(Properties properties) {
// 可以通过properties配置拦截器参数
}
}
注册拦截器
我们的拦截器现在就已经写好了,但是我们需要把他注册一下,让他在我们的项目中生效:那接下来我们就需要在你的项目的config目录下新建一个数据库的配置类:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 数据库配置类:注册SQL数据源拦截器
*/
@Configuration
public class DataSourcesConfig {
/**
* 注册SQL数据源拦截器
*/
@Bean
public SqlDataSourceInterceptor sqlDataSourceInterceptor() {
return new SqlDataSourceInterceptor();
}
}
多数据源使用
Mapper层
现在完事具备只欠东风了:我们开始写我们的业务逻辑:
我们现在来随便写一个接口:来看看我我们在不指定数据源的情况下使用的是那个数据库
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.rory.multipledatasources.pojo.Product;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface TestMapper extends BaseMapper<Product> {
}
Service层
在Service中通过@DS注解指定数据源:
@Slf4j
@Service
@RequiredArgsConstructor(onConstructor_ = @Autowired)
public class TestServiceImpl implements TestService {
private final TestMapper testMapper;
/**
* 使用默认数据源(master)
*/
@Override
public List<Product> test() {
List<Product> allList = testMapper.selectList(null);
log.info("查询到所有数据,共{}条", allList.size());
return allList;
}
}
写好之后我们来看看我们的knife4j中输出的结果是什么?

我们可以看到是查询到数据的,还记得我之前的操作嘛?我们刚才只在master数据库中的product中插入了数据说明他现在用的是master这个数据库,再来看看我们刚才的日志:

也可以看到使用的是master数据库。为什么呢?原因在我们的yaml文件中:

我们可以看到默认数据源使用的是master 而且我们在还配置了找不到数据的情况下也是用的是我们默认的数据源。好了接下来我们就开始多数据源的操作了!
我们需要在刚才的实现类中新增下面这部分代码:主要我们新增了@DS注解这个注解主要是来指定数据源的可以看到我们在下面的方法上指定的数据原是:slave_1,好的接下来我们就去看看,能不能查到数据:
@Override
@DS("slave_1")
public List<Product> testSlave_1() {
List<Product> allList = testMapper.selectList(null);
log.info("在Slave_1数据库中查询到所有数据,共{}条", allList.size());
return allList;
}
让我们再次回到knife4j中,可以发现没有查到任何数据
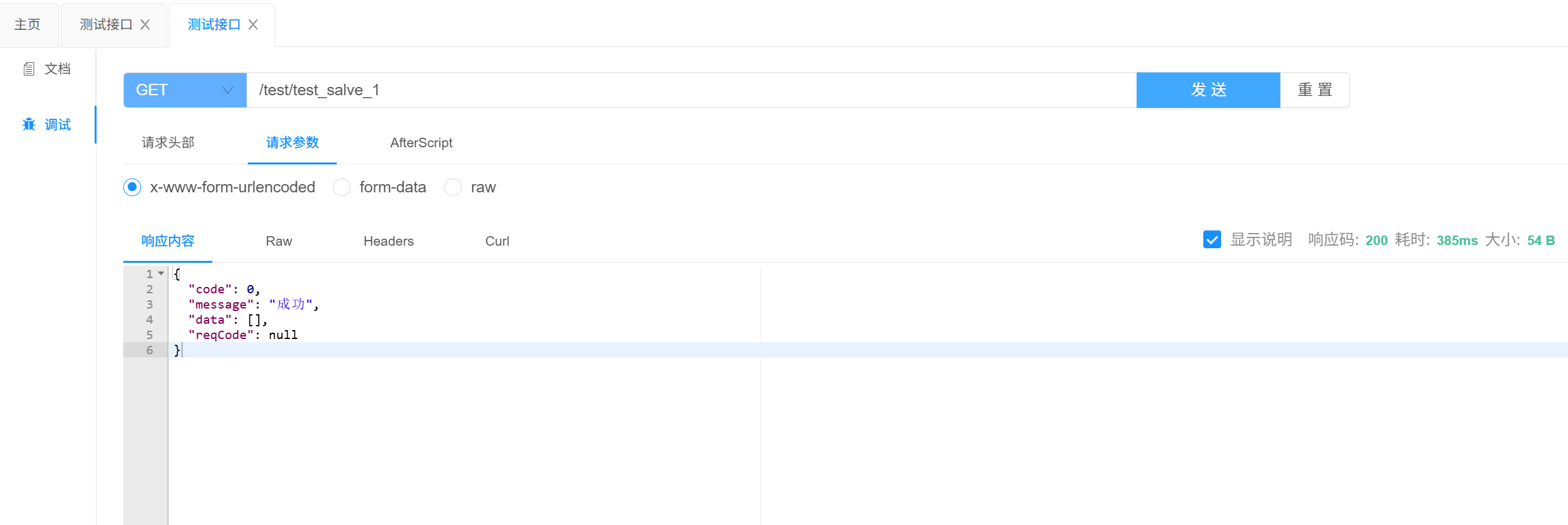
我们再去看看日志看看到底是用的哪一个数据库,我们可以看到我们使用的数据库确实是slave_1,那就说明我们现在的@DS注解生效了

看到这里,想必你已经学会了多数据源的使用了,然而最最最重点的来了!请细细看我的操作:
我们现在创建两个新的实现类分别是:
@Slf4j
@Service
@RequiredArgsConstructor
public class TestMasterServiceImpl {
private final TestMapper testMapper;
@DS("master")
public List<Product> select(){
// 1. 查询原表所有数据
QueryWrapper<Product> queryWrapper = new QueryWrapper<>();
// 可选:添加过滤条件,例如只复制状态为有效的数据
// queryWrapper.eq("status", 1);
List<Product> originalList = testMapper.selectList(queryWrapper);
log.info("查询到原始数据共{}条,准备执行插入", originalList.size());
return originalList;
}
}
@Slf4j
@Service
@RequiredArgsConstructor
public class Slave_1ServiceImpl {
private final TestMapper testMapper;
@DS("slave_1")
public void insertInto(List<Product> originalList){
// 3.插入数据到slave_1
int insertCount = testMapper.insert(originalList.get(0));
log.info("数据插入完成,成功插入{}条,原始数据共{}条", insertCount, originalList.size());
}
}
接下来我们在我们刚才的TestServiceImpl中注入这两个实现类,同时新增方法,最终的代码如下:
@Slf4j
@Service
@RequiredArgsConstructor(onConstructor_ = @Autowired)
public class TestServiceImpl implements TestService {
private final TestMapper testMapper;
private final Slave_1ServiceImpl slave_1Service;
private final TestMasterServiceImpl testMasterService;
@Override
public List<Product> test() {
// 1. 查询所有数据(无分页)
List<Product> allList = testMapper.selectList(null);
log.info("查询到所有数据,共{}条", allList.size());
return allList;
}
@Override
@DS("slave_1")
public List<Product> testSlave_1() {
List<Product> allList = testMapper.selectList(null);
log.info("在Slave_1数据库中查询到所有数据,共{}条", allList.size());
return allList;
}
/**
* 查询所有数据并插入数据库(可用于数据复制)
* 注意:实际场景需根据业务处理主键冲突问题
*/
@Override
public void copyAllData() {
List<Product> originalList = testMasterService.select();
if (originalList.isEmpty()) {
log.warn("未查询到任何数据,无需执行插入");
return;
}
slave_1Service.insertInto(originalList);
}
}
解释一下这段代码的主要是从master数据库中查数据,然后插入第一条到slave_1数据库中,我们来来看看是否可以操作成功!

我们现在可以看到出现了报错,我们去日志中看看是什么原因
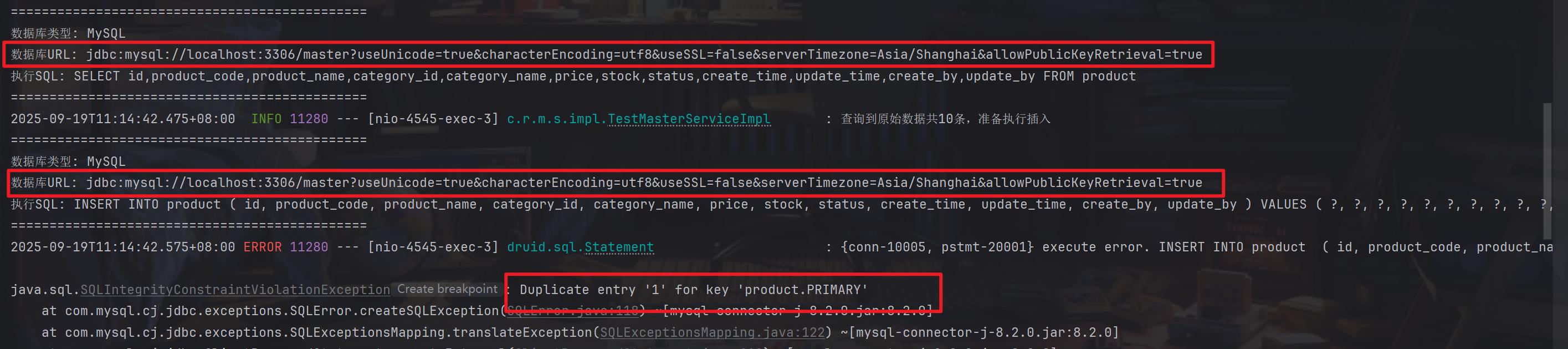
从日志中我们可以看到两次操作都是链接的同一个数据库,而我们在创建数据的时候设置了主键,数据库要求主键唯一,但是我们插入两条一摸一样的数据就出现了主键冲突的报错。那让我么来解决一下
我们需要修改刚才新增的方法,然后修改成下面的样子
/**
* 查询所有数据并插入数据库(可用于数据复制)
* 注意:实际场景需根据业务处理主键冲突问题
*/
@Override
public void copyAllData() {
List<Product> originalList = select();
if (originalList.isEmpty()) {
log.warn("未查询到任何数据,无需执行插入");
return;
}
insertInto(originalList);
}
@DS("master")
public List<Product> select(){
return testMasterService.select();
}
@DS("slave_1")
private void insertInto(List<Product> originalList){
slave_1Service.insertInto(originalList);
}
修改完之后我们在去knife4j中去看看能不能成功:
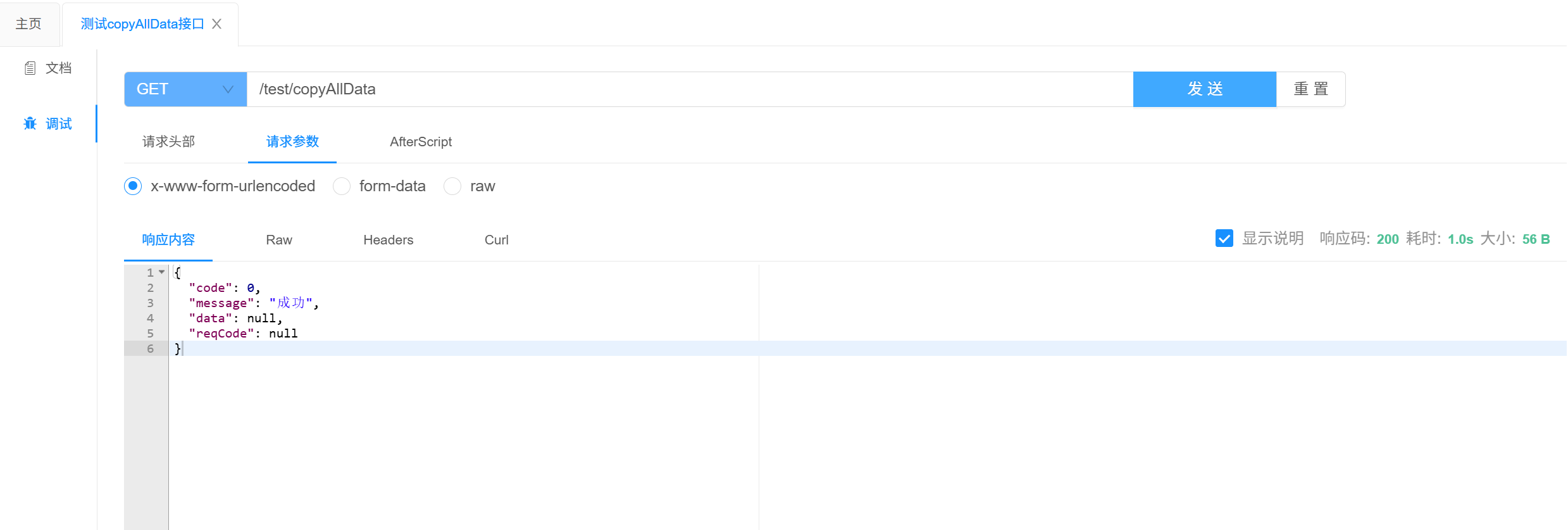
可以看到是操作成功的,那现在我们再去看看日志,到底是操作的哪一个数据库

从日志中我们就可以看到他操作的是两个不通的数据库,那么就说明之前的那种方法是不可行的,操作多数据库需要让每次数据库操作都原子化。
原因: 当一个方法中存在操作多个数据的时候我们需要对每一个不通的数据库操作都需要单独抽取一个方法,并在对应的方法上加上@DS注解,如果说把所有的数据库操作都合并在一个方法里面默认是会去走Master数据库的,无论你在Service层写多少@DS注解都是没用的,你需要在调用他的地方加上注解
注意事项
默认数据源:在配置文件中通过
primary: master指定了默认数据源为master@DS注解使用:
- 可以标注在类上,指定该类所有方法使用的数据源
- 可以标注在方法上,指定该方法使用的数据源
- 方法上的注解会覆盖类上的注解
多数据源操作:
- 当一个方法中需要操作多个数据源时,需要将不同数据源的操作抽取到不同的方法中
- 每个方法单独添加@DS注解指定数据源
- 不能在一个方法中直接执行多个不同数据源的操作,否则会默认使用主数据源
日志查看:通过我们实现的拦截器,可以在控制台清晰地看到每条SQL执行时使用的数据源信息
通过以上配置和代码,我们就可以在SpringBoot3项目中轻松实现多数据源的管理和使用了。这种方式对于实现读写分离、数据分片等场景非常有用。
# SpringBoot3 多数据源配置与实战指南的更多相关文章
- Spring Boot 揭秘与实战(二) 数据存储篇 - 数据访问与多数据源配置
文章目录 1. 环境依赖 2. 数据源 3. 单元测试 4. 源代码 在某些场景下,我们可能会在一个应用中需要依赖和访问多个数据源,例如针对于 MySQL 的分库场景.因此,我们需要配置多个数据源. ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- 大数据存储:MongoDB实战指南——常见问题解答
锁粒度与并发性能怎么样? 数据库的读写并发性能与锁的粒度息息相关,不管是读操作还是写操作开始运行时,都会请求相应的锁资源,如果请求不到,操作就会被阻塞.读操作请求的是读锁,能够与其它读操作共享,但是当 ...
- 《SDN核心技术剖析和实战指南》2.3 OF-CONFIG配置管理协议小结
OpenFlow协议定义了交换机和控制器交换数据的方式和规范,但并没有定义如何配置和管理必需的网络参数和网络资源,OF-CONFIG的提出就是为了对OpenFlow提供配置管理支持.如下图所示,OF- ...
- 项目重构之数据源配置与优化:log4j 配置数据库连接池Druid,并实现日志存储到数据库
作者:泥沙砖瓦浆木匠网站:http://blog.csdn.net/jeffli1993个人签名:打算起手不凡写出鸿篇巨作的人,往往坚持不了完成第一章节. 交流QQ群:[编程之美 365234583] ...
- Springboot多数据源配置--数据源动态切换
在上一篇我们介绍了多数据源,但是我们会发现在实际中我们很少直接获取数据源对象进行操作,我们常用的是jdbcTemplate或者是jpa进行操作数据库.那么这一节我们将要介绍怎么进行多数据源动态切换.添 ...
- 新书推荐《再也不踩坑的Kubernetes实战指南》
<再也不踩坑的Kubernetes实战指南>终于出版啦.目前可以在京东.天猫购买,京东自营和当当网预计一个星期左右上架. 本书贴合生产环境经验,解决在初次使用或者是构建集群中的痛点,帮 ...
- 【RabbitMQ 实战指南】一 RabbitMQ 开发
1.RabbitMQ 安装 RabbitMQ 的安装可以参考官方文档:https://www.rabbitmq.com/download.html 2.管理页面 rabbitmq-management ...
- 【RabbitMQ 实战指南】一 延迟队列
1.什么是延迟队列 延迟队列中存储延迟消息,延迟消息是指当消息被发送到队列中不会立即消费,而是等待一段时间后再消费该消息. 延迟队列很多应用场景,一个典型的应用场景是订单未支付超时取消,用户下单之后3 ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
随机推荐
- C# 数字(阿拉伯数字)金额转汉字金额 人民币操作类 :转换人民币大小金额。
/// <summary> /// 转换为人民币大写金额形式 /// </summary> /// <param name="Money">金额 ...
- android实现QQ登录界面(大学作业一)
实验项目: QQ登录界面 实验地点: 躬行楼718 实验时间: 2018.10.13 一.实验目的: 1.掌握Android中布局的概念和用法 2.熟练掌握Android中Button.ImageVi ...
- 使用war包安装jenkins
war包下的jenkins是没有自己的配置文件 安装java jenkins必须依赖的 curl -O https://dshvv-1300009960.cos.ap-beijing.myqcloud ...
- katex1-初步使用
安装和使用 csdn和npm均可 加载完成后,自动渲染整个body里的公式 <!DOCTYPE html> <html lang="en"> <hea ...
- 使用rclone将linux服务器上的文件夹同步到nextcloud
最近公司在用nextcloud管理文件,我写了一个python脚本,领导想看中间生成的图片,让我把图片同步到nextcloud上.上网搜了一些方法,最终用rclone实现,以下是实现过程. 服务器版本 ...
- Azure RTOS ThreadX: Introduction to Azure RTOS
https://learn.microsoft.com/en-us/azure/rtos/threadx/ https://learn.microsoft.com/en-us/training/mod ...
- OpenList挂载「夸克网盘」
存储->添加 选择夸克 填写挂载路径 打开并进入自己夸克网盘的网页端 [夸克网盘]夸克网盘PC网页版端入口 进入网盘后按F12进入开发者模式并找到网络模块 Edge.Google等浏览器操作基本 ...
- dynamic-datasource detect druid publicKey,It is highly recommended that you use the built-in encryption method
使用druid-spring-boot-starter 1.2.11作为数据库连接池 + dynamic-datasource-spring-boot-starter 3.4.1作为多数据源支持,并且 ...
- FFmpeg开发笔记(七十八)采用Kotlin+Compose的NextPlayer播放器
<FFmpeg开发实战:从零基础到短视频上线>一书的"第 12 章 FFmpeg的移动开发"介绍了如何使用FFmpeg在手机上播放视频,基于FFmpeg的国产播放器开 ...
- 利用Amazon Bedrock生成AI增强设备维护建议
在制造业中,服务报告中的宝贵见解往往未被充分利用.本文探讨AWS客户如何构建自动化解决方案:通过生成式AI实现海量报告的数字化处理与关键信息提取. 该方案采用Amazon Nova Pro(基于Ama ...