atomic不是免费午餐
很多初级甚至中级开发会滥用atomic,因为在他们的世界观里atomic比mutex轻量,性能总是优于锁的。
这话不能算错,但有个很重要的前提,那就是原子操作竞争不激烈的时候。
“竞争激烈”是指什么呢,指的是有很多线程在同一个资源上大量执行原子操作的情况。
落在这种情况下原子操作反而会成为性能拖油瓶。我们来看一个经典的原子计数器:
func AddAtomic() uint64 {
var count atomic.Uint64
var wg sync.WaitGroup
for range 10 {
wg.Add(1)
go func() {
for range 100000000 {
count.Add(1)
}
wg.Done()
}()
}
wg.Wait()
return count.Load()
}
代码模拟了10个线程频繁操作计数器的场景。论并发安全这段代码是既简洁又安全的。很多人可能还会觉得这段代码是很高效的,毕竟用了原子操作嘛。
不过别着急,测试性能之前我们再想想还有没有其他做法。考虑到这是一个单向递增的计数器,我们只需要保证每次的加操作最终都能完成,并且因为加法的交换律和结合律,这些操作的相对顺序也可以打乱。换句话说,我们可以不关心counter的中间状态,每个线程自己聚合所有的加操作,最后再一次性加给counter。代码就会变成下面这样:
func AddAtomicLocal() uint64 {
var count atomic.Uint64
var wg sync.WaitGroup
for range 10 {
wg.Add(1)
go func() {
cc := uint64(0)
for range 100000000 {
cc++
}
count.Add(cc)
wg.Done()
}()
}
wg.Wait()
return count.Load()
}
现在每个线程维护自己的计数器,在运行结束统一操作counter。熟悉Java的读者应该能看出来这是LongAdder,唯一的区别是我们没用threadlocal。
两种方法累加的次数都是一样的,而且大部分人都认为原子操作很轻量,那么它们的性能理论上应该不会差太多,方法1稍微慢一点。我们写点性能测试看下:
func BenchmarkAtomic(b *testing.B) {
for b.Loop() {
result := AddAtomic()
if result != 1000000000 {
b.Fatal("error")
}
}
}
func BenchmarkAtomicLocal(b *testing.B) {
for b.Loop() {
result := AddAtomicLocal()
if result != 1000000000 {
b.Fatal("error")
}
}
}
下面是测试结果,分别用go1.24.5在Intel和Apple的机器上进行测试:
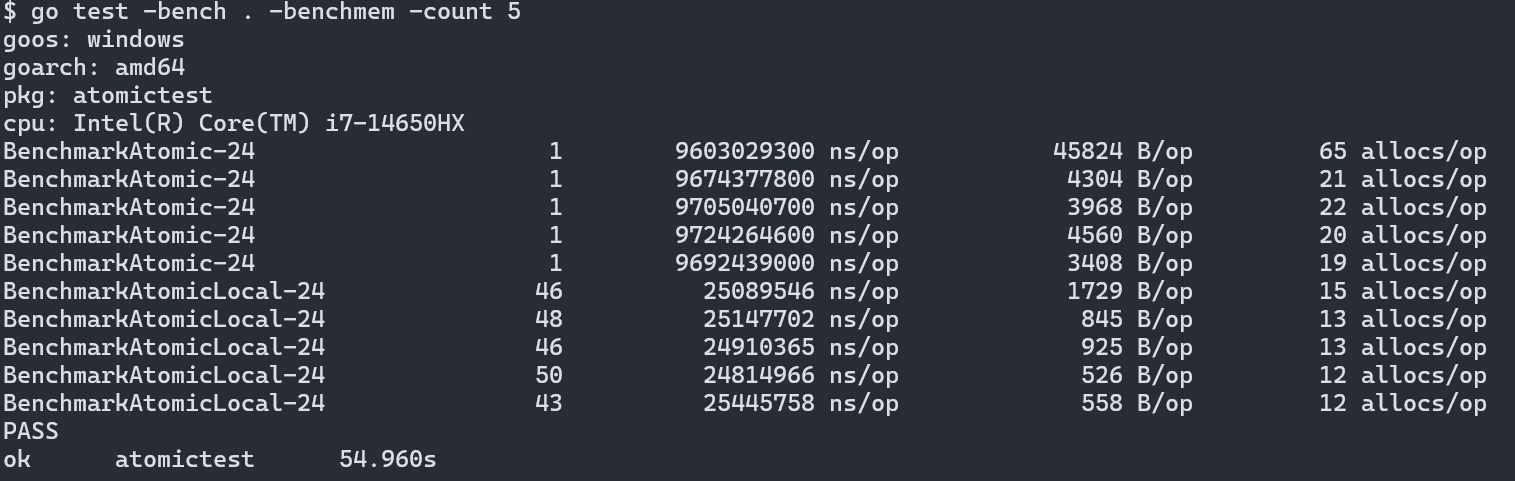
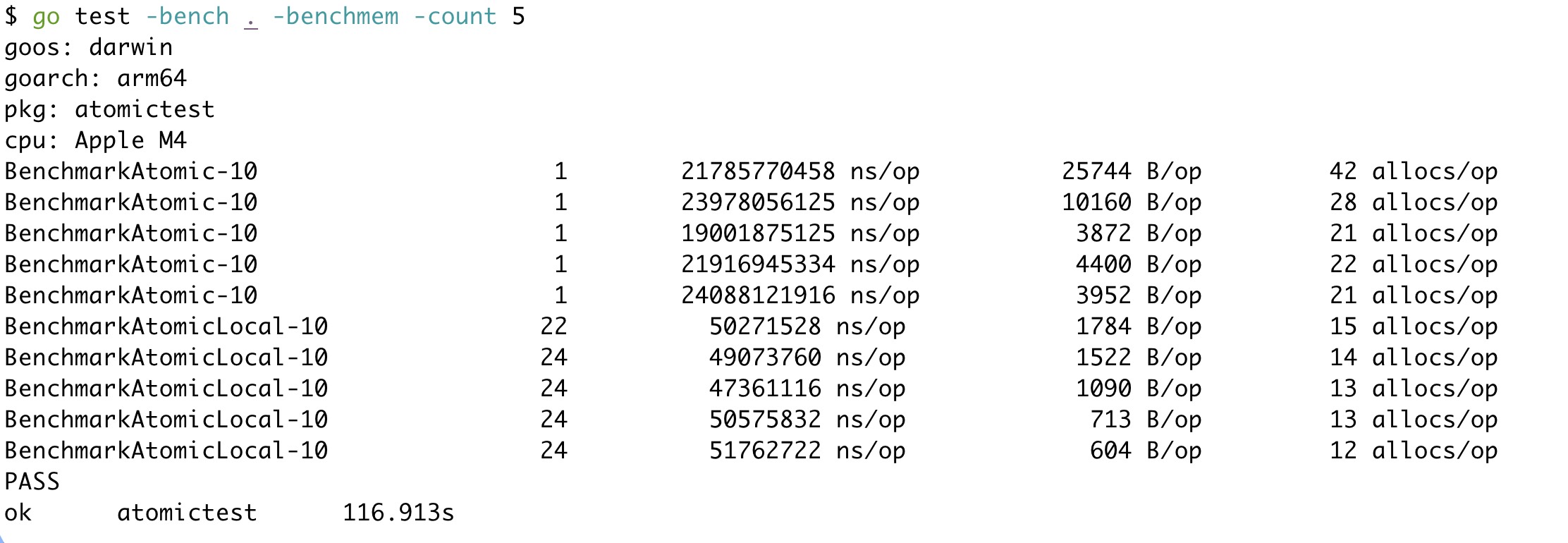
结果出人意料,在两款不同的芯片上,方案1都慢了接近300倍。看似“轻量”的原子操作竟然是性能杀手。
我们可以找个Linux系统用perf分析一下原因。在Linux上两者直接也有百倍的差距。
上面一个样本是方案1的,下面的则是方案2的:
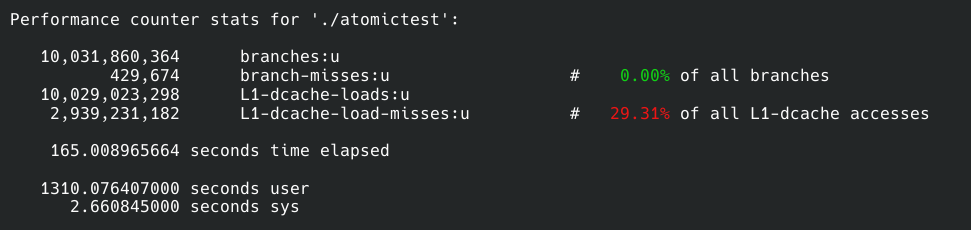
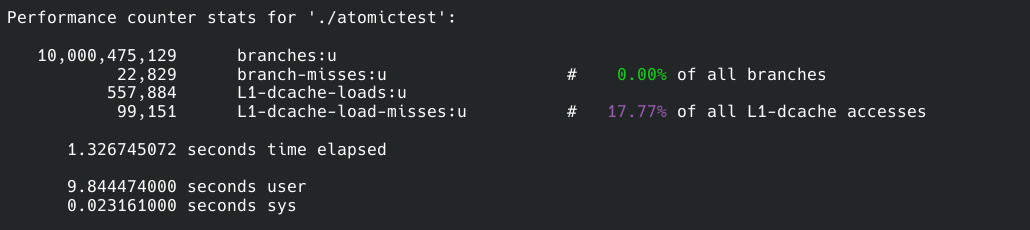
我没有监听全部的性能事件,那样一来会让程序变得很慢,二来对我们重要的只有其中的几个事件,太多的信息会成为杂音。
我们先来看branches和branch-misses,前者是程序运行中一个执行多少分支判断,后者是cpu预执行分支失败的次数,简单地说misses越少程序性能越高。所以两个方案在分支总数差不多的情况下方案2比1的预测失败数量低20倍,所以方案2在这一点上胜出。
接着就是缓存命中率了,这一点无需过多解释,命中率越高性能越好。方案二同样比一高了10%。
然而这两点只能解释一个数量级的差异,但我们现在的差距是300倍。
仔细观察缓存读取次数,我们会惊奇地发现方案1的读取次数是10,029,023,298,100亿次。我们的测试程序也正好运行了累加器函数10次,也是100亿次操作。这是方案2的整整18000倍。
为什么会有这个结果呢?这就是原子操作的缺点之一了:x86和arm上的原子操作都是针对某块内存上的数据进行操作。这意味着不管是原子读还是原子写,都要直接操作内存。现代cpu不会自己直接接触内存,都需要数据先进入cpu的高速缓存才能进行操作。这就是为什么方案1会有如此之高的缓存读取次数。原子操作需要这样的代价,因为共享的资源随时会被修改,因此只能每次从内存中存取最新的数据。
而方案2的累加操作是在线程独立的本地局部变量上进行的,这些操作没必要走内存,可以直接在寄存器上完成。
寄存器和高速缓存的速度差异不同体系结构和厂家的产品大相径庭,但寄存器的速度一定大于等于高速缓存。因此更依赖寄存器的方案2自然会比缓存命中率更低且需要大量操作缓存的方案1快上两个数量级。
除此之外原子操作还带来了另外的副作用,这在perf的报告中没有显现——多个线程频繁修改同一个资源,会带来大量的更新cpu缓存的核间通信以及线程为了原子性可能会出现很多同步操作。核间通信本身有延迟,缓存状态更新后cpu遇到下次的原子读取/写入就得先更新缓存才能执行操作,一来一去慢的可不是一星半点。线程之间的同步则来自于原子操作带来的内存屏障,cpu为了保证能让屏障正常生效,需要让一些cpu核心上的指令等待另一些核心上的指令执行完成,不同的cpu实现这点的方法不同,但也会带来可观的延迟。
所以综合上面三个原因,看似轻量级的原子操作在“竞争激烈”的场景下出现了严重的性能问题。
不过尽管方案2很快,但它也有缺点,那就是counter不会及时更新。在这里我们可以忍受这一点,但也有的场景是无法接受这种延迟的。
总结
atomic不是免费午餐,是要支付使用代价的。除了潜在的性能问题,还会有难以察觉的并发问题。
所以为了追求性能,应该停止滥用atomic。可以适当地像方案2或者Java的LongAdder那样选择一些per-cpu的算法或者数据结构。
atomic不是免费午餐的更多相关文章
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
- JUC学习笔记--Atomic原子类
J.U.C 框架学习顺序 http://blog.csdn.net/chen7253886/article/details/52769111 Atomic 原子操作类包 Atomic包 主要是在多线程 ...
- 原子类java.util.concurrent.atomic.*原理分析
原子类java.util.concurrent.atomic.*原理分析 在并发编程下,原子操作类的应用可以说是无处不在的.为解决线程安全的读写提供了很大的便利. 原子类保证原子的两个关键的点就是:可 ...
- 【iOS atomic、nonatomic、assign、copy、retain、weak、strong】的定义和区别详解
一.atomic与nonatomic 1.相同点 都是为对象添加get和set方法 2.不同点 atomic为get方法加了一把安全锁(及原子锁),使得方法get线程安全,执行效率慢 nonatomi ...
- OS中atomic的实现解析
OS中atomic的实现解析 转自:http://my.oschina.net/majiage/blog/267409 摘要 atomic属性线程安全,会增加一定开销,但有些时候必须自定义ato ...
- Objective-c的@property(atomic,nonatomic,readonly,readwrite,assign,retain,copy,getter,setter) 属性特性
assign:指定setter方法用简单的赋值,这是默认操作.你可以对标量类型(如int)使用这个属性.你可以想象一个float,它不是一个对象,所以它不能retain.copy. retain:指定 ...
- 为什么volatile不能保证原子性而Atomic可以?
在上篇<非阻塞同步算法与CAS(Compare and Swap)无锁算法>中讲到在Java中long赋值不是原子操作,因为先写32位,再写后32位,分两步操作,而AtomicLong赋值 ...
- Objective-C 关键字:retain, assgin, copy, readonly,atomic,nonatomic
声明式属性的使用:声明式属性叫编译期语法 @property(retain,nonatomic)Some *s; @property(参数一,参数二)Some *s; 参数1:retain:修饰引用( ...
- Java中的Atomic包
Atomic包的作用 方便程序员在多线程环境下,无锁的进行原子操作 Atomic包核心 Atomic包里的类基本都是使用Unsafe实现的包装类,核心操作是CAS原子操作: 关于CAS compare ...
- 各种同步方法性能比较(synchronized,ReentrantLock,Atomic)
synchronized: 在资源竞争不是很激烈的情况下,偶尔会有同步的情形下,synchronized是很合适的.原因在于,编译程序通常会尽可能的进行优化synchronize,另外可读性非常好,不 ...
随机推荐
- C#窗体磁吸屏幕的两种实现方案 - 开源研究系列文章
以前在大学的时候模仿Winamp的磁吸效果编写过一个类库,用于在应用中多个窗体的相互磁吸效果.因为此效果应用不多,但是窗体磁吸屏幕边缘的效果倒是比较实用,于是就用C#来实现窗体磁吸屏幕边缘的代码,这里 ...
- C#实现自己的MCP Client
市面上,有很多免费Client客户端. 虽然说,这些Client客户端可以满足我们大部分的需求,但是在实际企业业务场景中,免费的Client无法全部满足我们的需求. 下面我们用C# 实现MCP Cli ...
- .Net 组件库先混淆签名,再打包成.nupkg包
目前,我们项目组打算做增量升级的功能,这涉及到dll库增量改变,只有修改过代码的dll才需要有文件的变化,否则文件和对应的版本是不会改变的. 我们之前的打包的项目有一个小缺陷: 在整个应用打包输出的时 ...
- HTTP接口的中文乱码问题【python版】
一.问题:在软件接口开发过程中,request返回的信息在print的时候出现了乱码.默认编码:ISO-8859-1问题原因:可以在request语句后面插入print(result.enco ...
- HashMap如何计算初始化容量,最大容量是多少
摘要:结合HashMap源码,介绍HashMap如何确定初始化容量,其最大容量是多少. 更多关于HashMap的知识点,请戳<HashMap知识点梳理.常见面试题和源码分析>. 本 ...
- Java虚拟机之垃圾回收器
上面有7类垃圾回收器,分为两块,上面为新生代(Young generation)回收器,下面是老年代(Tenured generation)回收器.如果两个回收器之间存在连线,就说明它们可以搭配使 ...
- 爬取西刺代理的IP与端口(一)
0x01 简陋代码是,获取(.*?)的字符串 #coding:utf-8 from requests import * import re headers = { "accept" ...
- pytorch入门 - 微调huggingface大模型
在自然语言处理(NLP)领域,预训练语言模型如BERT已经成为主流.HuggingFace提供的Transformers库让我们能够方便地使用这些强大的模型. 本文将详细介绍如何使用PyTorch微调 ...
- c++ 函数 类
一.函数定义 在 C++ 中,函数是组织代码逻辑的基本单元,用于实现模块化.复用.结构清晰的程序设计. 1.函数的基本结构 返回类型 函数名(参数列表) { // 函数体 return 值; // 可 ...
- bge-large-zh-v1.5 和 bge-reranker-large模型有什么区别和联系
BGE(BAAI General Embedding)系列模型是智源研究院开发的高性能语义表征工具,其中bge-large-zh-v1.5和bge-reranker-large是两类不同功能的模型.它 ...