python requests抓取猫眼电影
1. 网址:http://maoyan.com/board/4?

2. 代码:
import json
from multiprocessing import Pool
import requests
from requests.exceptions import RequestException
import re def get_one_page_html(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?alt.*?src="(.*?)".*?name"><a'
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)# .可以匹配任意的换行符 items = re.findall(pattern,html)
#('1', 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', '霸王别姬', '\n 主演:张国荣,张丰毅,巩俐\n ', '上映时间:1993-01-01(中国香港)', '9.', '6'),
for item in items:
yield {
'index' : item[0],
'image' : item[1],
'title':item[2],
'actor' : item[3].strip()[3:],
'time': item[4].strip()[5:],
'score' : item[5] + item[6]
} def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8')as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')#导入快捷见alt+enter,content内容是个字典,我们要把它变成字符串写入文件,加入换行符,每行一个
f.close() def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page_html(url)
for item in parse_one_page(html):
print(item)
write_to_file(item) #会变成unicode编码,若想result.txt里面是中文,需要修改write_to_file函数,加上encoding=‘utf-8’和ensure_ascii=False if __name__ == '__main__':
# for i in range(10):
# main(i*10) pool = Pool()
pool.map(main, [i*10 for i in range(10)])
3. 结果:
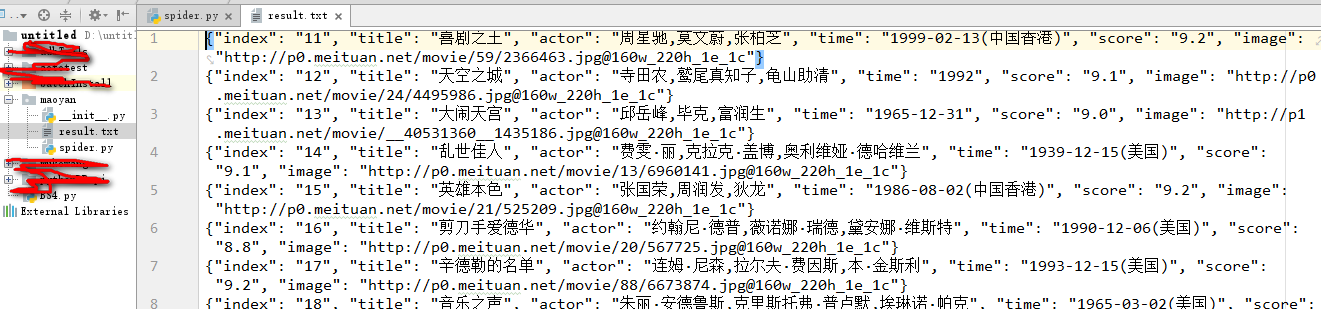
注意:
1.正则匹配要好好看看
2.将输出的内容格式化,变成一个生成器字典
3.写到文件的时候把unicode编码变成中文显示
4.进程池Pool。实现秒抓
python requests抓取猫眼电影的更多相关文章
- Python Spider 抓取猫眼电影TOP100
""" 抓取猫眼电影TOP100 """ import re import time import requests from bs4 im ...
- Python爬虫之requests+正则表达式抓取猫眼电影top100以及瓜子二手网二手车信息(四)
requests+正则表达式抓取猫眼电影top100 一.首先我们先分析下网页结构 可以看到第一页的URL和第二页的URL的区别在于offset的值,第一页为0,第二页为10,以此类推. 二.< ...
- Python爬虫【三】利用requests和正则抓取猫眼电影网上排名前100的电影
#利用requests和正则抓取猫眼电影网上排名前100的电影 import requests from requests.exceptions import RequestException imp ...
- python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言)
python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言) 感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为 ...
- 使用requests爬取猫眼电影TOP100榜单
Requests是一个很方便的python网络编程库,用官方的话是"非转基因,可以安全食用".里面封装了很多的方法,避免了urllib/urllib2的繁琐. 这一节使用reque ...
- 使用Request+正则抓取猫眼电影(常见问题)
目前使用Request+正则表达式,爬取猫眼电影top100的例子很多,就不再具体阐述过程! 完整代码github:https://github.com/connordb/Top-100 总结一下,容 ...
- python应用-爬取猫眼电影top100
import requests import re import json import time from requests.exceptions import RequestException d ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 爬虫--requests爬取猫眼电影排行榜
'''目标:使用requests分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件URL地址:http://maoyan.com/board/4 其中参数offset表示其实条 ...
随机推荐
- 九度OJ 1055:数组逆置 (基础题)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:7324 解决:3429 题目描述: 输入一个字符串,长度小于等于200,然后将数组逆置输出. 输入: 测试数据有多组,每组输入一个字符串. ...
- 使用active mq
1 windows下使用active mq 1.1 下载active mq 1.2 点击根目录\bin\win64\activemq.bat运行 1.3 登陆查看 http://localhost:8 ...
- Yii 框架 URL路径简化
Yii 框架的訪问地址若不简化会让人认为非常繁琐.未简化的地址一般格式例如以下: http://localhost:80/test/index.php?r=xxx/xxx/xxx 若是带有參数会更复杂 ...
- BTC、BCH和BSV三者到底有什么区别?
比特币发展到今天已经有10个年头了,在这十年的发展中,比特币一共经历了两次重要的分裂,现在变成了三种货币,第一种是目前继承了比特币绝大多数遗产的BTC:第二种是BCH:第三种是BSV.那这三种货币到底 ...
- 9patch图片
9patch图片可直接缩放,放在drawable文件夹下就可以 右边和下边指定内容区域
- Delphi编写WebService体会
源:Delphi编写WebService体会 Dispatch: 派遣,分派 Invoke: 调用 Invokable: 可调用接口 TReomtable: WebService中自定义类都是继承自该 ...
- 基于node开发的web应用,负载均衡的简单实践
集群(cluster)是一组相互独立的.通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理.一个客户与集群相互作用时,集群像是一个独立的服务器. 负载均衡(Load Balance ...
- POJ3294 Life Forms —— 后缀数组 最长公共子串
题目链接:https://vjudge.net/problem/POJ-3294 Life Forms Time Limit: 5000MS Memory Limit: 65536K Total ...
- 自用的弹出窗口jquery插件
现有网上的弹出窗口插件很多, 但发现在项目应用中总会有些功能不能适用, 最后只好自己写一个:插件主要参考了ymPrompt弹窗代码, ymPrompt是JS的弹窗,本插件相当于是ymPrompt的jq ...
- ffmpeg给视频加文字水印
ffmpeg -i dd2800.mp4 -vf "drawtext=fontfile=Arial.ttf: text='Hu':x=100:y=10:fontsize=24:fontcol ...