深度学习基础理论————DeepSpeed
DeepSpeed原理
DeepSpeed 是由微软开发的一种深度学习优化库,专为高性能训练和推理而设计,尤其适用于大规模深度学习模型(如 GPT 系列、BERT 等)。它通过一系列技术和优化策略,帮助研究者和开发者高效利用硬件资源,实现快速训练、降低内存使用以及提升推理速度。
正如其官方描述那样:

Image From: https://github.com/microsoft/DeepSpeed
Deepspeed作为一种显存优化技术,那么就会有一个问题:模型训练显存都被谁占用了?
参考论文(https://arxiv.org/pdf/1910.02054)中的描述在一个1.5B的GPT-2模型参数量为3G(半精度)但是一块32G的显卡可能无法训练下来,这是因为显存都被 模型状态 以及 剩余状态(Residual Memory Consumption)
模型状态显存占用
主要指的是:优化器状态,梯度,模型参数。比如说在训练过程中一般都会选择使用Adam作为一种优化器进行使用,而在Adam计算过程中就会存储两部分内容:1、动量(上一轮梯度累计);2、二阶动量(存储梯度平方的滑动平均值)。如何去避免这部分结果对显存占用的影响,就提出了 混合精度训练(用FP16存储和计算梯度及优化器状态)
比如说:用Adam作为优化器在混合精度下训练参数量为\(\Phi\)的模型显存占用:1、一部分用来存储FP16的参数以及梯度:\(2\Phi, 2\Phi\);2、另外一部分需要存储优化器状态(FP32存储:模型参数,动量,二阶动量):\(4\Phi, 4\Phi, 4\Phi\)。那么显存占用上就有:\(2+ 2+ 4+ 4+ 4=16\Phi\)。那么回到上面提到的1.5B的GPT-2至少需要:\(1.5 \times 16=24G\)
剩余状态显存占用
这部分主要指的是: 除了模型状态之外的显存占用,包括激活值(activation)(可以通过Activation checkpointing减少)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)
了解模型训练过程中显存占用之后再去了解DeepSpeed中核心内容ZeRO(按照论文中表述作者是分了两部分介绍:ZeRO-DP和ZeRO-R分别去优化上面两部分显存占用)
ZeRO-DP原理
主要是通过切分(partitioning)的方式来减少 模型状态显存占用
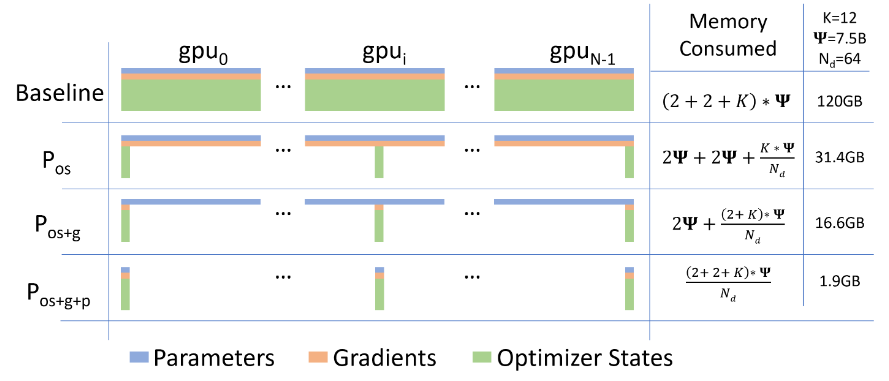
第一种方式为\(P_{OS}\):对优化器的状态进行切分,将\(N\)块GPU上每块只存储\(\frac{1}{N}\),那么最后显存占用(按上面的显存分析为例)就为:\(4\Phi+ \frac{12\times \Phi}{N}\)
第二种方式为\(P_{OS+g}\)也就是在对优化器切分的基础上补充一个对梯度的切分,那么显存占用上就变成为:\(2\Phi+ \frac{(2+ 12)\times \Phi}{N}\)
第三种方式为\(P_{OS+g+p}\)也就是对模型状态三个都进行切分,显存占用为:\(\frac{4\Phi+ 12\Phi}{N}\)
对于上面3种方式显存减少上分别为:\(4\text{x}, 8\text{x}, N\)(其中N表示的为设备数量)
进一步理解上面3个操作
Image From: https://zhuanlan.zhihu.com/p/618865052
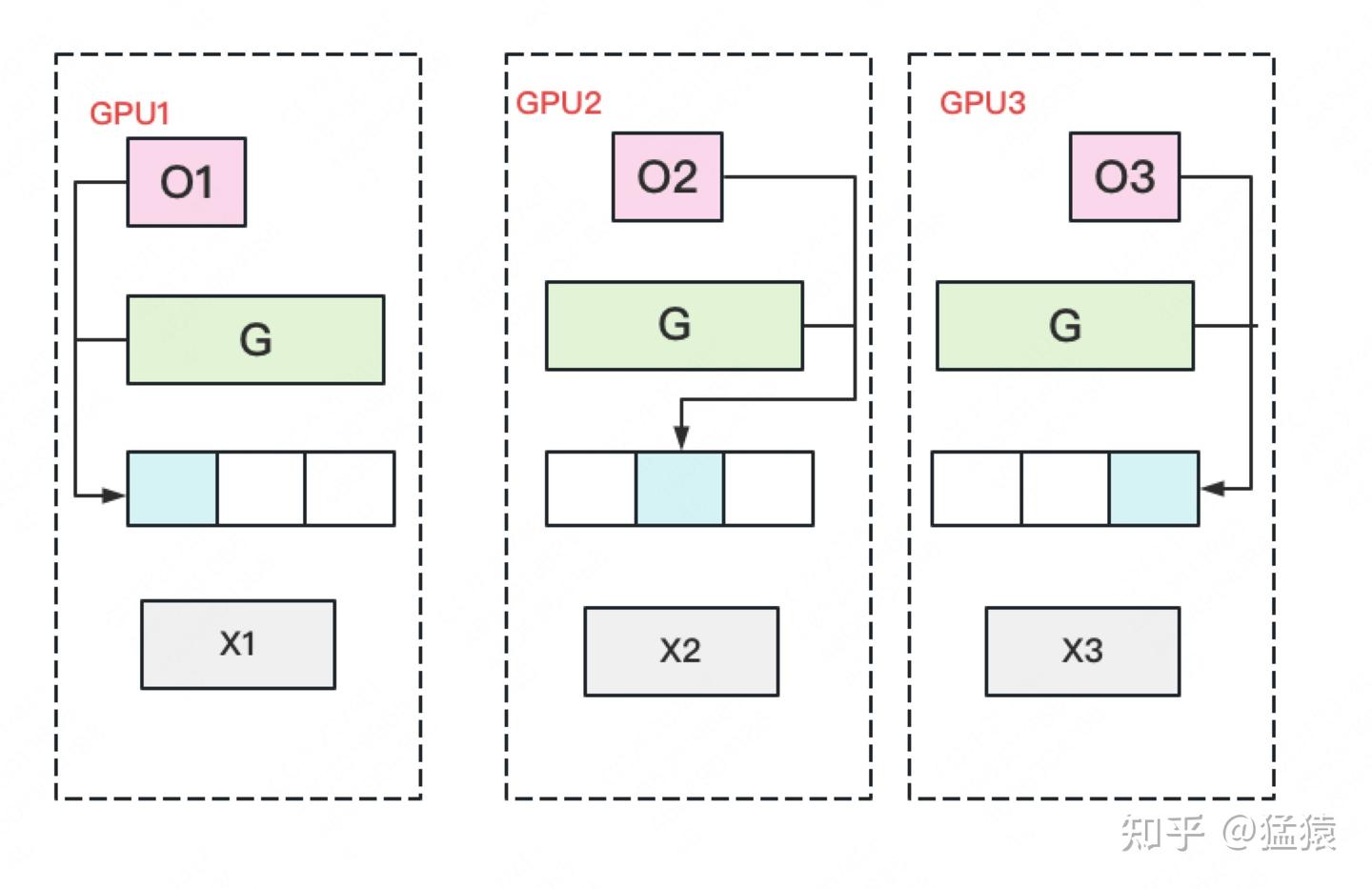
第一种方式\(P_{OS}\)
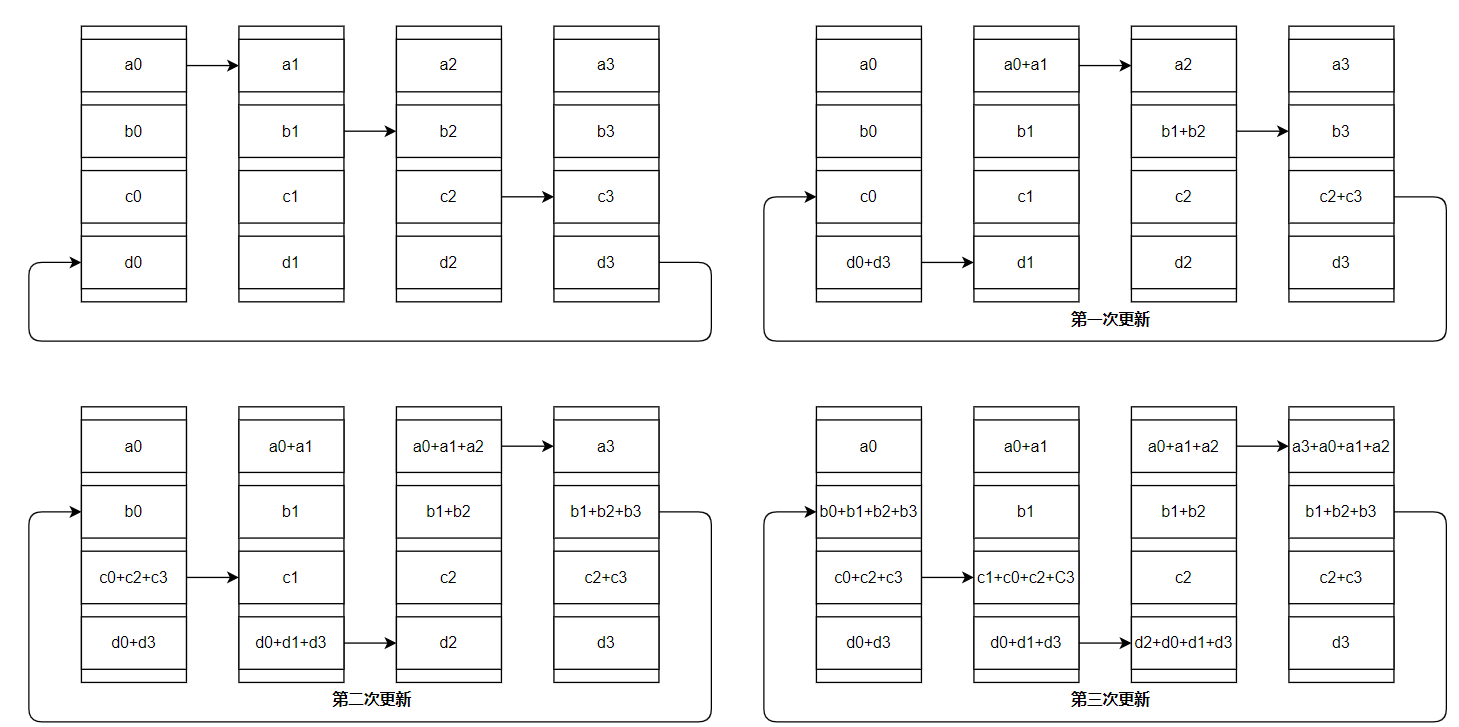
因为会将优化器状态切分,那么在3个不同设备上分别存储3分优化器状态(o1, o2, o3),对于这3部分优化器(因为优化器最后还是去“作用”到梯度上),分别对各自的梯度进行优化,但是会有一个问题:每块GPU上存储的是 一部分优化器状态,那么对于每份优化器也只能去优化各自的参数,每次更新需要通过 All-Gather 操作合并梯度,完成优化器状态更新
第二种方式\(P_{OS+g}\)
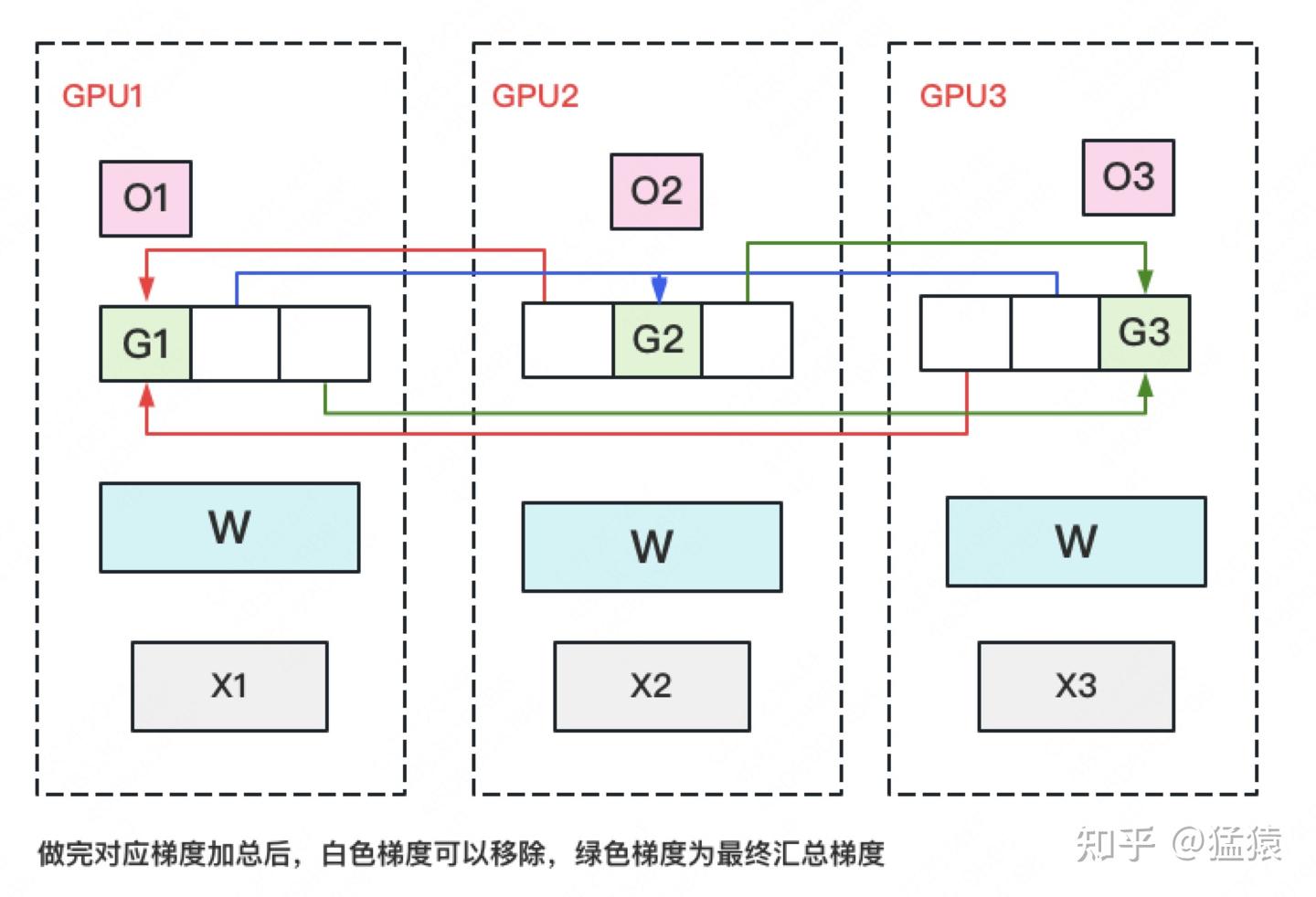
在进行前向+反向传播之后,得到完整的梯度,因为要实现梯度拆分,那么就对梯度进行reduce-scatter对于不同的GPU就会存储不同的梯度(g1, g2, g3白色的就会剔除掉)前向和反向传播需要通过 All-Gather 和 All-Reduce 操作同步梯度和参数
第三种方式为\(P_{OS+g+p}\)
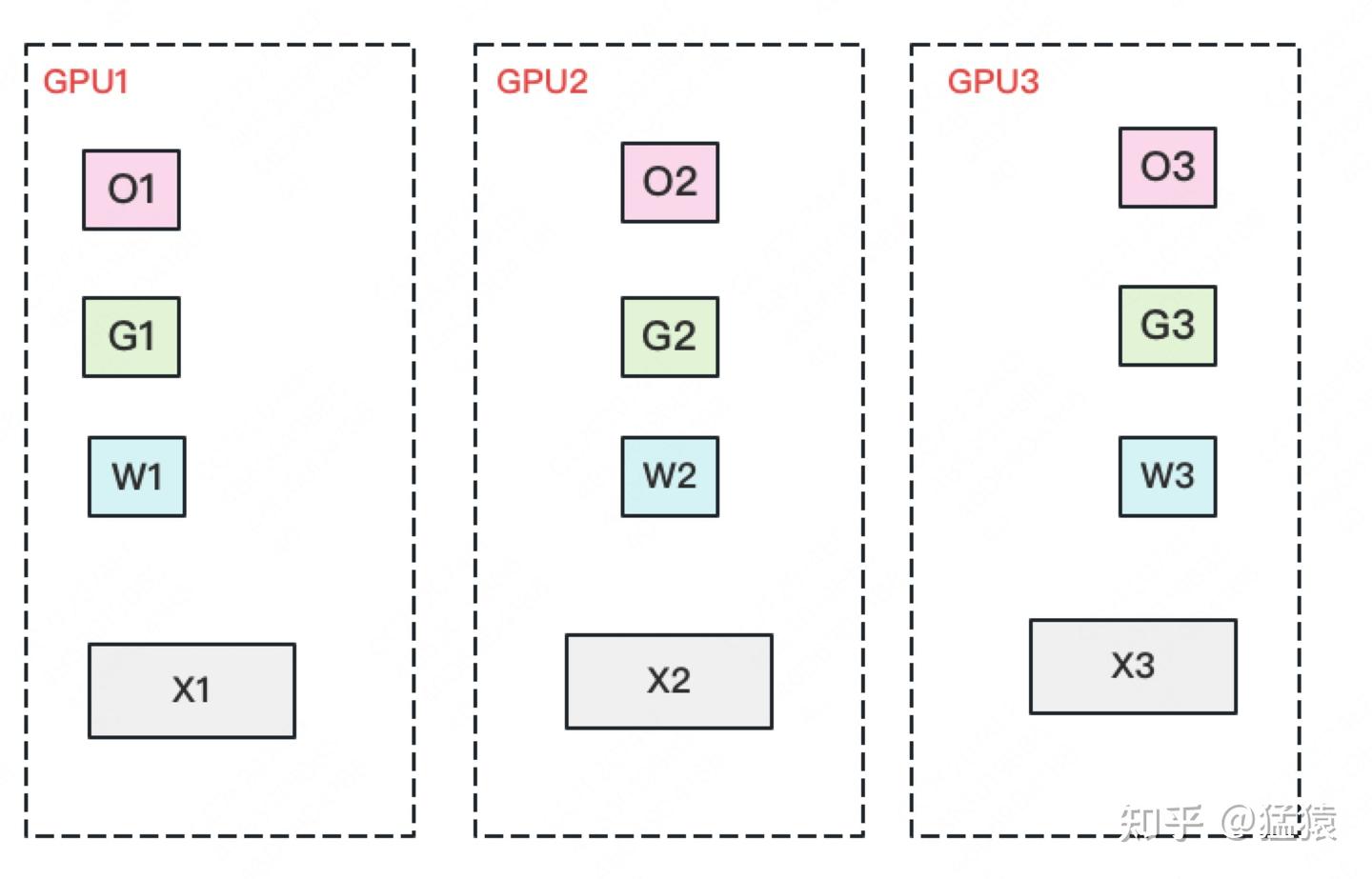
通过 All-Gather和 Reduce-Scatter 高效完成参数同步和更新。
总的来说:ZeRO-DP是一种 用完就丢 的套路,计算时候是完整内容,但是使用完之后就丢掉
补充1:
All-Gather,All-Reduce,reduce-scatter什么意思?
All-Gather:将每个设备上的数据片段收集起来并广播到所有设备上。最终,每个设备都会拥有所有设备的数据片段比如说4个GPU分别存储不同的值:\(GPU_i: i(i=1,2,3,4)\)通过
all-gather那么不同GPU值为\(GPU_i: [1,2,3,4]\)
reduce-scatter:将数据分片并执行 聚合,然后将结果分发给每个设备。每个设备最终只保留聚合后的部分结果比如说4个GPU分别存储不同的值:\(GPU_i: [i_1, i_2, i_3, i_4](i=1,2,3,4)\)通过
reduce-scatter(假设为按照加法聚合)那么不同GPU值为\(GPU_1: [1_1, 2_1, 3_1, 4_1]...\)
All-Reduce:用于在所有设备之间对数据进行 聚合(Reduce) 和 广播(Broadcast)。每个设备都会执行相同的聚合操作,并最终持有相同的聚合结果比如说4个GPU分别存储不同的值:\(GPU_i: i(i=1,2,3,4)\)通过
all-reduce(假设为sum)那么不同GPU值为\(GPU_i: 10\)
Ring-ALLReduce操作:
第一阶段,通过reduce-sactter传递参数通过3次参数更新之后,这样就会出现不同设备上都会有一个都具有参数\(a_i+ b_i+ c_i+ d_i\)那么下一阶段就是通过
all-gather将不同设备上参数广播到不同设备最后实现参数都实现更新。补充2:通信量和传统的数据并行之间有无区别?
这部分描述来自论文(https://arxiv.org/pdf/1910.02054)中的描述:
传统的数据并行方式:传统的DDP主要使用的是Ring AllReduce在通信量上为:\(2\Phi\)(主要来自两部分:)
\(P_{OS} \text{和} P_{OS+g}\)通信量:\(2\Phi\),以后者为例:因为每部分设备只保留了部分梯度信息,因此首先需要通过reduce-scatter操作(\(\Phi\))在梯度都通一之后需要对所有的参数进行更新(\(\Phi\))
\(P_{OS+g+p}\):\(3\Phi\)。前向传播过程中每个设备都只保存了部分参数,因此需要对设备之间进行一次参数广播,在前向操作结束之后,将其他参数删除掉(比如\(GPU_i\)接受了\(i+1,...,n\)的参数,那么就将这部分参数删除)此部分通信量为:\(\frac{\Phi \times N}{N}=\Phi\),类似的反向传播还需要再来一次,梯度还需要进行reduce-scatter

ZeRO-R原理
1、对于激活值的占用。通过\(P_a\):Partitioned Activation Checkpointing通过分区+checkpointing方式
2、对于临时缓冲区。模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行AllReduce,解决办法就是预先创建一个固定的缓冲区,训练过程中不再动态创建,如果要传输的数据较小,则多组数据bucket后再一次性传输,提高效率
3、对于显存碎片。显存出现碎片的一大原因是时候gradient checkpointing后,不断地创建和销毁那些不保存的激活值,解决方法是预先分配一块连续的显存,将常驻显存的模型状态和checkpointed activation存在里面,剩余显存用于动态创建和销毁discarded activation
DeepSpeed代码
Deepspeed代码也比较简单,首先安装deepspeed:pip install deepspeed。使用deepspeed之前一般先去初始化,代码如下:
def initialize(args=None,
model: torch.nn.Module = None,
optimizer: Optional[Union[Optimizer, DeepSpeedOptimizerCallable]] = None,
model_parameters: Optional[torch.nn.Module] = None,
training_data: Optional[torch.utils.data.Dataset] = None,
lr_scheduler: Optional[Union[_LRScheduler, DeepSpeedSchedulerCallable]] = None,
distributed_port: int = TORCH_DISTRIBUTED_DEFAULT_PORT,
mpu=None,
dist_init_required: Optional[bool] = None,
collate_fn=None,
config=None,
mesh_param=None,
config_params=None):
"""初始化 DeepSpeed 引擎。
参数:
args: 一个包含 `local_rank` 和 `deepspeed_config` 字段的对象。
如果提供了 `config`,此参数是可选的。
model: 必填项:在应用任何包装器之前的 nn.Module 类。
optimizer: 可选:用户定义的 Optimizer 或返回 Optimizer 对象的 Callable。
如果提供,将覆盖 DeepSpeed JSON 配置中的任何优化器定义。
model_parameters: 可选:torch.Tensors 或字典的可迭代对象。
指定需要优化的张量。
training_data: 可选:torch.utils.data.Dataset 类型的数据集。
lr_scheduler: 可选:学习率调度器对象或一个 Callable,接收一个 Optimizer 并返回调度器对象。
调度器对象应定义 `get_lr()`、`step()`、`state_dict()` 和 `load_state_dict()` 方法。
distributed_port: 可选:主节点(rank 0)用于分布式训练期间通信的空闲端口。
mpu: 可选:模型并行单元对象,需实现以下方法:
`get_{model,data}_parallel_{rank,group,world_size}()`。
dist_init_required: 可选:如果为 None,将根据需要自动初始化 torch 分布式;
否则用户可以通过布尔值强制初始化或不初始化。
collate_fn: 可选:合并样本列表以形成一个小批量的张量。
在从 map-style 数据集中使用批量加载时使用。
config: 可选:可以作为路径或字典传递的 DeepSpeed 配置,
用于替代 `args.deepspeed_config`。
config_params: 可选:与 `config` 相同,为了向后兼容保留。
返回值:
返回一个包含 `engine`, `optimizer`, `training_dataloader`, `lr_scheduler` 的元组。
* `engine`: DeepSpeed 运行时引擎,用于包装客户端模型以进行分布式训练。
* `optimizer`: 如果提供了用户定义的 `optimizer`,返回包装后的优化器;
如果在 JSON 配置中指定了优化器也会返回;否则为 `None`。
* `training_dataloader`: 如果提供了 `training_data`,则返回 DeepSpeed 数据加载器;
否则为 `None`。
* `lr_scheduler`: 如果提供了用户定义的 `lr_scheduler`,或在 JSON 配置中指定了调度器,
返回包装后的学习率调度器;否则为 `None`。
"""
deepspeed具体案例可以查看其官方示例:https://github.com/microsoft/DeepSpeedExamples
具体使用也很简单,因为Deepspeed将各种功能都封装好了,可以直接使用,一个建议Demo如下:
# 首先初始化
model_engine, optimizer, train_loader, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
training_data=train_dataset,
config=config['deepspeed_config'] # 这里的话是直接将deepspeed的设置都存储到一个json文件里面了
)
def train(model_engine, optimizer, train_loader, ...):
...
image = image.to(model_engine.local_rank)
out = model_engine(..)
...
model_engine.backward()
model_engine.step()
...
值得注意的是:
- 1、如果需要访问设备,可以直接用:
model_engine.local_ranl()进行访问即可 - 2、如果再
deepspeed参数(更加多的参数可以参考官方文档:1,2)中设置了 半精度 训练,在数据里面要设定:images.to(model.local_rank).half()
{
"train_batch_size": 512,
"gradient_accumulation_steps": 1,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
}, //开启半精度训练
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [0.9, 0.999],
"eps": 1e-8,
"weight_decay": 0.01
}
}, // 设置优化器
"zero_optimization": {
"stage": 2
} // 指定zero的方式:1,2,3
}
- 3、理论上分析,在显存占用上是 \(P_{OS}<P_{OS+g}<P_{OS+g+p}\) 但是实验过程中会出现相反的情况,参考这部分讨论:1、在使用
deepspeed中的zero设定时,需要保证模型的大小足够大(大小>1B的参数)。于此同时在使用stage=2或者stage=3的时候可以分别指定下面参数:1、reduce_bucket_size,allgather_bucket_size;2、stage3_max_live_parameters,stage3_max_reuse_distance - 4、对于
zero中stage设定,通过结合github上的讨论:
1、stage=2时:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
}
| 参数 | 含义 | 当前值 |
|---|---|---|
stage |
1: 仅优化优化器状态。2: 优化优化器状态和梯度。3: 优化优化器状态、梯度和模型参数。0:普通DDP |
2 |
offload_optimizer |
是否将优化器状态迁移到其他设备(如 CPU 或 NVMe) | { "device": "cpu", "pin_memory": true } |
allgather_partitions |
在每个step结束时,选择用allgather集合通信操作还是一系列的broadcast从所有GPUs收集更新后的参数,一般不需要修改,论文中在分析集合通讯开销时就用了allgather | true |
allgather_bucket_size |
动态收集参数时的最大通信块大小(字节)。较大值:提高效率但增加显存压力。较小值:减少显存压力但增加通信次数。 | 2e8 (200MB) |
overlap_comm |
尝试在反向传播期间并行进行梯度通信 | true |
reduce_scatter |
是否启用 reduce-scatter 操作,将梯度分片和通信合并以降低显存需求和通信负担 | true |
reduce_bucket_size |
reduce-scatter 操作的最大通信块大小(字节)。较大值:提高效率但增加显存压力。较小值:减少显存压力但增加通信次数 | 2e8 (200MB) |
contiguous_gradients |
是否将梯度存储为连续内存块,以减少显存碎片并提升梯度更新效率 | true |
2、stage=3时:
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
}, //是否将优化器状态迁移到CPU
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
}
| 参数 | 含义 | 当前值 |
|---|---|---|
stage |
1: 仅优化优化器状态。2: 优化优化器状态和梯度。3: 优化优化器状态、梯度和模型参数。0:普通DDP |
3 |
offload_optimizer |
是否将优化器状态迁移到其他设备(如 CPU 或 NVMe)。优化器状态的存储可以迁移到 CPU 以释放显存。 | { "device": "cpu", "pin_memory": true } |
offload_param |
是否将模型参数迁移到其他设备(如 CPU)。类似于优化器状态,模型参数可以迁移到 CPU 以降低显存压力。 | { "device": "cpu", "pin_memory": true } |
overlap_comm |
尝试在反向传播期间并行进行梯度通信 | true |
contiguous_gradients |
是否将梯度存储为连续的内存块,启用后减少显存碎片,提高梯度更新效率。 | true |
sub_group_size |
设置参数分组大小,用于分配和通信的优化。大的值可以减少通信次数,适用于更大规模的模型 | 1e9 |
reduce_bucket_size |
设置 reduce-scatter 操作的最大通信块大小(字节)。如果设置为 auto,DeepSpeed 会自动调整。 |
auto |
stage3_prefetch_bucket_size |
为 stage 3 优化中的预取操作设置桶大小。如果设置为 auto,DeepSpeed 会自动调整。 |
auto |
stage3_param_persistence_threshold |
在 stage 3 中设置模型参数持久化的阈值。如果设置为 auto,DeepSpeed 会自动调整。 |
auto |
stage3_max_live_parameters |
保留在 GPU 上的完整参数数量的上限 | 1e9 |
stage3_max_reuse_distance |
是指将来何时再次使用参数的指标,从而决定是丢弃参数还是保留参数。 如果一个参数在不久的将来要再次使用(小于 stage3_max_reuse_distance),可以保留以减少通信开销。 使用activation checkpointing时,这一点非常有用 |
1e9 |
stage3_gather_16bit_weights_on_model_save |
在保存模型时是否收集 16 位权重。启用时可以将权重收集为 16 位格式,降低存储开销。 | true |
3、其他
实际参数过程中,可能还需要设置train_batch_size,gradient_accumulation_steps(梯度累计次数),optimizer(优化器选择)
代码
参考
1、https://arxiv.org/pdf/1910.02054
2、https://zhuanlan.zhihu.com/p/513571706
3、https://zhuanlan.zhihu.com/p/618865052
4、https://zhuanlan.zhihu.com/p/504957661
5、https://deepspeed.readthedocs.io/en/latest/initialize.html#
6、https://www.deepspeed.ai/docs/config-json/#batch-size-related-parameters
7、https://zhuanlan.zhihu.com/p/630734624
深度学习基础理论————DeepSpeed的更多相关文章
- AI人工智能 机器学习 深度学习 学习路径及推荐书籍
要学习Pytorch,需要掌握以下基本知识: 编程语言:Pytorch使用Python作为主要编程语言,因此需要熟悉Python编程语言. 线性代数和微积分:Pytorch主要用于深度学习领域,深度学 ...
- 《TensorFlow深度学习应用实践》
http://product.dangdang.com/25207334.html 内容 简 介 本书总的指导思想是在掌握深度学习的基本知识和特性的基础上,培养使用TensorFlow进行实际编程以解 ...
- 《深度学习原理与TensorFlow实践》喻俨,莫瑜
1. 深度学习简介 2. TensorFlow系统介绍 3. Hello TensorFlow 4. CNN看懂世界 5. RNN能说会道 6. CNN LSTM看图说话 7. 损失函数与优化算法 T ...
- UFLDL深度学习笔记 (一)反向传播与稀疏自编码
UFLDL深度学习笔记 (一)基本知识与稀疏自编码 前言 近来正在系统研究一下深度学习,作为新入门者,为了更好地理解.交流,准备把学习过程总结记录下来.最开始的规划是先学习理论推导:然后学习一两种开源 ...
- 人工智能热门图书(深度学习、TensorFlow)免费送!
欢迎访问网易云社区,了解更多网易技术产品运营经验. 这个双十一,人工智能市场火爆,从智能音箱到智能分拣机器人,人工智能已逐渐渗透到我们的生活的方方面面.网易云社区联合博文视点为大家带来人工智能热门图书 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- [源码解析] 深度学习流水线并行Gpipe(1)---流水线基本实现
[源码解析] 深度学习流水线并行Gpipe(1)---流水线基本实现 目录 [源码解析] 深度学习流水线并行Gpipe(1)---流水线基本实现 0x00 摘要 0x01 概述 1.1 什么是GPip ...
- [源码解析] 深度学习流水线并行 GPipe(3) ----重计算
[源码解析] 深度学习流水线并行 GPipe(3) ----重计算 目录 [源码解析] 深度学习流水线并行 GPipe(3) ----重计算 0x00 摘要 0x01 概述 1.1 前文回顾 1.2 ...
- 使用 PyTorch Lightning 将深度学习管道速度提高 10 倍
前言 本文介绍了如何使用 PyTorch Lightning 构建高效且快速的深度学习管道,主要包括有为什么优化深度学习管道很重要.使用 PyTorch Lightning 加快实验周期的六种 ...
- 深度学习实现案例(Tensorflow、PaddlePaddle)
深度学习实验案例 文章目录 深度学习实验案例 一.基础理论 实验一:自定义感知机 实验二:验证图像卷积运算效果 二.Tensorflow 实验一:查看Tensorflow版本 实验二:Hellowor ...
随机推荐
- 历史性突破:独立开发 .net core 在线客服系统累计处理聊天消息 48 万余条!
业余时间用 .net core 写了一个在线客服系统.我把这款业余时间写的小系统丢在网上,陆续有人找我要私有化版本,我都给了,毕竟软件业的初衷就是免费和分享. 后来我索性就发了一个100%私有化版直接 ...
- 去除tinymce中粘贴的样式
import "tinymce/plugins/paste"; tinymce.init({ ...其他配置, plugins: ["paste"], past ...
- MySQL造数据,批量插入数据脚本
新建表 create table bigdata( name varchar(32), age int(32), createTime datetime); MySQL批量插入数据脚本 #!/bin/ ...
- html中input标签放入小图标
直接上代码 <style type="text/css"> *{ margin: 0; padding: 0; } .box{ width: 200px; positi ...
- 域渗透之利用WMI来横向渗透
目录 前言 wmi介绍 wmiexec和psexec的区别 wmic命令执行 wmiexec.vbs wmiexec.py Invoke-WmiCommand.ps1 前言 上一篇打红日靶场拿域控是用 ...
- python 快速比较大文件的元素异同之处
0x00 问题 0x01 解决方法 0x02 list最多可以存放多少条数据呢? 0x03 集合set的操作 0x00 问题 假如,在有两个大文件分别存储了大量的数据,数据其实很简单就是一堆字符串,每 ...
- ArrayList源码分析(基于JDK1.6)
不积跬步,无以至千里:不积小流,无以成江海.从基础做起,一点点积累,加油! <Java集合类>中讲述了ArrayList的基础使用,本文将深入剖析ArrayList的内部结构及实现原理,以 ...
- Jetson Orin NX烧录+设备树更改?看这一篇就够了!
Jetson Orin NX烧录+设备树更改?看这一篇就够了! 笔者的设备为Jetson Orin NX 16GB + 达妙科技的Orin NX载板 本博客同步发表在CSDN:https://blog ...
- Winform TabControl动态添加TabPage
在Winform中,标签页是我们很难绕开的一个控件,而且,我们经常有动态添加标签页的需求. 这里介绍一个最简单的添加方法: 首先,我们把需要添加的内容做成UserControl,这样,我们就可以在添加 ...
- 使用C#获取文件详情
有对应的需求,需要获取文件的详细信息内容.该页面信息大部分来源于文件的版本信息,使用FileInfo类并不能获取到. VERSIONINFO 资源 - Win32 apps | Microsoft L ...