Redux进阶(一)
State的不可变化带来的麻烦
在用Redux处理深度复杂的数据时会有一些麻烦。由于js的特性,我们知道当对一个对象进行复制时实际上是复制它的引用,除非你对这个对象进行深度复制。Redux要求你每次你返回的都是一个全新的State,而不是去修改它。这就要求我们要对原来的State进行深度复制。这往往带来复杂的操作(查找,合并)。一种简单的情况是通过扩展符号或者Object.assign来处理:
return {
...state,
data: {
...state.data,
id: 5
}
}
这种方式在处理简单的数据来说是比较方便的,但是如果遇到更深一级的数据结构时会显得很无力,而且代码会变得冗长。不仅仅如此,当我们要处理一个包含着对象的数组时,我们要怎么办才好呢?我想,除了深度复制数组然后修改新的数组之外大概没有其他的方法了吧?而且很重要的一点是,如果你对原来整个数组进行了复制,那么绑定了数据的UI会自动渲染,即使它们的数据没有发生变化,简单来说,就是你修改了某一条表格数据,但是界面上整个表格被重新渲染了:
const TablesSource = {
query: 'tables',
tableId: 10,
data: [{
key: 11,
name: '胡彦斌',
age: 32,//我要修改这里,要复制整个数组后修改新的吗?
address: '西湖区湖底公园1号'
}, {
key: 12,
name: '胡彦祖',
age: 42,
address: '西湖区湖底公园1号'
}]
};
在Redux官方文档中提到了一种解决方案,即范式化数据:概括起来就一句话:减少层级,唯一id索引,用后端建表的方法构建我们的数据结构。其中最重要原则无非是扁平化和关联性。最终我们需要将数据形式转化成以下格式:
{
"entities": {
"bykey": {
"11": {
"key": 11,
"name": "胡彦斌",
"age": 32,
"address": "西湖区湖底公园1号"
},
"12": {
"key": 12,
"name": "胡彦祖",
"age": 42,
"address": "西湖区湖底公园1号"
}
},
"table": {
"10": {
"query": "tables",
"tableId": 10,
"data": [
11,
12
]
}
}
},
"result": 10
}
按照卤煮的理解,范式化数据无非就是给对象瘦瘦身,再深的层级,我们也尽量将它们扁平化,这样会减少我们对State的查找带来的性能消耗。然后是建立索引表,标识每组数据之间的联系。那么怎么样才能得到我们想要的数据呢?
normalizr方法使用指南
官方最荐normalizr模块,它的用法还是需要时间的去研究的。下面我们就以上面的数据为示例,说明它的用法:
$ npm i normalizr -S //下载模块
.........
import {normalize, schema} from 'normalizr';//日常导入,没问题
//原始数据
const TablesSource = {
query: 'tables',
tableId: 10,
data: [{
key: 11,
name: '胡彦斌',
age: 32,
address: '西湖区湖底公园1号'
}, {
key: 12,
name: '胡彦祖',
age: 42,
address: '西湖区湖底公园1号'
}]
};
//创建实体,名称为bykey,我们看到它的第二个参数是undefined,说明它是最后一层级的对象
const bykey = new schema.Entity('bykey', undefined, {
idAttribute: 'key'
});
//创建实体,名字为table,索引是tableid。
const table = new schema.Entity('table', {
data: [bykey] //这里需要说明这些实体的关系,意思是bykey原来table下面的是一个数组,他对应的是data数据,bykey将会取这里的数据建立一个以key为索引的对象。
}, {
idAttribute: 'tableId'//以tableId为为索引
});
const normalizedData = normalize(TablesSource, table);//生成新数据结构
说明:new schema.Entity的第一个参数表示你创建的最外层的实体名称,第二个参数是它和其他新创建的实体的关系,默认是最小的层级,即它只是最后一层,不包含其他层级了。第三个参数里面有个idAttribute,指的是以哪个字段为索引,默认是"id",它也可以是个参数,返回你自己构造的唯一值,记住,是唯一值。按照这样的套路,你可以随意构建你想要的扁平化数据结构,无论源数据的层级有多深。我们最终都会得到希望的数据结构。
{
"entities": {
"bykey": {、、实体名称
"11": {//我们之前设置的唯一所用key
"key": 11,
"name": "胡彦斌",
"age": 32,
"address": "西湖区湖底公园1号"
},
"12": {
"key": 12,
"name": "胡彦祖",
"age": 42,
"address": "西湖区湖底公园1号"
}
},
"table": {//实体名
"10": {、、唯一所用tableid
"query": "tables",
"tableId": 10,
"data": [ //data变成了储存key值索引的集合了!因为在之前我们说明了两个实体之间的关系 data: [bykey]
11,
12
]
}
}
},
"result": 10//这里同样储存着table实体里面的索引集合 normalizr(TableSource, table)
}
github上有详细的官方文档可供查找,卤煮在此只是简单的说明一下用法,诸位可以仔细观察文档上的用法,不需要多少时间就可以熟练掌握。到此为止,万里长城,终于走完了第一步。
如何将范式化数据后再次转化
什么?好不容易转化成自己想要的数据结构,还需要再次转化吗?很遗憾告诉你,是的。因为范式化后的数据只便于我们在维护Redux,而界面业务渲染的数据结构往往跟我们处理后的数据是不一样的,举个栗子:bootstrap或者ant.design的表格渲染数据结构是这个样的:
const dataSource = [{
key: '1',
name: '胡彦斌',
age: 32,
address: '西湖区湖底公园1号'
}, {
key: '2',
name: '胡彦祖',
age: 42,
address: '西湖区湖底公园1号'
}];
因而在界面引用State上的数据时,我们需要一个中介,把范式化的数据再次转化成业务数据结构。我相信这个步骤十分简单,只需要写一个简单的转换器就行了:
const transform = (source) => {
const data = source.entities.bykey;
return Object.keys(data).map(v => data[v]);
};
const mapStateToProps = (state,ownProps) => ({table: transform(state)})
export default connect(mapStateToProps)(view)
如果你在mapStateToProps里面断点调试,你会发现每一次dispatch都会强行执行mapStateProps方法保证对象的最新状态(除非你引用的是基础类型数据),因此,不管界面的操作是如何,被connect数据都会被强行执行一次,虽然界面没有变化,但是显然,js的性能会有折扣,尤其是对深度对象的复杂处理。因此,官方推荐我们创建可记忆的函数高效计算Redux Store里面的衍生数据。
Reselect方法使用指南
//缓存data里面的索引
const reNormalDataSource = (state, props) => state.app.entities.table['10'].data;
//缓存bykey里面对得基础数据
const reNormal = (state, props) => state.app.entities.bykey;
// 缓存计算结果
const createNormalTableData = createSelector([reNormalDataSource, reNormal], (keys, source) => keys.map(item => source[item]));
//每次当mapStateToProps重新执行时,会储存上次计算的结果,它只会重新计算变化的数据,其他非相关变化不做计算
const mapStateToProps = (state, own) => ({source: createNormalTableData(state)});
我在这里做了个耍了点花样,你可以看到,我是按照table.data这个数组来查找界面业务数据的。这种操作可以使得我们只需要关心table.data这个简单的一维数组,在删除或者添加一条数据的时候显得尤为有用。
我们最后为了计算state,引用了dot-prop-immutable模块,他是immutable的扩展,对于数据计算非常高效。我接着使用了另外一个dot-prop-immutable-chain模块,它增加了dot-prop-immutable的链式用法。关于dot-prop-immutable的用法卤煮不再详细说明,在后面给出的例子中一眼就能看明白,而且官方文档上也有详细说明。下面我们通过一个表格增删查改来实际展示我们这次的解决方案。
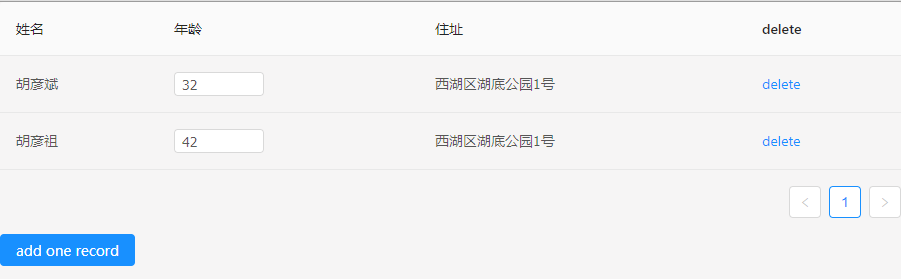
import {normalize, schema} from 'normalizr';
import dotProp from 'dot-prop-immutable-chain';
const reducer = (state = normalizedData, action) => {
switch(action.type) {
//修改一条数据
case 'EDITOR':
return dotProp(state).set(`entities.bykey.${action.key}.age`, action.age).value();
//添加一条数据
case 'ADD':
const newId = UID++;
return dotProp(state).set(`entities.bykey.${newId}`, Object.assign({}, model, {key: newId}))//添加一条新数据
.merge(`entities.table.10.data`, [newId]).value();//新数据的data中的引用
//删除一条数据
case 'DELETE':
const index = state.entities.table['10'].data.indexOf(Number(action.key));
//可以看到,由于我们界面数据是根据data里面的项来决定的,因此我们只需要处理data这个简单的一维数组,而这显然要容易维护得多
return dotProp(state).delete(`entities.table.10.data.${index}`).value();
}
return state;
};
瞧,我们展示了整个reducer,相信它已经变得容易维护得多了,并且由于使用了范式化数据结构以及immutable的扩展模块,不仅仅提升了计算性能,减少界面的的渲染,而且还符合Redux的State不可修改的原则。
结束语
React+Redux组合在实际应用过程中需要优化的地方还很多,这里只是简单展示其中的一个小点。虽然在计算dom界面变化时React已经做得足够好,但并不意味着我们可以不用为界面渲染问题背锅,React肩负了多数界面更新计算的任务,而让前端开发人员更多地去处理数据,因此,我们可以在这里层多花点时间把项目做好。
参考资料
Redux进阶(一)的更多相关文章
- Redux进阶(像VUEX一样使用Redux)
更好的阅度体验 前言 redux的问题 方案目标 如何实现 思考 前言 Redux是一个非常实用的状态管理库,对于大多数使用React库的开发者来说,Redux都是会接触到的.在使用Redux享受其带 ...
- Redux进阶(Immutable.js)
更好的阅读体验 更好的阅度体验 Immutable.js Immutable的优势 1. 保证不可变(每次通过Immutable.js操作的对象都会返回一个新的对象) 2. 丰富的API 3. 性能好 ...
- redux进阶 --- 中间件和异步操作
你为什么需要异步操作? https://stackoverflow.com/questions/34570758/why-do-we-need-middleware-for-async-flow-in ...
- (六)Redux进阶
1 UI组件与容器组件的拆分 UI组件(傻瓜组件):只负责页面显示,没有任何逻辑 容器组件(聪明组件):并不去管UI到底长成什么样,关注的是整个业务逻辑 2 无状态组件 一个普通的函数就是无状态组件 ...
- Redux 进阶之 react-redux 和 redux-thunk 的应用
1. react-redux React-Redux 是 Redux 的官方 React 绑定库. React-Redux 能够使你的React组件从Redux store中读取数据,并且向 stor ...
- Redux进阶(Redux背后的Flux)
简介 Flux是一种搭建WEB客户端的应用架构,更像是一种模式而不是一个框架. 特点 单向数据流 与MVC的比较 1.传统的MVC如下所示(是一个双向数据流模型) 用户触发事件 View通知Contr ...
- Redux学习(3) ----- 结合React使用
Redux 和React 进行结合, 就是用React 做UI, 因为Redux中定义了state,并且定义了改变或获取state的方法,完全可以用来进行状态管理,React中就不用保存状态了,它只要 ...
- 理解Redux以及如何在项目中的使用
今天我们来聊聊Redux,这篇文章是一个进阶的文章,建议大家先对redux的基础有一定的了解,在这里给大家推荐一下阮一峰老师的文章: http://www.ruanyifeng.com/blog/20 ...
- React (native) 相关知识
container component provider组件 react里的redux进阶玩法 react组件的生命周期 conductor / componentWillMount / render ...
随机推荐
- SSM-SpringMVC-03:SpringMVC执行流程一张有意思的图
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 上次的图也不全,这次的图也不是完整版,但是多了一个拦截器,我觉得挺有意思的,我就放上来了 他Handler ...
- InnoDB存储引擎结构介绍
Ⅰ.InnoDB发展史 时间 事件 备注 1995 由Heikki Tuuri创建Innobase Oy公司,开发InnoDB存储引擎 Innobase开始做的是数据库,希望卖掉该公司 1996 My ...
- js术语扫盲贴:XHR、RegExp、call-apply、prototype
(1) XHR:xml httprequestXHR注入:XHR 注入技术是通过XMLHttpRest来获取javascript的.但与eval不同的是,该机制是通过创建一个script的DOM元素, ...
- Python Redis 的安装
安装 可以去pypi上找到redis的Python模块: http://pypi.python.org/pypi?%3Aaction=search&term=redis&submit= ...
- 深浅拷贝,原生和JQuery方法实现
7-17: 1:e.target.parentNode.remove();成功,查询一下JS原生的remove方法 2:复习JS DOM的原生操作方法,比如innerHTML(),insertBefo ...
- 巩固java(三)---java修饰符
正文: 下面的表格列出了java中修饰符的一些信息: 修饰符名称 类型 类 变量 方法 abstract 非访问控制符 抽象类 -- 抽象方法 final ...
- Windows下python3和python2同时安装python2.exe、python3.exe和pip2、pip3设置
1.添加python2到系统环境变量 打开,控制面板\系统和安全\系统,选择高级系统设置,环境变量,选择Path,点击编辑,新建,分别添加D:\Python\python27和D:\Python\py ...
- Python-分支循环- if elif for while
分支与循环 条件是分支与循环中最为核心的点,解决的问题场景是不同的问题有不同的处理逻辑.当满足单个或者多个条件或者不满足条件进入分支和循环,这里也就说明这个对相同问题处理执行逻辑依据具体参数动态变化, ...
- segment.go
package sego // 文本中的一个分词 type Segment struct { // 分词在文本中的起始字节位置 start int // 分词在文本中的结束字节 ...
- GIT的使用流程
GIT的使用流程 1 github注册流程 1 进入github官网:https://github.com/ 2 注册一个自己的github账号 3 右上角选择New repository 4 进入c ...