mysql用limit时offset越大时间越长
首先说明一下MySQL的版本:
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.17 |
+-----------+
1 row in set (0.00 sec)
表结构:
mysql> desc test;
+--------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+---------+----------------+
| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment |
| val | int(10) unsigned | NO | MUL | 0 | |
| source | int(10) unsigned | NO | | 0 | |
+--------+---------------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
id为自增主键,val为非唯一索引。
灌入大量数据,共500万:
mysql> select count(*) from test;
+----------+
| count(*) |
+----------+
| 5242882 |
+----------+
1 row in set (4.25 sec)
我们知道,当limit offset rows中的offset很大时,会出现效率问题:
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (15.98 sec)
为了达到相同的目的,我们一般会改写成如下语句:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.38 sec)
时间相差很明显。
为什么会出现上面的结果?我们看一下select * from test where val=4 limit 300000,5;的查询过程:
查询到索引叶子节点数据。
根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
类似于下面这张图: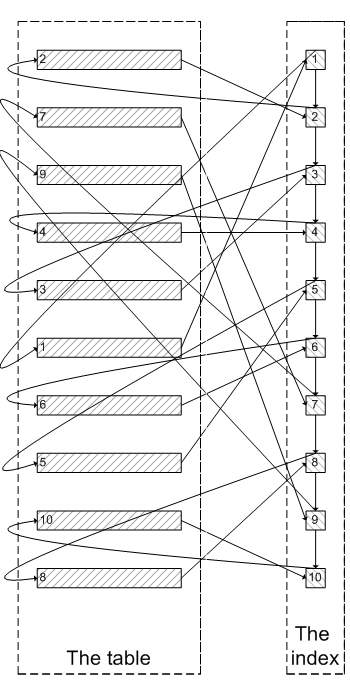
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程:
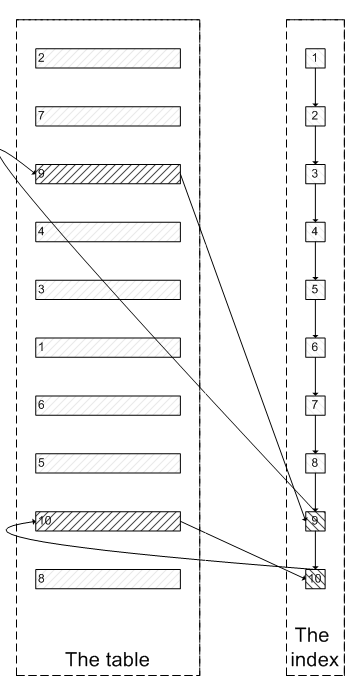
其实我也想问这个问题。
证实
下面我们实际操作一下来证实上述的推论:
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
我只能通过间接的方式来证实:
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.04 sec)
可以看出,目前buffer pool中没有关于test表的数据页。
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+
2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id
为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown
/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.03 sec)
运行sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 5 |
| val | 390 |
+------------+----------+
2 rows in set (0.03 sec)
我们可以看明显的看出两者的差别:第一个sql加载了4098个数据页到buffer pool,而第二个sql只加载了5个数据页到buffer pool。符合我们的预测。也证实了为什么第一个sql会慢:读取大量的无用数据行(300000),最后却抛弃掉。
而且这会造成一个问题:加载了很多热点不是很高的数据页到buffer pool,会造成buffer pool的污染,占用buffer pool的空间。
遇到的问题
为了在每次重启时确保清空buffer pool,我们需要关闭innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。
mysql用limit时offset越大时间越长的更多相关文章
- 越大优先级越高,优先级越高被OS选中的可能性就越大
进程的休眠:Thread sleep(1000);//括号中以毫秒为单位 当main()运行完毕,即使在结束时时间片还没有用完,CPU也放弃此时间片,继续运行其他程序. Try{Thread.slee ...
- 权力越大职责越大——C#中的职责链模式
大家好,欢迎来到老胡的博客,今天我们继续了解设计模式中的职责链模式,这是一个比较简单的模式.跟往常一样,我们还是从一个真实世界的例子入手,这样大家也对这个模式的应用场景有更深刻的理解. 一个真实的 ...
- android:layout_weight越大所占比例越大和越大所占比例越小的两个例子
摘要: 我的技术博客经常被流氓网站恶意爬取转载.请移步原文:http://www.cnblogs.com/hamhog/p/3907146.html,享受整齐的排版.有效的链接.正确的代码缩进.更好的 ...
- idea svn提交时,performing vcs refresh时间很长的解决办法
解决方法:version control -> local changes -> local changelist 列表中无用的文件或文件夹右键选择svn忽略 ps:原因是文件太多,导致对 ...
- C市现在要转移一批罪犯到D市,C市有n名罪犯,按照入狱时间有顺序,另外每个罪犯有一个罪行值,值越大罪越重。现在为了方便管理,市长决定转移入狱时间连续的c名犯人,同时要求转移犯人的罪行值之和不超过t,问有多少种选择的方式?
// ConsoleApplication12.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" // ConsoleApplication1 ...
- From 易水寒 格局越大 人生越宽
有这么一则故事:三个泥瓦匠在砌墙,一个人走过来,问他们在干什么. 第一个泥瓦匠没好气地说,你没看见吗?我在辛苦地砌墙呢.第二个回答,我们正在建一座高楼.第三个则洋溢着喜悦说,我们正在创造美好生活. 1 ...
- 7kyu (难度系数kyu阶段数值越大难度越低) 数组分组及求和
几个人排成一排,分成两队.第一个人进入一队,第二个人进入第二队,第三个人进入第一队,以此类推. 给定一个正整数的数组(人的权重),返回两个整数的新数组/元组,其中第一个是第1组的总重量,第二个是第2组 ...
- MYSQL分页 limit 太慢优化
limit分页原理 当我们翻到最后几页时,查询的sql通常是:select * from table where column=xxx order by xxx limit 1000000,20.查询 ...
- 你们一般都是怎么进行SQL调优的?MySQL在执行时是如何选择索引的?
前言 过年回来的第二周了,终于有时间继续总结知识了.这次来看一下SQL调优的知识,这类问题基本上面试的时候都会被问到,无论你的岗位是后端,运维,测试等等. 像本文标题中的两个问题,就是我在实际面试过程 ...
随机推荐
- 《PHP 设计模式》翻译完毕
翻译进度请见:https://laravel-china.org/docs/php-design-patterns/2018?mode=sections 设计模式不仅代表着更快开发健壮软件的有用方法, ...
- 使用Java编译思想
1.Java常见的注释有哪些,语法是怎样的? 1)单行注释用//表示,编译器看到//会忽略该行//后的所文本 2)多行注释/* */表示,编译器看到/*时会搜索接下来的*/,忽略掉/* */之间的文本 ...
- New UWP Community Toolkit - Staggered panel
概述 前面 New UWP Community Toolkit 文章中,我们对 2.2.0 版本的重要更新做了简单回顾,其中简单介绍了 Staggered panel,本篇我们结合代码详细讲解 St ...
- Java基础学习笔记二十二 网络编程
络通信协议 通过计算机网络可以使多台计算机实现连接,位于同一个网络中的计算机在进行连接和通信时需要遵守一定的规则,这就好比在道路中行驶的汽车一定要遵守交通规则一样.在计算机网络中,这些连接和通信的规则 ...
- C语言博客作业--函数
一.PTA实验作业 题目1 (6-7) (1).本题PTA提交列表 (2)设计思路 设计第一个函数判断是否完数int factorsum( int number ) 定义sum.i:sum初始化归0, ...
- 201621123031 《Java程序设计》第4周学习总结
Week04-面向对象设计与继承 1. 本周学习总结 1.1 写出你认为本周学习中比较重要的知识点关键词 关键词:继承.覆盖.多态.抽象 1.2 尝试使用思维导图将这些关键词组织起来. 1.3 可选: ...
- 洛谷 P3797 妖梦斩木棒
https://www.luogu.org/problem/show?pid=3797 题目背景 妖梦是住在白玉楼的半人半灵,拥有使用剑术程度的能力. 题目描述 有一天,妖梦正在练习剑术.地面上摆放了 ...
- 面试必问---HashMap原理分析
一.HashMap的原理 众所周知,HashMap是用来存储Key-Value键值对的一种集合,这个键值对也叫做Entry,而每个Entry都是存储在数组当中,因此这个数组就是HashMap的主干.H ...
- DELL EqualLogic PS存储硬盘故障数据恢复成功案例分享
DELL EqualLogic PS4000采用虚拟ISCSI SAN阵列,为远程或分支办公室.部门和中小企业存储部署带来企业级功能.智能化.自动化和可靠性.以简化的管理.快速的部署及合理的价格满足了 ...
- day-6 机器学习概念及应用
学习玩Python基础语法,今天开始进行机器学习,首先了解下机器学习和深度学习的一些基本概念和术语: 1. 机器学习概念及应用 2. 深度学习概念及应用 3. 机器学习基本术语及举例 4. 机 ...