BloomFilter详解
BloomFilter 原理:
我们将从哈希函数开始讲起,然后分析 BloomFilter 背后的原理,之后我们利用初代BloomFilter 实现黑名单管理程序,最后我们考虑改进它。
问题引入:黑名单管理程序
在现实生活中,一个个人主页或者一个网页都会面临被他人恶意访问的威胁。为了有效防范这种威胁,我们需要识别恶意用户,并对这些用户实现黑名单管理。
假设我们已经拥有了这样的一份黑名单blacklist.txt。大胆假设这个黑名单的人数多达几百万个。对于每一个外来用户的访问,我们都需要知道这个人是不是黑名单用户,相应的操作就是查询一次黑名单。
如果只是简单的零散查询,对黑名单的查询不构成任何问题。但是如果是几万个用户同时访问呢?我们需要几万次查询,如果我们查询的太慢的话,对那些正常的用户来说将会造成极其糟糕的体验!假设我们只是将黑名单用户存入一个列表,那么每一次查询我们都要进行几百万次比较,这简直糟透了!有没有一种方法,让我们一次查询只需要进行几次零星的比较呢?
这就是布隆过滤器 BloomFilter 产生的原因。
哈希、哈希函数
哈希,又称作散列,通常用于类似的对数据进行压缩的情形,也是我们 BloomFilter 的重要环节。
假设我们现在的黑名单上有一个名字 "sam" ,我们有两种策略存储这个名字:1.直接将该名字的字符串存入;2. 设计一个函数,这个函数可以将不同的人名变成不同的数字,例如将 "sam" 映射为 488625。
如果采用第二种方法,我们便可以唯一通过数字来区分人名,我们便可以用一个表来存储相应的值。可以将不同的人名变成不同的数字的随机映射函数叫做哈希函数,其得到的值叫做一个名字的哈希值,这个值通常是不可逆的,也就是说仅靠 488625 是无法推出一个人的人名是 "sam" 。
哈希函数并不一定能够完全做到一一对应。事实上,存在一些特殊的情况:假设我们的黑名单上还有一个名字 "frank",这个名字的哈希值也为 488625 。如果出现这样的情况,我们就说哈希函数中出现了冲突。冲突是普遍存在的,因为往往哈希值要比人名的数量要少。解决冲突的方法也有很多种,在这里不详细展开叙述。
Python 内置函数中提供了一个非常好的求解字符串的哈希值的方法:hash()。既然有现成的方法,我们就不进一步去设计了。
现在我们假设对于每一个人名,我们都有了一个唯一确定的哈希值。接下来我们再回过头来看黑名单管理问题。如果仅仅是将列表中的人名替换成哈希值,我们每一次查询仍然需要几百万次的比较,仅仅是将人名转化为哈希值是不够的。我们需要设计新的哈希函数压缩我们的哈希值,至此 BloomFilter 应运而生。
BloomFilter :
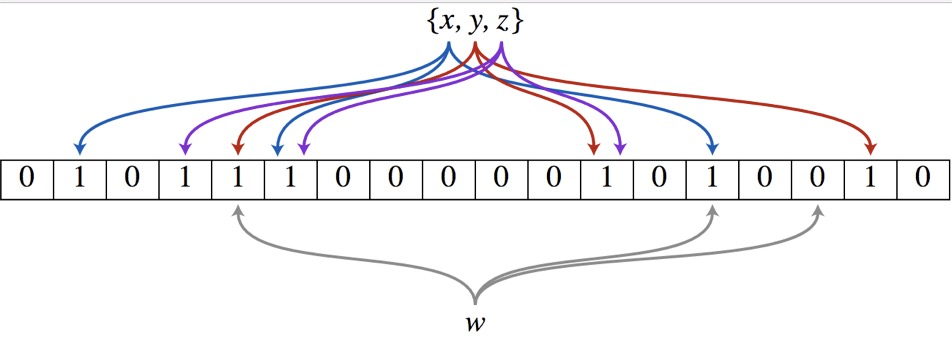
(图像借用其它博客:https://www.cnblogs.com/cpselvis/p/6265825.html)
上图就是我们的 BloomFilter 的一个抽象表示。首先我们需要创建一个位数组,大小视问题而定。刚开始,位数组的元素应该全部为0:
点击查看位数组
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
我们想要把所有的信息都压缩到位数组内部。也就是说,只要对这个位数组进行查询和搜索,就可以得到某个用户是否在黑名单内的信息,这样的查询肯定要比一次查询几百万个元素的速度快的多。问题是我们的哈希值的个数和黑名单用户的个数数量仍然是相等的,接下来应该怎么办?
我们此时需要再次额外定义若干个哈希函数。以上图为例,根据上图的信息,我们定义了三个哈希函数 hash1(x),hash2(x),hash3(x)。它们对得到的哈希值x,y,z做出了进一步的映射,:
| x | y | z | |
|---|---|---|---|
| hash1(x) | 2 | 5 | 4 |
| hash2(x) | 6 | 12 | 6 |
| hash3(x) | 14 | 17 | 12 |
此时,我们只需要将数组对应位置的标号修改为 1 即可。这样我们就成功压缩了数据(哈希值)。让我们遍历 x,y,z ,逐一进行修改:
向位数组中添加 x :
尝试后再查看结果
[0,1,0,0,0,1,0,0,0,0,0,0,0,1,0,0,0,0]
向位数组中添加 y :
尝试后再查看结果
[0,1,0,0,1,1,0,0,0,0,0,1,0,1,0,0,1,0]
向位数组中添加 z :
尝试后再查看结果
[0,1,0,1,1,1,0,0,0,0,0,1,0,1,0,0,1,0]
添加完毕。可以拿最终的结果和上图作比较,可以发现位数组是完全一致的。当然,哈希函数是随机的,也就是说最终的答案实际上是不唯一的,这里只是为了便于理解而举出的一个例子。
现在我们试图在上面的位数组中查找 "cta" 这个人名。假设这个名字的哈希值为上图的 w,通过 hash1(x),hash2(x),hash3(x) 得到的映射分别为 5,14,16。因为位数组中的位置 16 为 0,而经过映射的人名在位数组中的查找应该全部为 1,所以很容易得出 "cta" 不在黑名单中。
3.4 BloomFilter 的缺陷、改进:
虽然我们所设计的 BloomFilter 确实在查找方面迅速了不少,但是 BloomFilter 实际上仍然存在不少问题。接下来我们将对这些问题进行分析,并观察那些问题是重要的,紧迫的,哪些问题是次要的,可以不予考虑的。我们讨论问题的环境仍然是黑名单管理程序。
其一:BloomFilter 的插入相对于列表的插入要慢。这看起来是一个需要解决的问题,但是在现实情况下,一个网页将恶意用户拉黑是比较少见的情况,也就是说插入操作并不会非常频繁。所以 BloomFilter 的插入相对较慢是可接受的。
其二:BloomFilter 的查找存在漏洞。以之前的位数组为例:
[0,1,0,1,1,1,0,0,0,0,0,1,0,1,0,0,1,0]
我们试图在上面的位数组中查找 "cat" 这个人名。假设这个名字的哈希值通过 hash1(x),hash2(x),hash3(x) 得到的映射分别为 5,14,16。注意:我们只修改过三次位数组,没有一次修改是同时在 5,14,16 位置添加 1 的,也就是说 "cat" 根本不在黑名单内。但是,如果只看位数组,我们发现位置 5,14,16 处全部为 1 ,这又说明 "cat" 在黑名单内了。
这是完全错误的一种情况。想象你有一天看着别人的朋友圈,突然被别人莫名其妙拉黑了,你去问这个人发生什么事了,这个人却一无所知。这种程序的漏洞无疑是严重的,我们需要尽可能避免。
避免 BloomFilter 的查找漏洞可以采取以下两种措施:1. 选取适当个数且尽可能均匀的哈希函数;2. 位数组不能太小。
其三:BloomFilter 的删除存在漏洞。仍然以上述位数组为例,我们想要删除 z 所对应的人名:
[0,1,0,1,1,1,0,0,0,0,0,1,0,1,0,0,1,0]
我们采取的方案是,直接将 z 的 \(hash1(x),hash2(x),hash3(x)\) 所对应的位置的 1 全部改为 0 。修改后的位数组如下:
[0,1,0,0,1,0,0,0,0,0,0,1,0,0,0,0,1,0]
接下来我们查找 x 。由于位数组位置 6 处为 0 ,所以对于 x 所对应的字符串查找失败!这又是不可接受的。想象你有两个关系不好的人,有一个和你道歉了,你原谅了他并给他解除黑名单,结果另一个和你仍然关系不好的人莫名其妙也被你解除了黑名单,然后在你的朋友圈骚扰你,这无疑也是非常糟糕的!
幸运的是,只要对位数组稍作改进就可以完全避免这个问题。在添加操作中,我们原先是将 0 修改为 1,现在我们改为在对应位置加 1 即可;同样地,在删除操作中,对应位置减去 1 即可。读者可以自行验证这个方案是否正确,本代码的实现方案也采取的是这一策略。
讲到这里我们就可以实现代码了。
代码实现
黑名单blacklist.py:
blacklist.py中实现了一个类blackList,内置多个函数。和之后的set不同的是,这个blackList只是为了方便 BloomFilter 的创建而使用的:
def __init__(self):
self.names={}
self.num=0
在初始化函数中:
names代表黑名单的名字的集合。num代表名字的个数。
def hashcode(self,name):
return hash(name)
def hashcode(self,name):该函数用于生成黑名单名字的哈希值。
def add_blackname(self,name):
code=self.hashcode(name)
self.names[name]=code
def add_blackname(self,name):将一个名字添加入黑名单。
def add_blacknames(self,names):
for name in names:
self.add_blackname(name)
def add_blacknames(self,names):将若干个名字添加入黑名单。
def delete_blackname(self,name):
for blackname in list(self.names.keys()):
if blackname==name: del self.names[blackname]
def delete_blackname(self,name):将一个名字从黑名单中删除。
def delete_blacknames(self):
self.names.clear()
def delete_blacknames(self):将所有名字从黑名单中删除。
def get_hashcodes(self):
return np.array(list(self.names.values()))
def get_hashcodes(self):获取所有的哈希值。
def get_blacknames(self):
return np.array(list(self.names.items()))
def get_blacknames(self):获取所有的黑名单上的信息。
普通的实现方法set.py:
set.py中实现了一个类Set,内置多个函数:
def __init__(self):
self.names=[]
names代表黑名单的名字的集合。
def add(self,name):
self.names.append(name)
def addAll(self,names):
for name in names:
self.names.append(name)
def add(self,name):将一个名字添加入黑名单。def addAll(self,names):将若干个名字加入黑名单。
def find(self,fname):
for name in self.names:
if fname==name:
print(name," found in blacklist.\n")
return True
print(name," not found in blacklist.\n")
return False
def find(self,fname):查找一个名字是否在黑名单中。如果一个名字位于黑名单中,返回True,否则返回False。
def delete(self,dname):
for name in self.names:
if dname==name:
self.names.remove(name)
print("delete ",name,"successfully.\n")
return True
return False
def delete(self,dname):删除黑名单中的一个元素。
哈希函数hash.py:
hash.py中实现了一个类Hash,内置两个函数:
def __init__(self,num,length,maxNum):
self.num=num
self.max=maxNum
self.length=length
self.random1=np.random.randint(0,self.max,self.num)
self.random2=np.random.randint(0,self.max,self.num)
def __init__(self,num,length,maxNum): 用于初始化。其中输入的参数从左到右分别为:哈希函数的个数、位数组的长度、哈希函数的一个参数。self.random1和self.random2:用于产生哈希函数的两个随机列表,要产生多少个哈希函数,列表中就有多少个元素。
def hash_function(self,k,hashcode):
return((self.random1[k]*hashcode+self.random2[k])
%self.max)
%self.length
def hash_function(self,k,hashcode):哈希函数。
4.4 BloomFilter 实现方法bloomfilter.py:
bloomfilter.py中实现了一个类bloomFilter,内置若干函数:
def __init__(self,length,k):
self.length=length
self.k=k
self.hash=Hash(num=k,length=self.length,
maxNum=2000000)
self.binary=np.zeros(self.length)
length:位数组的长度。k:哈希函数的个数。hash:哈希函数。binary:位数组。
def add(self,hashcode):
for i in range(self.k):
j=self.hash.hash_function(i,hashcode)
self.binary[j]=self.binary[j]+1
def add(self,hashcode):向 BloomFilter 中添加一个黑名单用户。
def addAll(self,hashcode):
for h in hashcode: self.add(h)
def addAll(self,hashcode):向 BloomFilter 中添加多个黑名单用户。
def find(self,name,hashcode):
for i in range(self.k):
j=self.hash.hash_function(i,hashcode)
if self.binary[j]<=0:
print(name," not found in blacklist.\n")
return False
print(name," found in blacklist.\n")
return True
def find(self,name,hashcode): 查找一个名字是否在黑名单中。如果一个名字位于黑名单中,返回True,否则返回False。
def delete(self,name,hashcode):
if self.find(name,hashcode):
for i in range(self.k):
j=self.hash.hash_function(i,hashcode)
self.binary[j]=self.binary[j]-1
print("delete ",name,"successfully.\n")
def clear(self):
self.binary=np.zeros(self.length)
def print(self):
print(self.binary)
def delete(self,name,hashcode):删除某个黑名单用户。def clear(self):清空黑名单。def print(self):打印位数组。
BloomFilter详解的更多相关文章
- 【甘道夫】HBase基本数据操作详解【完整版,绝对精品】
引言 之前详细写了一篇HBase过滤器的文章,今天把基础的表和数据相关操作补上. 本文档参考最新(截止2014年7月16日)的官方Ref Guide.Developer API编写. 所有代码均基于“ ...
- HBase基本数据操作详解【完整版,绝对精品】
欢迎转载,请注明来源: http://blog.csdn.net/u010967382/article/details/37878701 概述 对于建表,和RDBMS类似,HBase也有namespa ...
- Scrapy框架——介绍、安装、命令行创建,启动、项目目录结构介绍、Spiders文件夹详解(包括去重规则)、Selectors解析页面、Items、pipelines(自定义pipeline)、下载中间件(Downloader Middleware)、爬虫中间件、信号
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- RocketMQ详解(四)核心设计原理
专题目录 RocketMQ详解(一)原理概览 RocketMQ详解(二)安装使用详解 RocketMQ详解(三)启动运行原理 RocketMQ详解(四)核心设计原理 RocketMQ详解(五)总结提高 ...
- 【转载】HBase基本数据操作详解【完整版,绝对精品】
转载自: http://blog.csdn.net/u010967382/article/details/37878701 概述 对于建表,和RDBMS类似,HBase也有namespace的概念,可 ...
- Linq之旅:Linq入门详解(Linq to Objects)
示例代码下载:Linq之旅:Linq入门详解(Linq to Objects) 本博文详细介绍 .NET 3.5 中引入的重要功能:Language Integrated Query(LINQ,语言集 ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- EntityFramework Core 1.1 Add、Attach、Update、Remove方法如何高效使用详解
前言 我比较喜欢安静,大概和我喜欢研究和琢磨技术原因相关吧,刚好到了元旦节,这几天可以好好学习下EF Core,同时在项目当中用到EF Core,借此机会给予比较深入的理解,这里我们只讲解和EF 6. ...
- Java 字符串格式化详解
Java 字符串格式化详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 文中如有纰漏,欢迎大家留言指出. 在 Java 的 String 类中,可以使用 format() 方法 ...
- Android Notification 详解(一)——基本操作
Android Notification 详解(一)--基本操作 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Notification 文中如有纰 ...
随机推荐
- .NET Core 异常(Exception)底层原理浅谈
中断与异常模型图 内中断 内中断是由 CPU 内部事件引起的中断,通常是在程序执行过程中由于 CPU 自身检测到某些异常情况而产生的.例如,当执行除法运算时除数为零,或者访问了不存在的内存地址,CPU ...
- 面试官:DNS解析都整不明白,敢说你懂网络?我:嘤嘤嘤!
一.写在开头 在OSI七层协议模型中应用层是距离我们最近,且日后开发使用到最多的一层,在上一篇博文中我们已经学习了应用层中的HTTP协议,在本文中我们再一起来学一下DNS.啥?DNS不是很了解?那还不 ...
- 钉钉机器人发送信息shell
#钉钉机器人发送信息shell 可作为shell函数模块调用,用于监控警报.jenkins发版通知等 微信API官方文档 https://ding-doc.dingtalk.com/doc#/serv ...
- Qt编写物联网管理平台45-采集数据转发
一.前言 本系统严格意义上说是一个直连硬件的客户端软件,下面接的modbus协议的设备直接通过网络或者串口和软件通信,软件负责解析数据和存储记录.有时候客户想要领导办公室或者分管这一块的部门经理办公室 ...
- Qt音视频开发14-mpv读取和控制
一.前言 用mpv来读取文件的信息,以及设置当前播放进度,音量.静音等,和当时vlc封装的功能一样,只不过vlc是通过调用函数接口去处理,而mpv是通过读取和设置属性来处理,vlc支持定时器或者线程中 ...
- 命名空间“System.Web.UI.Design”中不存在类型或命名空间名称“ControlDesigner”
命名空间"System.Web.UI.Design"中不存在类型或命名空间名称"ControlDesigner" 命名空间"System.Web.UI ...
- Note - 速通 NPC?有限域算术!
浅谈有限域在 OI 中的一些应用 (2023 国家集训队论文), 戚朗瑞. \(\textbf{Example 1.}\) 给定一张有向图 \(G=(V,E)\), \(|V|=n\), \( ...
- MS Speech/ azure
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- w3cschool-XML教程
参考https://www.w3cschool.cn/xml/ XML 教程 让我们先来简单的了解一下 XML: XML 指可扩展标记语言(eXtensible Markup Language). X ...
- 原生JS实现一个日期选择器(DatePicker)组件
这是通过原生HTML/CSS/JavaScript完成一个日期选择器(datepicker)组件,一个纯手搓的组件的开发.主要包括datepicker静态结构的编写.日历数据的计划获取.组件的渲染以及 ...