SQL 强化练习(三)
继续来练习 sql 查询, 似乎也没有什么窍门, 跟着写多了, 自然就记住了, 这个帖子, 来记录一波, 模糊查询 like; 四表关联查询: 老师名 -> 老师id -> 课程id -. 学生 id -> 学生表
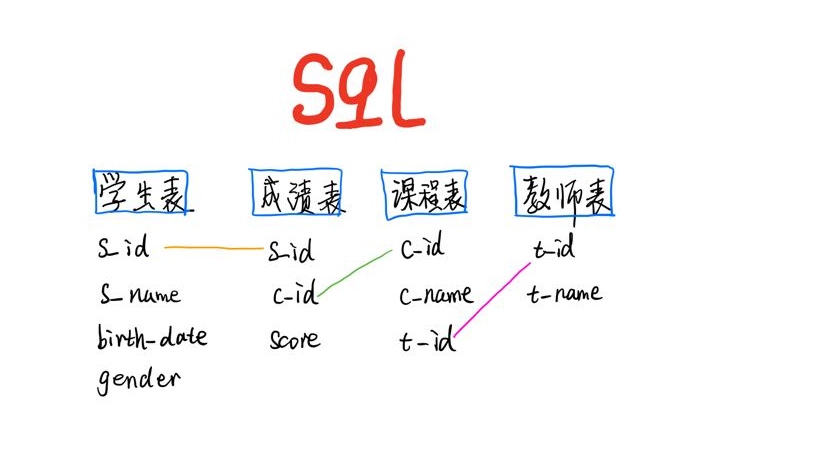
表关系
需求01
查询姓 “王” 的学生个数;
查询姓名中包含 "王" 的学生信息;
查询姓名为 3个字的学生姓名和性别;
查询姓张的老师中, 不重名的老师个数;
分析
主要是关于模糊查询这块, 在 mysql 中, 即关于关键字 “like" 和 通配符 ”%, - “ 等的应用。
select
count(s_id) as 老师人数
from student
where
s_name like "王%";
+--------------+
| 老师人数 |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
-- % 匹配任意
select *
from student
where s_name like "%王%";
+------+--------+------------+--------+
| s_id | s_name | birth_date | gender |
+------+--------+------------+--------+
| 0001 | 王二 | 1989-01-01 | 男 |
+------+--------+------------+--------+
1 row in set (0.00 sec)
-- "_" 下划线表示匹配单个字符
select
s_name,
gender
from student
where s_name like "___";
+-----------+--------+
| s_name | gender |
+-----------+--------+
| 胡小适 | 男 |
+-----------+--------+
1 row in set (0.00 sec)
-- distinct 去重
select
count(distinct s_name) as "王姓不重名老师数"
from student
where s_name like "王%";
+--------------------------+
| 王姓不重名老师数 |
+--------------------------+
| 1 |
+--------------------------+
1 row in set (0.00 sec)
需求02
查询没有选过 "仲尼" 老师课的学生的学号, 姓名, 性别.
分析
涉及 教师表, 课程表, 成绩表, 学生表 . 一步步查出来即可
面向过程
先根据老师 "姓名" -> 老师 id -> 课程 id -> 选课 score 拿到 学生 id -> 学生表信息
a. 通过老师姓名 "仲尼" 从 教师表 拿 "教师id"
select
t_id
from teacher
where t_name = "仲尼";
+------+
| t_id |
+------+
| 0002 |
+------+
1 row in set (0.00 sec)
b. 通过 "教师id" 从 课程表 拿到 "课程id"
select
c_id
from course
where
t_id = (
select
t_id
from teacher
where t_name = "仲尼"
);
+------+
| c_id |
+------+
| 0001 |
+------+
c. 通过 "课程id" 从 成绩表 拿到 "学生id" (课程: 学生 是 1:n)
select
s_id
from score
where c_id = (
select
c_id
from course
where
t_id = (
select
t_id
from teacher
where t_name = "仲尼"
)
);
+------+
| s_id |
+------+
| 0001 |
| 0003 |
+------+
d. 通过 "学生id" 从 学生表 拿到 学生的学号, 姓名, 性别 (没选 就 not in )
-- 没有选就 not in
select
s_id as "学号",
s_name as "姓名",
gender as "性别"
from student
where s_id not in (
select
s_id
from score
where c_id = (
select
c_id
from course
where
t_id = (
select
t_id
from teacher
where t_name = "仲尼"
)
)
);
+--------+--------+--------+
| 学号 | 姓名 | 性别 |
+--------+--------+--------+
| 0002 | 星落 | 女 |
| 0004 | 油哥 | 男 |
+--------+--------+--------+
2 rows in set (0.00 sec)
这种思路, 感觉跟咱变成用的, 面向过程是一样的思维, 比较注重逻辑关系. 我个人是比较喜欢的, 逻辑性和推理是我一直比较感兴趣的话题, 尤其是数学公式推到, 我觉得非常的有意思. 当然这里我能写出这个一步步的逻辑呢, 主要还是基于对表字段的熟悉和其关联关系, 表关系 (1:1, 1:n, n:n )等的掌握, 这里逻辑, 即:
老师姓名 -> 老师id -> 课程 id -> 学生id -> 学生信息
tips: 成绩表中, 学生 与 选课 是 1: n 的关系哦
但业务中, 往往对表字段, 关联不那么熟悉 , 说业务嘛, 了解业务就已经是非常头疼的事情了, 还有一个表字段有很多啥的, 搞起来则麻烦对于理解这些逻辑关联关系.
连接查询写法
思路还是一样的, 差别就是, 我个人感觉, 这是一种 "面向对象" 的写法 , 当然不是咱真正的面向对象, 就是 表拼接 .
分析
关键是在于 "选课" 这张表, 即成绩表, 它的字段有:
学号, 课程号, 课程名称, 成绩
有了 "课程号" 不就知道了 "教师id" 和 "教师姓名" 了吗 (left join 或 inner join 都行)
学号, 课程号, 课程名称, 成绩; 教师id, 教师姓名
最后, 根据 "学号" 不就知道学生信息了嘛 (inner join)
学名, 姓名,性别;学号, 课程号, 课程名称, 成绩; 教师id, 教师姓名
-- 注意别名的使用
select
s.*,
c.*,
t.*
from score as s
-- 成绩表 关联 课程表
inner join course as c
on
s.c_id = c.c_id
-- 课程表 关联 教师表
inner join teacher as t
on
c.t_id = t.t_id
where
t.t_name = "仲尼";
+------+------+-------+------+--------+------+------+--------+
| s_id | c_id | score | c_id | c_name | t_id | t_id | t_name |
+------+------+-------+------+--------+------+------+--------+
| 0001 | 0001 | 80 | 0001 | 语文 | 0002 | 0002 | 仲尼 |
| 0003 | 0001 | 80 | 0001 | 语文 | 0002 | 0002 | 仲尼 |
+------+------+-------+------+--------+------+------+--------+
其实 , 咱只要用到 s_id 就可以了, 以 s_id 作为条件 去查出相应的 学生信息即可
select
s_id,
s_name,
gender
from student
where
s_id not in (
select
s.s_id
from score as s
-- 成绩表 关联 课程表
inner join course as c
on
s.c_id = c.c_id
-- 课程表 关联 教师表
inner join teacher as t
on
c.t_id = t.t_id
where
t.t_name = "仲尼"
);
+------+--------+--------+
| s_id | s_name | gender |
+------+--------+--------+
| 0002 | 星落 | 女 |
| 0004 | 油哥 | 男 |
+------+--------+--------+
2 rows in set (0.00 sec)
表关联查询的这种方式, 我在真是的业务中是用的蛮多的, 毕竟我去了解每个表的字段, 逻辑什么的还是比较麻烦的, 一个表的字段是很多的, 我通常就给他们都拼接起来一张大表, 然后再筛选. 核心还是在思考这3个核心的问题:
- 涉及 哪几张表 和 相关的字段大概有哪些?
- 表之间的关键 KEY 是什么?
- 表与表的关系 (1:1; 1:n , n:n)
小结
- 模糊查询 like 的使用
- 多表关联查询, 可以面向过程, 和类似面向对象的方式 (逻辑, 表连接)
SQL 强化练习(三)的更多相关文章
- 你真的会玩SQL吗?三范式、数据完整性
你真的会玩SQL吗?系列目录 你真的会玩SQL吗?之逻辑查询处理阶段 你真的会玩SQL吗?和平大使 内连接.外连接 你真的会玩SQL吗?三范式.数据完整性 你真的会玩SQL吗?查询指定节点及其所有父节 ...
- SQL总结(三)其他查询
SQL总结(三)其他查询 其他常用的SQL,在这里集合. 1.SELECT INTO 从一个表中选取数据,然后把数据插入另一个表中.常用于创建表的备份或者用于对记录进行存档. 语法: SELECT c ...
- SQL优化(三)—— 索引、explain分析
SQL优化(三)—— 索引.explain分析 一.什么是索引 索引是一种排好序的快速查找的数据结构,它帮助数据库高效的查询数据 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据 ...
- SQL强化(三) 自定义函数
---恢复内容开始--- Oracle中我们可以通过自定义函数去做一些逻辑判断,这样可以减少查询语句,提高开发效率 create -- 创建自定义函数 or replace -- 有同名函数就替换, ...
- SQL分页语句三方案
方法一: SELECT TOP 页大小 * FROM table1 WHERE id NOT IN ( SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY id ...
- SQL初级第三课(下)
我们续用第三课(上)的表 辅助表 Student Course Score Teacher Sno ...
- SQL语句汇总(三)——聚合函数、分组、子查询及组合查询
聚合函数: SQL中提供的聚合函数可以用来统计.求和.求最值等等. 分类: –COUNT:统计行数量 –SUM:获取单个列的合计值 –AVG:计算某个列的平均值 –MAX:计算列的最大值 –MIN:计 ...
- SQL SERVER2005 的三种复制类型概述
一.事务复制 事务性复制通常从发布数据库对象和数据的快照开始.创建了初始快照后,接着在发布服务器上所做的数据更改和架构修改通常在修改发生时(几乎实时)便传递给订阅服务器.数据更改将按照其在发布服务器上 ...
- SQL Server的三种物理连接之Loop Join(一)
Sql Server有三种物理连接Loop Join,Merge Join,Hash Join, 当表之间连接的时候会选择其中之一,不同的连接产生的性能不同,理解这三种物理连接对性能调优有很大帮助. ...
- SQL 获取 IDENTITY 三种方法 SCOPE_IDENTITY、IDENT_CURRENT 和 @@IDENTITY的区别
-------总结:用SCOPE_IDENTITY()函数靠谱 @@IDENTITY (Transact-SQL) 返回最后插入的标识值的系统函数. 备注 在一条 INSERT.SELECT INTO ...
随机推荐
- 保持Android Service在手机休眠后继续运行的方法
保持Android Service在手机休眠后继续运行的方法 下面小编就为大家分享一篇保持Android Service在手机休眠后继续运行的方法,具有很好的参考价值,希望对大家有所帮助.一起跟随 ...
- 《HelloGitHub》第 107 期
兴趣是最好的老师,HelloGitHub 让你对开源感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣.入门级的开源项目. github.com/521xueweihan/HelloG ...
- Educational Codeforces Round 175 (Rated for Div. 2) 比赛记录
Educational Codeforces Round 175 (Rated for Div. 2) 比赛记录 比赛连接 手速场,上蓝场,但是有点唐,C 想错了写了半个多小时,想到正解不到 \(10 ...
- 写了个 CasaOS/ZimaOS 内网穿透的远程访问插件(不是 frp 或者 nps),欢迎大家测试使用
插件正在提交,应该过几天就会进入市场了. 插件访问效果大概如下: casaOS 远程界面 如果大家想先行测试可以手动下载 pr 的文件进行测试. 使用 插件会提供一个二维码,使用OpenIoThub ...
- IOS 内付 asp.net mvc 服务器端验证
上代码: public class AppStorePayApp { public int VerifyReceipt(string receipt, out string product_id, o ...
- Easyexcel(5-自定义列宽)
注解 @ColumnWidth @Data public class WidthAndHeightData { @ExcelProperty("字符串标题") private St ...
- Manus爆火,是硬核还是营销?
相信这两天小伙伴们应该被Manus刷屏了,铺天盖地的体验解读文章接踵而来,比如「数字生命卡兹克」凌晨爆肝的热文:「一手体验首款通用Agent产品Manus」.从公众号.朋友圈.抖音.央媒,都能看到Ma ...
- 数据、信息、知识、智慧:AI时代我们该如何思考?
时代的浪潮滚滚向前,AI技术的演进正悄然改变着我们认知世界和创造价值的方式.从数据.信息到知识.智慧,从大数据到大模型,从单一智能体到多智能体协作,这是一场深刻的认知革命,也是生产力解放的新纪元. A ...
- delphi获得唯一ID字符串
//这是我三层开发中常用的一个函数,直接调用CreateSortID uses System.Win.ComObj,System.RegularExpressions,System.StrUtils, ...
- StringBuilder的介绍、构造方法及成员方法
1.StringBuilder的介绍 1.StringBuilder是字符串缓冲区,可以认为是一种容器,能装任何类型的数据,但被装入的数据都会变为字符串 如图 无论是什么类型的数据,被装入字符串缓冲区 ...