内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证
系列目录
内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法
内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证
内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理
内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
架构图
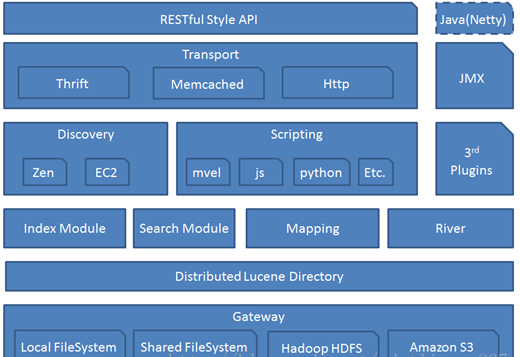
Gateway
代表ElasticSearch索引的持久化存储方式。
在Gateway中,ElasticSearch默认先把索引存储在内存中,然后当内存满的时候,再持久化到Gateway里。当ES集群关闭或重启的时候,它就会从Gateway里去读取索引数据。比如LocalFileSystem和HDFS、AS3等。
DistributedLucene Directory
是Lucene里的一些列索引文件组成的目录。它负责管理这些索引文件。包括数据的读取、写入,以及索引的添加和合并等。
River
代表是数据源。是以插件的形式存在于ElasticSearch中。
Mapping
映射的意思,非常类似于静态语言中的数据类型。比如我们声明一个int类型的变量,那以后这个变量只能存储int类型的数据。
eg:比如我们声明一个double类型的mapping字段,则只能存储double类型的数据。
Mapping不仅是告诉ElasticSearch,哪个字段是哪种类型。还能告诉ElasticSearch如何来索引数据,以及数据是否被索引到等。
Search Moudle
搜索模块
Index Moudle
索引模块
Disvcovery
主要是负责集群的master节点发现。比如某个节点突然离开或进来的情况,进行一个分片重新分片等。
(Zen)发现机制默认的实现方式是单播和多播的形式,同时也支持点对点的实现。以插件的形式存在EC2。
一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Scripting
脚本语言。包括很多。如mvel、js、python等。
定制化功能非常便捷,但有性能问题
Transport
代表ElasticSearch内部节点,代表跟集群的客户端交互。包括 Thrift、Memcached、Http等协议
RESTful Style API
通过RESTful方式来实现API编程。
3rd plugins
第三方插件,(想象一下idea或vscode的插件
Java(Netty)
开发框架。其内部使用netty实现
JMX
监控
部署节点
- master
- index node(也是coordinating node
- coordinating node
三高保证
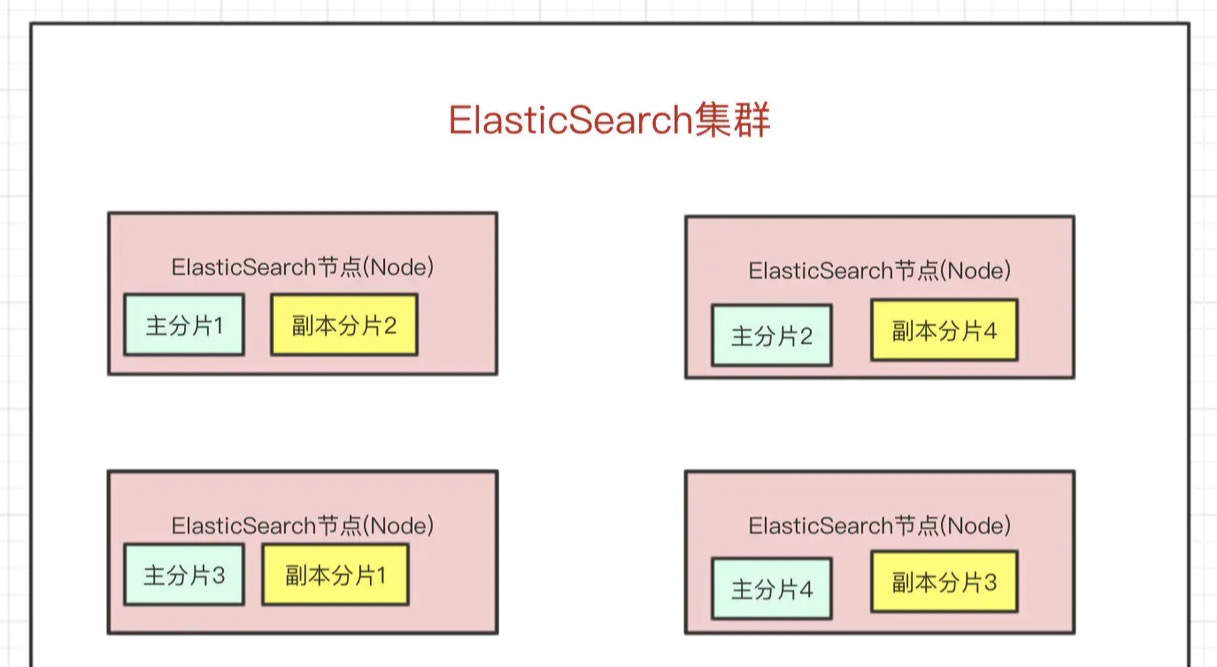
- 一个es集群会有多个es节点
- 在众多的节点中,其中会有一个
Master Node,主要负责维护索引元数据、负责切换主分片和副本分片身份等工作,如果主节点挂了,会选举出一个新的主节点
- 如果某个节点挂了,
Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。
- 如果某个节点挂了,
- es最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。
- 比如现在我集群里边有4个节点,我现在有一个Index,想将这个Index在4个节点上存储,那我们可以设置为4个分片。这4个分片的数据合起来就是Index的数据
- 分片会有主分片和副本分片之分(防止某个节点宕机,保证高可用)
Index需要分为多少个分片和副本分片都是可以通过配置设置的
为什么需要分片?
- 如果一个Index的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个Index存储下来。
- 多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
分词器:
在分词前我们要先明确字段是否需要分词,不需要分词的字段将type设置为keyword,可以节省空间和提高写性能。
1)es的内置分词器
常用的三种分词:Standard Analyzer、Simple Analyzer、whitespace Analyzer
standard 是默认的分析器,英文会按照空格切分,同时大写转小写,中文会按照每个词切分
simple 先按照空格分词,英文大写转小写,不是英文不再分词
Whitespace Analyzer 先按照空格分词,不是英文不再分词,英文不再转小写
2)第三方分词器
es内置很多分词器,但是对中文分词并不友好,例如使用standard分词器对一句中文话进行分词,会分成一个字一个字的。这时可以使用第三方的Analyzer插件,分别是HanLP,IK,Pinyin分词器三种;
- HanLP-面向生产环境的自然语言处理工具包,支持有多重分词配置
两个官网分词例子测试效果,分词效果较内置的分词有很大明显,可以支持中文的词语分词;


- IK分词器:
可以根据粒度拆分
ik_smart: 会做最粗粒度的拆分
ik_max_word: 会将文本做最细粒度的拆分
如果是最细粒度,我是中国人,会被分词为我,是,中国人,中国,国人,相对于Hanlp的分词更加准确和多样;
- PinYin
会对特定的信息进行分词,对用户搜索有更好的体验,该分词会对汉字的首字母进行分词,例如刘德华,会被分词为ldh,张学友,会被分词为zxy,用户根据拼音首字母就可以搜索出对应的特定信息。
内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证的更多相关文章
- 内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
背景及常见术语 背景 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上. Lucene 可以说是当下最先进.高性能.全功能的搜索引擎库- ...
- 内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
1.大数据量的查询效率如何保证: 查询的流程:往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去 最佳的情况 ...
- Elasticsearch的几种架构(ELK,EL,EF)性能对比测试报告
Elasticsearch的几种架构性能对比测试报告 1.前言 选定了Elasticsearch作为存储的数据库,但是还需要对Elasticsearch的基础架构做一定测试,所以,将研究测试报告输出如 ...
- PB级数据实时查询,滴滴Elasticsearch多集群架构实践
PB级数据实时查询,滴滴Elasticsearch多集群架构实践 mp.weixin.qq.com 点击上方"IT牧场",选择"设为星标"技术干货每日送达 点 ...
- [从源码学设计]蚂蚁金服SOFARegistry之程序基本架构
[从源码学设计]蚂蚁金服SOFARegistry之程序基本架构 0x00 摘要 之前我们通过三篇文章初步分析了 MetaServer 的基本架构,MetaServer 这三篇文章为我们接下来的工作做了 ...
- ElasticSearch——冷热(hot&warm)架构部署
背景 最近在做订单数据存储到ElasticSearch,考虑到数据量比较大,采用冷热架构来存储,每月建立一个新索引,数据先写入到热索引,通过工具将3个月后的索引自动迁移到冷节点上. ElasticSe ...
- EFK教程 - ElasticSearch高性能高可用架构
通过将elasticsearch的data.ingest.master角色进行分离,搭建起高性能+高可用的ES架构 作者:"发颠的小狼",欢迎转载与投稿 目录 ▪ 用途 ▪ 架构 ...
- EFK-2:ElasticSearch高性能高可用架构
转载自:https://mp.weixin.qq.com/s?__biz=MzUyNzk0NTI4MQ==&mid=2247483811&idx=1&sn=a413dea65f ...
- elasticsearch从入门到出门-06-剖析Elasticsearch的基础分布式架构
这个图来自中华石杉:
- Plan B
王兴曾经说过: 2019 年是过去 10 年中最差的一年,也是未来 10 年中最好的一年. 之前我希望王兴预判错了,但现在我发现这位掌控着生活消费类数据的大佬应该不是扯淡. 今年的内部和外部环境真的很 ...
随机推荐
- Java统计list集合中重复的元素
本题目能够从宏观上理解list.set.map三大集合的特点: 解决思路是:使用一个map,key用来记录list中的数据,我们知道set集合不允许元素重复,正好在map的jdk8的api中有一个ke ...
- vue,js直接导出excel,xlsx的方法,XLSX_STYLE 行高设置失效的问题解决,冻结窗体修改支持
1.先安装依赖:xlsx.xlsx-style.file-saver三个包 npm install xlsx xlsx-style file-saver 出现错误: This relative mod ...
- 3.21 Linux PATH环境变量及作用(初学者必读)
在讲解 PATH 环境变量之前,首先介绍一下 which 命令,它用于查找某个命令所在的绝对路径.例如: [root@localhost ~]# which rm /bin/rm [root@loca ...
- 这可能是最好的Spring教程!即便无基础也能看懂的入门Spring,仍在持续更新。
开启这样一个系列的原因 这一段时间都在学spring,但是在学习的过程中一直都很难找到一个通俗易懂,又带了学习体系的文章教程,很多地方都不懂,需要自己去慢慢查询和理解,感觉学起来很耗时,所以我自己就像 ...
- linux 自动输入密码脚本避免密码确认
有时候需要执行一个小脚本,就把一部分命令集合起来,我们可以使用 && 或者 .sh 脚本换行. 而有些时候涉及权限需要输入密码就出现了一些客户端会卡在输密码的界面让用户输入 脚本会暂停 ...
- 人形机器人-强化学习算法-PPO算法的实现细节是否会对算法性能有大的影响.
PPO算法是强化学习算法中目前应用最广的算法,虽然这个算法是2017年发表的,但是至今在整个AI领域下的agent子领域中这个算法都是最主要的强化学习算法(至少目前还没有之一),这个算法尤其在Chat ...
- 一个包含了 50+ C#/.NET编程技巧实战练习教程
DotNetExercises介绍 DotNetGuide专栏C#/.NET/.NET Core编程技巧练习集:C#/.NET/.NET Core编程常用语法.算法.技巧.中间件.类库.工作业务实操练 ...
- Vscode之常用插件
code runner 可以直接在编辑器中运行代码,查看结果,非常方便,一键运行. PHP Intelephense PHP代码提示工具,支付代码提示.查找定义.类搜索等功能,非常强大. php de ...
- Javascript 粘贴板
1.前言 本节讲述如何封装一个操作粘贴板的方法 原理:选中某个Dom元素(比如文本域),执行区域复制命令即可. 相关API:document.execCommand():该方法允许运行命令来操纵可编辑 ...
- Vue.js 过渡 & 动画
1.前言 Vue动画/过渡的本质: 在通过v-if/v-show指令插入/移除/显示/隐藏某个标签元素时,在这个标签上包裹一个transition标签,Vue会为这个标签动态添加css类名,为这些类名 ...