ELK之方便的日志收集、搜索、展示工具
大家在做分部署系统开发的时候是不是经常因为查找日志而头疼,因为各服务器各应用都有自己日志,但比较分散,查找起来也比较麻烦,今天就给大家推荐一整套方便的工具ELK,ELK是Elastic公司开发的一整套完整的日志分析技术栈,它们是Elasticsearch,Logstash,和Kibana,简称ELK。Logstash做日志收集分析,Elasticsearch是搜索引擎,而Kibana是Web展示界面。
1、日志收集分析Logstash
LogstashLogstash 是一个接收,处理,转发日志的工具,支持系统日志,webserver 日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
Logstash的理念很简单,它只做3件事情:
- Collect:数据输入
- Enrich:数据加工,如过滤,改写等
- Transport:数据输出
别看它只做3件事,但通过组合输入和输出,可以变幻出多种架构实现多种需求。这里只抛出用以解决日志汇总需求的部署架构图:
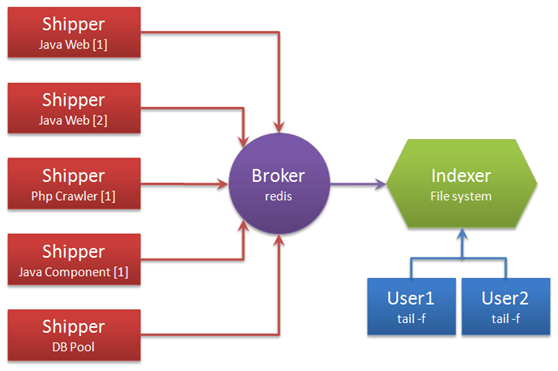
解释术语:
- Shipper:日志收集者。负责监控本地日志文件的变化,及时把日志文件的最新内容收集起来,输出到Redis暂存。
- Indexer:日志存储者。负责从Redis接收日志,写入到本地文件。
- Broker:日志Hub,用来连接多个Shipper和多个Indexer。
无论是Shipper还是Indexer,Logstash始终只做前面提到的3件事:
- Shipper从日志文件读取最新的行文本,经过处理(这里我们会改写部分元数据),输出到Redis,
- Indexer从Redis读取文本,经过处理(这里我们会format文本),输出到文件。
一个Logstash进程可以有多个输入源,所以一个Logstash进程可以同时读取一台服务器上的多个日志文件。Redis是Logstash官方推荐的Broker角色“人选”,支持订阅发布和队列两种数据传输模式,推荐使用。输入输出支持过滤,改写。Logstash支持多种输出源,可以配置多个输出实现数据的多份复制,也可以输出到Email,File,Tcp,或者作为其它程序的输入,又或者安装插件实现和其他系统的对接,比如搜索引擎Elasticsearch。
总结:Logstash概念简单,通过组合可以满足多种需求。
2、日志搜索Elasticsearch
Elasticsearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。
它可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。
Elasticsearch是一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎,可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架。
但是Lucene只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene。需要很多的学习了解,才能明白它是如何运行的,Lucene确实非常复杂。
Elasticsearch使用Lucene作为内部引擎,但是在使用它做全文搜索时,只需要使用统一开发好的API即可,而不需要了解其背后复杂的Lucene的运行原理。
当然Elasticsearch并不仅仅是Lucene这么简单,它不但包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
这么多的功能被集成到一台服务器上,你可以轻松地通过客户端或者任何你喜欢的程序语言与ES的RESTful API进行交流。
Elasticsearch的上手是非常简单的。它附带了很多非常合理的默认值,这让初学者很好地避免一上手就要面对复杂的理论,
它安装好了就可以使用了,用很小的学习成本就可以变得很有生产力。
随着越学越深入,还可以利用Elasticsearch更多高级的功能,整个引擎可以很灵活地进行配置。可以根据自身需求来定制属于自己的Elasticsearch。
使用案例:
维基百科使用Elasticsearch来进行全文搜做并高亮显示关键词,以及提供search-as-you-type、did-you-mean等搜索建议功能。
英国卫报使用Elasticsearch来处理访客日志,以便能将公众对不同文章的反应实时地反馈给各位编辑。
StackOverflow将全文搜索与地理位置和相关信息进行结合,以提供more-like-this相关问题的展现。
GitHub使用Elasticsearch来检索超过1300亿行代码。
每天,Goldman Sachs使用它来处理5TB数据的索引,还有很多投行使用它来分析股票市场的变动。
但是Elasticsearch并不只是面向大型企业的,它还帮助了很多类似DataDog以及Klout的创业公司进行了功能的扩展。
在这里简单介绍下与solr的比较,因为solr作为现在最为流程的搜索引擎,为什么不选用
- Elasticsearch由于其易用性而在较新的开发人员中更受欢迎
- 但是如果你已经在使用solr了,请继续使用它,因为迁移到Elasticsearch并不会带来具体的优势
- 如果您需要它来处理分析查询以及搜索文本,Elasticsearch是更好的选择,特别是收集日志,做分析处理
- solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
- solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式
- solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
- solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
3、日志展示Kibana
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。
Kibana让我们理解大量数据变得很容易。它简单、基于浏览器的接口使你能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘。安装Kibana非常快,你可以在几分钟之内安装和开始探索你的Elasticsearch索引数据,不需要写任何代码,没有其他基础软件依赖。
总结
整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。各具体搭建配置就不在这里具体说明,可自行百度,其实都挺简单的。
ELK之方便的日志收集、搜索、展示工具的更多相关文章
- ELK一个优秀的日志收集、搜索、分析的解决方案
1 什么是ELK? ELK,是Elastaicsearch.Logstash和Kibana三款软件的简称.Elastaicsearch是一个开源的全文搜索引擎.Logstash则是一个开源的数据收集引 ...
- 用ELK搭建简单的日志收集分析系统【转】
缘起 在微服务开发过程中,一般都会利用多台服务器做分布式部署,如何能够把分散在各个服务器中的日志归集起来做分析处理,是一个微服务服务需要考虑的一个因素. 搭建一个日志系统 搭建一个日志系统需要考虑一下 ...
- ELK 构建 MySQL 慢日志收集平台详解
ELK 介绍 ELK 最早是 Elasticsearch(以下简称ES).Logstash.Kibana 三款开源软件的简称,三款软件后来被同一公司收购,并加入了Xpark.Beats等组件,改名为E ...
- ELK构建MySQL慢日志收集平台详解
上篇文章<中小团队快速构建SQL自动审核系统>我们完成了SQL的自动审核与执行,不仅提高了效率还受到了同事的肯定,心里美滋滋.但关于慢查询的收集及处理也耗费了我们太多的时间和精力,如何在这 ...
- Rainbond通过插件整合ELK/EFK,实现日志收集
前言 ELK 是三个开源项目的首字母缩写:Elasticsearch.Logstash 和 Kibana.但后来出现的 FileBeat 可以完全替代 Logstash的数据收集功能,也比较轻量级.本 ...
- ELK(Elasticsearch + Logstash + Kibana) 日志收集
单体应用或微服务的场景下,每个服务部署在不同的服务器上,需要对日志进行集重收集,然后统一查看所以日志. ELK日志收集流程: 1.微服务器上部署Logstash,对日志文件进行数据采集,将采集到的数据 ...
- ELK Stack 介绍 & Logstash 日志收集
ELK Stack 组成 Software Description Function E:Elasticsearch Java 程序 存储,查询日志 L:Logstash Java 程序 收集.过滤日 ...
- 【Spring Cloud & Alibaba全栈开源项目实战】:SpringBoot整合ELK实现分布式登录日志收集和统计
一. 前言 其实早前就想计划出这篇文章,但是最近主要精力在完善微服务.系统权限设计.微信小程序和管理前端的功能,不过好在有群里小伙伴的一起帮忙反馈问题,基础版的功能已经差不多,也在此谢过,希望今后大家 ...
- Docker搭建ELK的javaweb应用日志收集存储分析系统
1.启动elasticsearch docker run -d --name myes -p 9200:9200 elasticsearch:2.3 2.启动kibana docker run --n ...
随机推荐
- ListView嵌套两个EditText相关显示问题
这里说明:本人第一次写博客,可能写的不算太好.可是这个相关类型的研究与拓展,是项目中比較难得的.所以开一篇博客来总结和思考.先让我们看看项目需求. 项目需求说明: 1.须要在点击EditText的时候 ...
- HDOJ--2112--
HDU Today Time Limit: 15000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- bigAutocomplete实现联想
直接举例说明: //xx联想 var list = $(".js-xxxx").text();//需要联想出的内容的list,该list由后台传入,保存在jsp页面,js取隐藏域值 ...
- GEM演唱会
周六去魔都看邓紫棋演唱会,各位看官可能要问.杭州不是也有嚒.为嘛去魔都-..由于po主是逗比哈哈(- ̄▽ ̄-) 早上睡到自然醒,然后開始做午饭.吃完躺沙发上看电视,看到一点多认为应该要出发了(演唱会7 ...
- Exception from HRESULT: 0x80070057 (E_INVALIDARG)
Exception from HRESULT: 0x80070057 (E_INVALIDARG)异常. 解决方案:清除ASP.NET缓存目录中对应的应用程序目录. ASP.NET缓存目录如下: C: ...
- EMC机理------串扰
转:电子工程师不得不知道的EMC机理------串扰(韬略科技EMC) 串扰是信号完整性中最基本的现象之一,在板上走线密度很高时串扰的影响尤其严重.我们知道,线性无缘系统满足叠加定理,如果受害线上有信 ...
- EMMC电路设计
优秀文档: eMMC基础技术1:MMC简介 eMMC基础技术2:eMMC概述 一:供电电源时序 EMMC的供电有两种模式,且分两路工作,有VCC和VccQ.在规范上,上电时序是有要求的,如下图所示. ...
- Key-Value键值存储原理初识(NOSQL)
NO-Sql数据库:Not Only不仅仅是SQL 定义:非关系型数据库:NoSQL用于超大规模数据的存储.(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据).这些类型的数据存储不需要固 ...
- Delphi列表控件TListView定位到某一行。
ListView1.Item[100].Focused = true; //定位到索引为100的行ListView1.Item[100].Selected = true; ListView1.Item ...
- 转:MSN君最后的十个瞬间
五年前我用过MSN五年.在一家ERP公司当程序猿的时候我甚至在业余时间做过一款MSN订餐机器人. 转完这篇文章.就是真正跟MSN的bye bye了. 转自:www.gogo.cn 今天是一个普通的周五 ...