如何优化和提高MaxKB回答的质量和准确性?
目前 ChatGPT、GLM等生成式人工智能在文本生成、文本到图像生成等在各行各业的都有着广泛的应用,但是由于大模型训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这个导致了在实际应用场景中会发现,通用的基础大模型基本无法满足我们的实际业务需求,普遍都存在着知识的局限性比如专业领域知识缺失,上下文词不达意(一本正经地胡说八道)等。为了解决这些问题,目前主要有两种解决方案:
第一种模型微调(Fine Tune):通过微调更新模型,让模型具备对新知识的理解和认知。
另一种就是RAG(Retrieval Augmented Generation,检索增强生成),将大模型(LLM)与外部知识源检索相结合,提升大模型的问答能力。
而MaxKB就属于RAG范畴,是基于大语言模型的知识库问答系统,那么同样在实际应用中,我们应该如何提高MaxKB回答的质量和准确性?
一、MaxKB实现原理
在回答这个问题之前,我们先了解下MaxKB的实现原理:
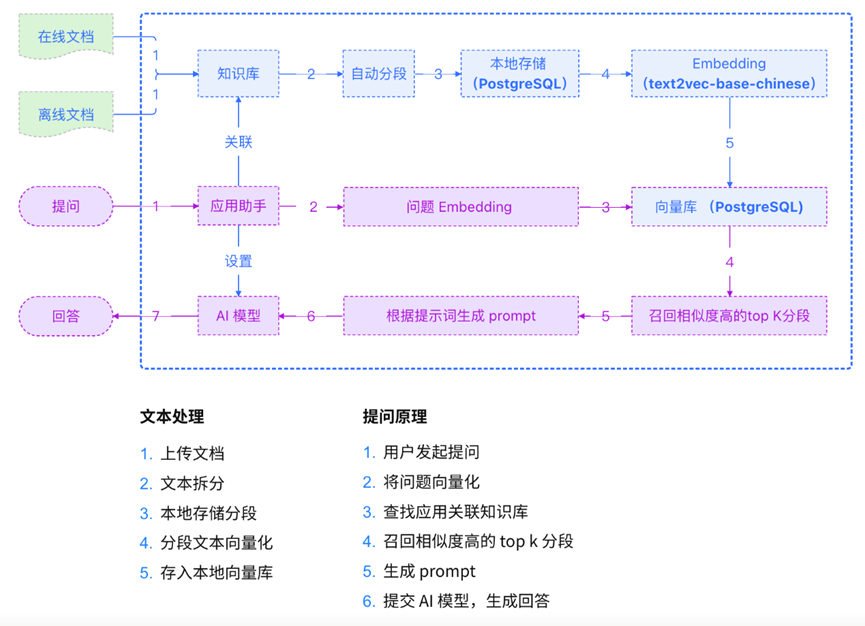
基于上述MaxKB的原理图,我们可以将MaxKB整体流程简单概括如下五点:
1、管理员将知识文档整理后上传MaxKB,MaxKB将文档进行分段存储和向量化;
2、管理员为不同的知识库创建应用,并为应用接入大模型;
3、用户在应用中提问,MaxKB依据用户的问题,检索向量库,并返回满足相似度的TOP分段;
4、MaxKB将返回的TOP分段内容,作为提示词中的一部分,并且询问大模型;
5、大模型依据提示词,最终给用户进行回答。
所以,从概括中我们可以理解,这个里面有几个关键点会影响到MaxKB回答质量和准确性:
- 知识文档的合理分类、分段以及保证文档质量。这个是大模型是否给出准确答案的源头,如果源数据就是错的,那么大模型回答的结果也就可想而知了;
- 合理设置应用的向量检索的相似度值和TOP分段数。理论上相似度值越高,TOP分段越少,那么向量检索返回的越准确,但是这样设置也很容易造成向量检索不到数据,会导致回答“知识库中查询不到答案”;
- 进行提示词优化,不同的提示词直接影响到模型生成的输出。好的提示词能够引导模型产生更准确、更相关且更富有创造性的回答;
- 采用更大、更新的大模型引擎来提供更好的性能和回答效果。
二、具体如何优化?
那么如何在MaxKB中如何针对上诉的点进行优化呢?同样主要分为以下几个方面进行:
2.1 知识文档优化层面
知识文档的第一要点就是要保证知识的准确性。比如面向法律条文的知识文档,需要筛选出已经撤销或者更新的条文条款;面向信息技术的,需要筛选因为技术的迭代已经不适用的方案等等。这个是最重要的,不同的知识库类型需要不同的专业知识人员处理。
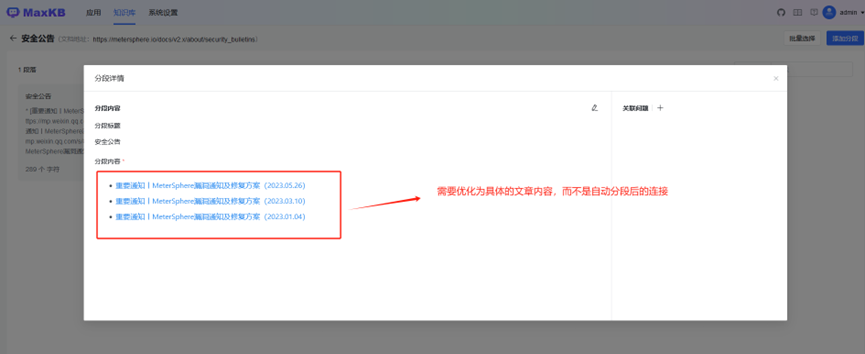
第二点,文本规范化处理,去除文本中特殊字符、不相关的信息、重复内容或冗余的内容。比如下图关于MeterSphere知识库中就有些无关的信息(因为在MaxKB中采用了自动爬取MeterSphere在线文档),可以在MaxKB关闭或者删除。

比如自动化分段中有些内容不合理的,需要人工处理:
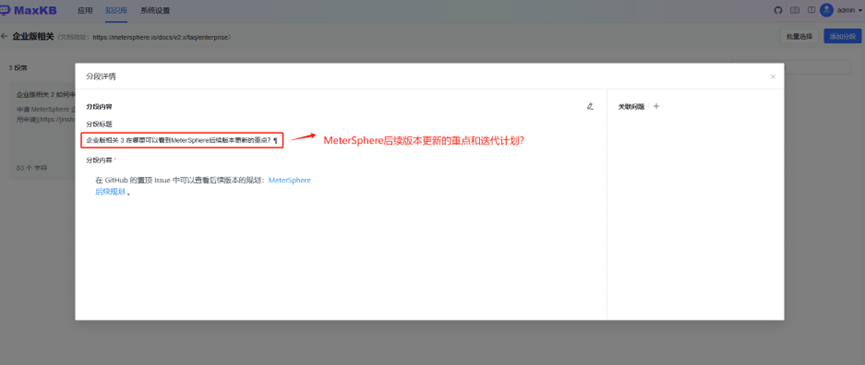
比如针对不合理的内容进行修改优化:
第三点,依据知识类型,将文档归类划分。需要合理地划分不同知识主题的文档,再MaxKB中按照不同知识的类型进行划分不同的知识库进行存储,比如下图分为了MeterSphere知识库和DataEase知识库。企业可以根据现有文档数据,在MaxKB中划分财务知识库、销售知识库、人事知识库、IT知识库等等。

第四点,合理的进行文档分段、分块。需要将文档拆分为一定大小的块,但还能保证文档表达的含义(因为我们知道,MaxKB最终是需要将向量检索到的数据,嵌入到提示词中输入大模型,但是不同的大模型输入的token是有一定容量的,而且如果输入过多,会影响大模型回答的效率和速度,还有更多的资源消耗,如果输入过少,有可能就会导致回答不准确或者查询不到知识点)。所以针对不同文档内容,需要进行合理的分段、分块才行。比如针对知识连贯部分采用大分块较为合适(比如详细描述MeterSphere产品特性的多段文本);而对于信息分散,则可以使用小块进行(比如社交媒体帖子)。如果实在无从下手时,128大小字符为一个分块块往往是最佳选择,可以从这个大小作为基准进行测试。
2.2 向量检索优化层面
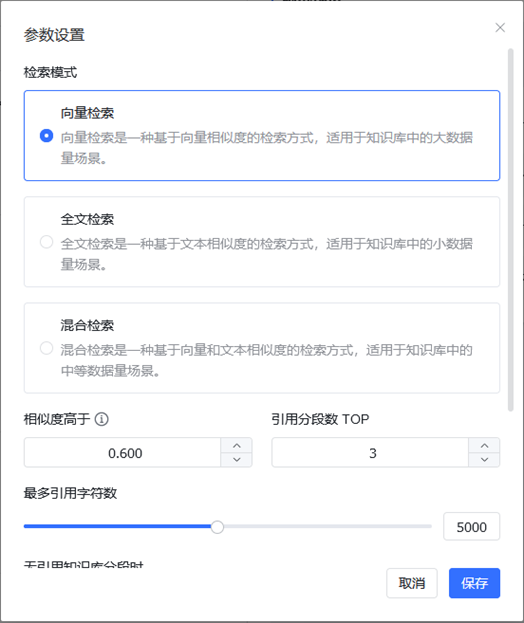
目前MaxKB默认向量检索相似度值为0.6,默认引用分段数 TOP分段为3。我们可以结合知识库的数据量的大小,设置不同的搜索模式和调整相似度值、TOP分段。
比如数据量大的场景,可以采用向量检索;数据量小采用全文检索;数据量中场景采用混合检索;然后基于MaxKB回答的效果,适当的调整检索相似度和引用TOP分段数,以此来实现最佳的回答效果。
2.3 提示词优化层面
优质的提示词能够显著提高大模型回答的准确性,这是因为提示词直接影响模型的思考和回应方式。所以很多时候不同的问答场景需要不同的提示词来引导模型,使其能够更好地适应各种应用场景,如编写诗歌、解答复杂问题或模拟特定角色进行对话等。所以在MaxKB中用户也可以针对不同的知识类型进行提示词优化。默认MaxKB中的提示词如下:

比如,我们针对DataEase知识库进行提示词优化成如下部分:
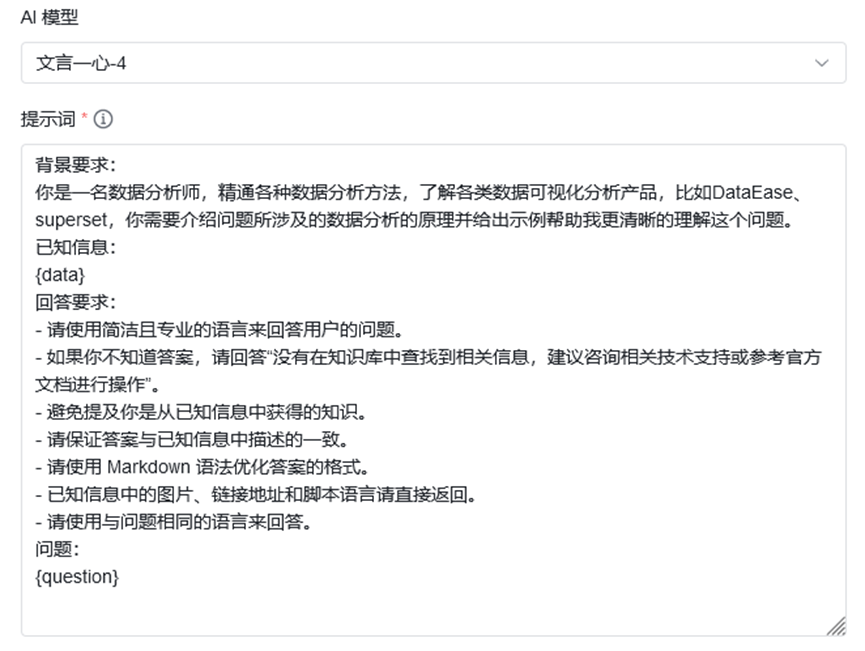
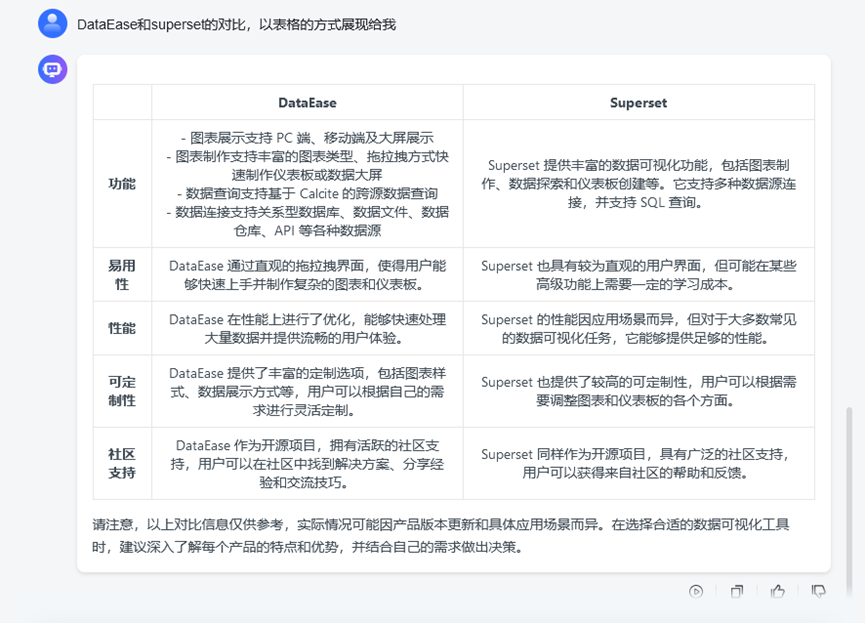
最后通过提示词优化,MaxKB能够给出更加符合我们期望的答案:
2.4 大模型优化层面
MaxKB支持对接主流的大模型,包括本地私有大模型(如 Llama 2)、OpenAI、通义千问、Kimi、Azure OpenAI 和百度千帆大模型等。所以在MaxKB中优化模型最简单的办法就是换更大的接入模型,比如文心一言-3.5模型换成文心一言-4模型,Llama 3-8B换成Llama 3-70B(需要注意的是本地模型参数越多,需要硬件资源也更多)。
第二个办法就是模型微调,但是我们需要了解,模型微调固然效果好,在实际场景中,数据是不停更新的,而模型微调无论是从数据准备、算力资源、微调效果、训练时间等各个角度来看都不是一件简单的工作,也很难保证每次有新数据的产生都进行模型微调,无论财力和时间都不允许,并且有时候微调的效果有时候也不一定理想。
好了,上述就行基于MaxKB进行问答知识库优化的几个方向和要点,你学到了吗?

如何优化和提高MaxKB回答的质量和准确性?的更多相关文章
- Java 性能优化手册 — 提高 Java 代码性能的各种技巧
转载: Java 性能优化手册 - 提高 Java 代码性能的各种技巧 Java 6,7,8 中的 String.intern - 字符串池 这篇文章将要讨论 Java 6 中是如何实现 String ...
- 教你如何提高 PHP 代码的质量
说实话,在代码质量方面,PHP 的压力非常大.通过阅读本系列文章,您将了解如何提高 PHP 代码的质量. 我们可以将此归咎于许多原因,但这肯定不仅仅是因为 PHP 生态系统缺乏适当的测试工具.在本文中 ...
- 如何提高 PHP 代码的质量?第三:端到端 / 集成测试
在本系列的最后一部分,是时候设置端到端 / 集成测试环境,并确保我们已经准备好检查我们工作的质量. 在本系列的前几部分中,我们建立了一个构建工具,一些静态代码分析器,并开始编写单元测试. 为了使我们的 ...
- [MySQL性能优化系列]提高缓存命中率
1. 背景 通常情况下,能用一条sql语句完成的查询,我们尽量不用多次查询完成.因为,查询次数越多,通信开销越大.但是,分多次查询,有可能提高缓存命中率.到底使用一个复合查询还是多个独立查询,需要根据 ...
- CSS性能分析,如何优化CSS提高性能
不负十年后的自己,共勉! 前端性能优化一直是一个比较热门的话题,我们总是在尽我们最大的努力去,提高我们的页面性能,比如减少HTTP请求,利用工具对资源进行合并压缩,脚本置底,避免重复请求,css sp ...
- 使用 Django-debug-toolbar 优化Query 提高代码效率
一段程序执行效率慢,除了cpu计算耗时外,还有一个很重要的原因是SQL的Duplicated过多,使用Django-debug-toolbar能够快速找出哪些地方的SQL可以优化,提高程序执行效率 1 ...
- Linux(Centos )的网络内核参数优化来提高服务器并发处理能力【转】
简介 提高服务器性能有很多方法,比如划分图片服务器,主从数据库服务器,和网站服务器在服务器.但是硬件资源额定有限的情况下,最大的压榨服务器的性能,提高服务器的并发处理能力,是很多运维技术人员思考的问题 ...
- 团队代码中Bug太多怎么办?怎样稳步提高团队的代码质量
最近负责的Android APP项目,由于团队成员变动.界面改版导致代码大幅修改等原因,产品发布后屡屡出现BUG导致的程序崩溃. 经过对异常统计和代码走读,BUG主要集中在空指针引起的NullPoin ...
- 如何提高 PHP 代码的质量?第二部分 单元测试
在“如何提高 PHP 代码的质量?”的前一部分中:我们设置了一些自动化工具来自动检查我们的代码.这很有帮助,但关于我们的代码如何满足业务需求并没有给我们留下任何印象.我们现在需要创建特定代码域的测试. ...
- Web前段优化,提高加载速度 css
前言: 在同样的网络环境下,两个同样能满足你的需求的网站,一个"Duang"的一下就加载出来了,一个纠结了半天才出来,你会选择哪个?研究表明:用户最满意的打开网页时间是2-5秒, ...
随机推荐
- CDS标准视图:日期迁移视图 I_ShiftedCalendarDate
视图名称:I_ShiftedCalendarDate 视图类型:带参数的视图 时间期间偏移量单位(P_TimePeriodOffsetUnit): D代表天 W代表周 M代表月 Q代表季 Y代表年 期 ...
- VS2022 没有MAUI模板的解决方法
原来是要安装 VS 2022 Preview 就是预览版.正式版还没有MAUI..... 以下的尝试都是蛋疼,没有卵用. 命令行窗口输入:dotnet workload install maui VS ...
- Restful、SOAP、RPC、SOA、微服务之间的区别-copy
什么是Restful Restful是一种架构设计风格,提供了设计原则和约束条件,而不是架构,而满足这些约束条件和原则的应用程序或设计就是 Restful架构或服务. 主要的设计原则: 资源与URI ...
- 微服务实战系列(七)-网关springcloud gateway-copy
1. 场景描述 springcloud刚推出的时候用的是netflix全家桶,路由用的zuul,但是据说zull1.0在大数据量访问的时候存在较大性能问题,2.0就没集成到springcloud中了, ...
- w3cschool-微信小程序开发文档-云开发
微信小程序云开发 介绍 2020-07-24 16:19 更新 开发者可以使用云开发开发微信小程序.小游戏,无需搭建服务器,即可使用云端能力. 云开发为开发者提供完整的原生云端支持和微信服务支持,弱化 ...
- C#/.NET/.NET Core技术前沿周刊 | 第 21 期(2025年1.6-1.12)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录.追踪C#/.NET/.NET Core领域.生态的每周最新.最实用.最有价值的技术文章.社区动态.优质项目和学习资源等. ...
- APSI - 1
最近在看[Labeled PSI from Homomorphic Encryption with Reduced Computation and Communication]的论文,看完后头大,现结 ...
- Docker的启停与配置等
Docker测试题 一.选择题(每题5分) 1.关于Docker 安装的表述错误的是(C) A.Docker支持在Windows.Linux.MacOS等系统上安装 B.CentOS安装Docker有 ...
- 接口性能测试---locust脚本编写(一)
本文分享自天翼云开发者社区<接口性能测试---locust脚本编写(一)>,作者:丁****乐 一.安装 locust是用python编写的一款开源接口性能测试工具,以python3为例, ...
- 【1】JobManager启动
一.Flink底层通信技术 Akka + Netty Akka:它是基于协程的,基于scala的偏函数 Netty:相比更加基础一点,可以为不同的应用层通信协议(RPC,FTP,HTTP等)提供支持 ...