Java中HashMap底层原理源码分析
在介绍HashMap的同时,我会把它和HashTable以及ConcurrentHashMap的区别也说一下,不过本文主要是介绍HashMap,其实它们的原理差不多,都是数组加链表的形式存储数据,另外本文所介绍的都是JDK1.8版本的。在介绍之前,先看下Map家族的继承体系图:
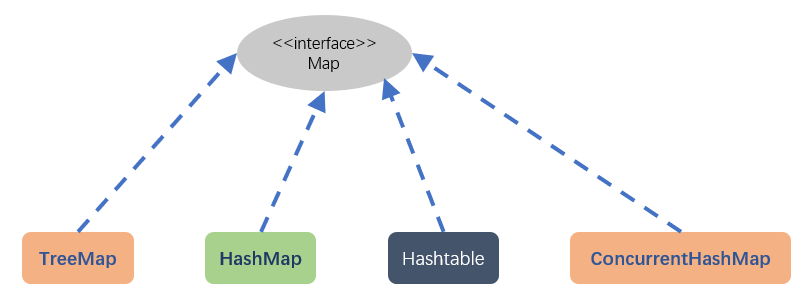
其中,TreeMap是基于树实现的,其他三个都是哈希表结构。
HashMap和Hashtable的主要区别是:
1. Hashtable是线程安全,而HashMap则非线程安全,Hashtable的实现方法里面大部分都添加了synchronized关键字来确保线程同步,因此相对而言HashMap性能会高一些,在多线程环境下若使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合。
2. HashMap的键和值都可以为null,而Hashtable的键值都不能为null。
3. HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。HashMap扩展容量是当前容量翻倍即:capacity*2,Hashtable扩展容量是容量翻倍+1即:capacity*2+1(关于扩容和填充因子后面会讲)
4. 两者的哈希算法不同,HashMap是先对key(键)求hashCode码,然后再把这个码值得高位和低位做异或运算,源码如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}i = (n - 1) & hash然后把hash(key)返回的哈希值与HashMap的初始容量(也叫初始数组的长度)减一做&(与运算)就可以计算出此键值对应该保存到数组的那个位置上(hash&(n-1))。这里为什么不用key本身的hashcode方法,而又是右移动16位又是异或操作。开发人员这样做的目的是什么呢?我的理解是当数组容量很小的时候,计算元素在数组中的位置(n-1)&hash,只用到了hash值的低位,这样当不同的hash值低位相同,高位不同的时候会产生冲突。实际上的hash值将hashcode低16位与高16位做异或运算,相当于混合了高位和低位,增加了随机性。当然是冲突越少越好,元素的分布越随机越好。
而Hashtable计算位置的方式如下:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;直接计算key的哈希码,然后与2的31次方做&(与运算),然后对数组长度取余数计算位置。
HashMap存取元素详解
HashMap的存储方式是哈希表,那么什么是哈希表,其实就是数组+链表。HashMap初始数组长度为16。数组的每个元素都保存着链表头的地址(或者为null),在向HashMap中put(key,value)的时候,先使用hash算法计算哈希值,然后再和数组的长度减一做与运算。计算出此键值对应该保存到数组的那个位置上,如果此位置没有元素,意思就是链表的头结点为null,那么就新建一个node结点,把key,value以及next保存。Node类源码如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
....
......
........
}这里我只贴出了部分,看的出来,这个保存键值对的node结点是一个实现了Map.Entry的内部类,里面的属性有hash值(就是通过hash算法计算出来的),key,value,以及next。当执行put(key,value)的时候,如果计算出来的数组位置上有元素的话(说明计算出的hash值和此数组位置对应的单链表上的所有元素的hash值相同,即发生冲突。),就沿着此数组位置对应的单链表上的结点一个个比较,如果遇到相同的key,就用新的value替换掉旧的value,如果找不到相同的key,就新建一个node结点,保存hash值,key和value,然后插入到此单链表的尾部。插入之后,这里程序会判断此单链表上的结点个数(这里注意,不是全部的元素结点个数,而是此单链表上的结点个数,和其他数组位置上的单链表无关)是否超过限制(HashMap默认是8),如果超过限制,那么HashMap就会把此单链表转成红黑树(关于什么是红黑树,请读者自行百度),这样做的目的是为了提高get(key)的速度。由时间复杂度原来的O(n)变成了O(logn)。到这还不算完,一旦插入新的node,程序就会检查HashMap的装载量(全部键值对的个数)是否超过阈值,这个阈值是计算出来的,就是装载因子乘上数组容量。一旦装载量大于此阈值,程序就会执行resize()方法进行扩展容量,HashMap是直接扩容2倍,扩容之后,将原来链表数组的每一个链表分成奇偶两个子链表分别挂在新链表数组的散列位置,这样就减少了每个链表的长度,增加查找效率,但是扩容是很费时的。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认初始数组容量 16
static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; //装载因子默认0.75
static final int TREEIFY_THRESHOLD = 8; //单链表结点个数超过8就转成红黑树
int threshold; //阈值,超过此数,就进行扩展容量下面看下HashMap存储元素的大致情况:
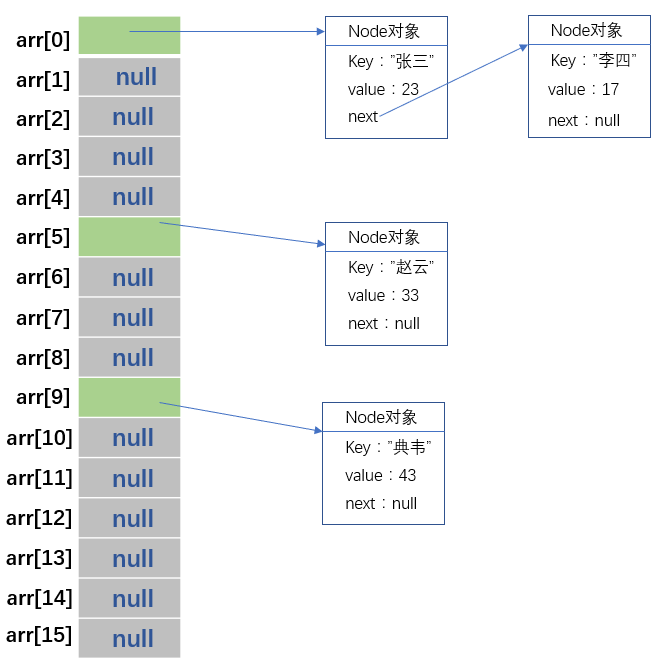
现在看下put操作的源码解析:

现在看下get操作的源码解析:
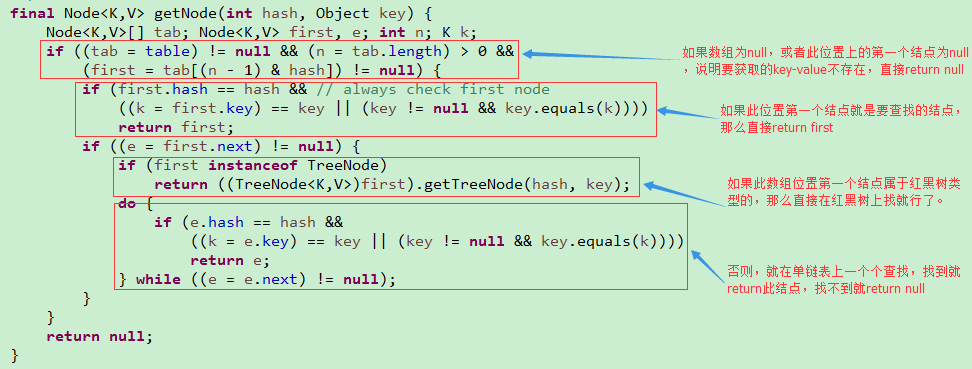
其实,HashMap的初始容量和装载因子都是可以通过HashMap的有参构造进行改的,如果使用无参的构造函数定义HashMap,那么这两个属性都是默认的。至此,HashMap的底层实现原理就介绍完了,下面简单说下Hashtable和ConcurrentHashMap。它们两个都是线程安全的,都不可以存储值为null的key,但是它们在线程同步上有些区别。Hashtable是在方法上使用synchronized关键字,其实这是对对象加锁,锁住的都是对象整体,当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。ConcurrentHashMap算是对上述问题的优化。ConcurrentHashMap引入了分割(Segment),可以理解为它把一个大的Map拆分成N个小的Hashtable,在put方法中,会根据哈希算法来先决定具体存放进哪个Segment,如果我们查看Segment的put操作源码,会发现内部使用的同步机制还是基于锁的,但是这样可以只对Map的一部分(Segment)进行上锁,影响的只是将要放入同一个Segment的元素的put操作,保证同步的时候,锁住的不是整个Map(而Hashtable是锁住全部的),相对于Hashtable的synchronized关键字锁的粒度更精细了一些,提高了多线程环境下的性能,所以Hashtable已被淘汰了。
Java中HashMap底层原理源码分析的更多相关文章
- Spring Boot自动装配原理源码分析
1.环境准备 使用IDEA Spring Initializr快速创建一个Spring Boot项目 添加一个Controller类 @RestController public class Hell ...
- java 1.8 动态代理源码分析
JDK8动态代理源码分析 动态代理的基本使用就不详细介绍了: 例子: class proxyed implements pro{ @Override public void text() { Syst ...
- java中的==、equals()源码分析
浅谈Java中的equals和== 在初学Java时,可能会经常碰到下面的代码: 1 String str1 = new String("hello"); 2 String str ...
- Java HashMap底层实现原理源码分析Jdk8
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依 ...
- Java中HashMap底层实现原理(JDK1.8)源码分析
这几天学习了HashMap的底层实现,但是发现好几个版本的,代码不一,而且看了Android包的HashMap和JDK中的HashMap的也不是一样,原来他们没有指定JDK版本,很多文章都是旧版本JD ...
- SpringMvc 启动原理源码分析
了解一个项目启动如何实现是了解一个框架底层实现的一个必不可少的环节.从使用步骤来看,我们一般是引入包之后,配置web.xml文件.官方文档示例的配置如下: <web-app> <se ...
- jQuery1.9.1--结构及$方法的工作原理源码分析
jQuery的$方法使用起来非常的多样式,接口实在太灵活了,有点违反设计模式的原则职责单一.但是用户却非常喜欢这种方式,因为不用记那么多名称,我只要记住一个$就可以实现许多功能,这个$简直就像个万能的 ...
- 原码、补码,反码以及JAVA中数值采用哪种码表示
原码.补码,反码以及JAVA中数值采用哪种码表示 1.原码定义(摘自百度百科):一种计算机中对数字的二进制定点表示方法,原码表示法在数值前面增加了一位符号位(即最高位为符号位):正数该位为0,负数该位 ...
- JAVA中hashmap的分析
从http://blog.csdn.net/luanlouis/article/details/41576373?utm_source=tuicool&utm_medium=referral学 ...
随机推荐
- 微信支付——基于laravel框架的php实现
现在经手的几乎每个项目都支持微信支付,简单记录下接入的大致流程. 1.首先商户等申请各种账号,微信支付商户号,APPID,API密钥,Appsecret 2.app端上传支付需要的各个字段 3.后台收 ...
- 牛客网Java刷题知识点之Iterator和ListIterator的区别
不多说,直接上干货! https://www.nowcoder.com/ta/review-java/review?query=&asc=true&order=&page=21 ...
- SQL注入中的整型注入实验
首先搭建一个用于注入的环境 目录结构 conn.php 用来连接数据库的文件PHP文件 index.php 用来执行SQL命令,以及返回查询结构 index.html 一个存 ...
- 学习用5W1H来管理自己的项目/工作
学习用5W1H来管理自己的项目/工作 最近开始需要系统化的思维模型,这只是一个开始,一下用脑图的形式来简介5W1H的具体内容: 先写xmind思维树的文本导出,后面附上图片.^ _ ^ 5W1H ...
- Java文件操作系列[3]——使用jacob操作word文档
Java对word文档的操作需要通过第三方组件实现,例如jacob.iText.POI和java2word等.jacob组件的功能最强大,可以操作word,Excel等格式的文件.该组件调用的的是操作 ...
- show processlist使用介绍
这个命令中最关键的就是state列,mysql列出的状态主要有以下几种: Checking table 正在检查数据表(这是自动的).Closing tables 正在将表中修改的数据刷新到磁盘中,同 ...
- 怎样配置JDK开发环境
(1)我们需要配置三个环境变量,分别是JAVA_HOME,CLASSPATH,Path (2)变量名输入:JAVA_HOME,变量值输入:D:\Java\jdk1.8.0_05点击确定. 需要特别注意 ...
- 5 Options for Distributing Your iOS App to a Limited Audience
http://mobiledan.net/2012/03/02/5-options-for-distributing-ios-apps-to-a-limited-audience-legally/ I ...
- 92.背包问题(lintcode)
注意j-A[i-1]必须大于等于0,只大于0会报错 class Solution { public: /** * @param m: An integer m denotes the size of ...
- Mybatis generator自动生成代码包括实体,dao,xml文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration ...