MySQL 主从复制实战解析
前言:前面几篇文章讲解了在应用层读写分离的配置和使用,这篇文章将来个主从复制的实战解析。
说明:主从复制,读写分离结构图
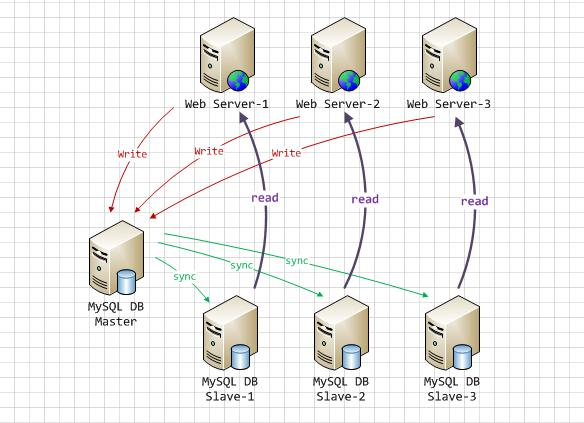
原理图
主库生成一个线程: Binlog Dump线程
1、此线程运行在主库,当主从都配置好后,从库运行START SLAVE启动复制后,会在主库上生成一个BinlogDump线程,该线程的主要作用就是读取主库Binlog事件,然后发送到从库(从库的I/O线程)。 从库生成两个线程:一个I/O线程,一个SQL线程;
1、i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
2、主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
3、SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;
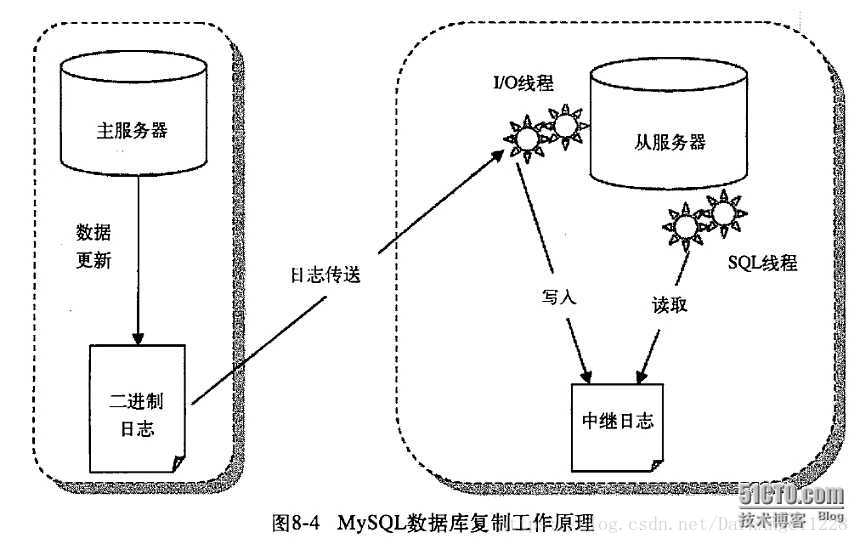
详细流程如下:
1、主库验证从库发起的连接;
2、主库为从库开启一个线程;
3、从库将主库日志的偏移位告诉主库;
4、主库检查该值是否小于当前二进制日志偏移位。
5、如果小于,则通知从库可以取数据。
6、从库持续从主库取数据,直至取完,这时,从库线程进入睡眠,主库线程同时进入睡眠。
7、当主库有更新时,主库线程被激活,并将二进制日志推送给从库,并通知从库线程进入工作状态。
8、从库SQL线程执行二进制日志,随后进入睡眠状态。
存在问题:
1、主库宕机后,数据可能丢失
解决:先配置主主同步,再用keepalived实现双机热备自动切换,具体请百度双机热备
2、从库只有一个sql Thread,主库写压力大,复制很可能延时
说明:当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。
解决:
1、用多台slave来分摊请求
2、关闭slave的一些日志功能,如sync_binlog,innodb_flushlog,innodb_flush_log_at_trx_commit
3、更好的硬件
一、环境介绍
主:Linux(centos 7) MySQL(5.6.4) IP:192.168.8.228
从:Linux(centos 7) MySQL(5.6.4) IP:192.168.8.146
二、配置主库环境
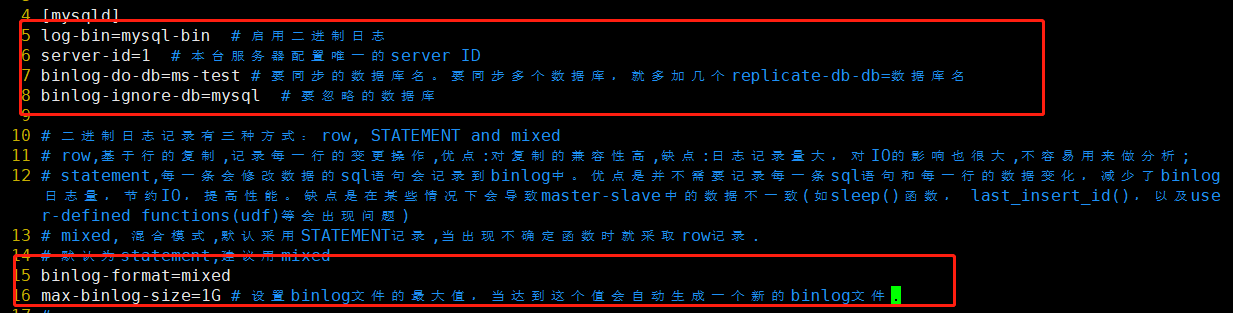
1、修改mysql配置文件 my.cnf,加入如下红框内容
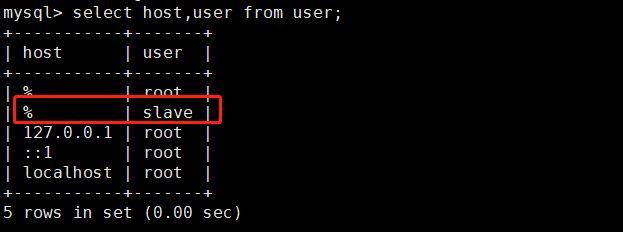
2、添加从库权限账号 注释:在主服务器上为从服务器分配一个账号,就像一把钥匙,从服务器拿着这个钥匙,才能到主服务器上来共享主服务器的日志文件。
提醒:记得 FLUSH PRIVILEGES 刷新权限

3、查看主服务器当前二进制日志名和偏移量
解释:这个操作的目的是为了在从数据库启动后,从这个点开始进行数据的恢复

出现以上结果,说明主库设置完毕了
三、配置从库环境
1、修改从库mysql配置文件 my.cnf,加入如下红框内容

2、配置连接主库参数
说明:不支持在配置文件中加这些参数,mysql5.5+版本主从复制不支持这些变量,需要在从库上用命令来设置

3、启动slave进程
从库基本命令:
启动:slave start
停止:slave stop

4、查看slave的状态,如果下面两项值为YES,则表示配置正确:
1)、Slave_IO_Running: Yes
2)、Slave_SQL_Running: Yes
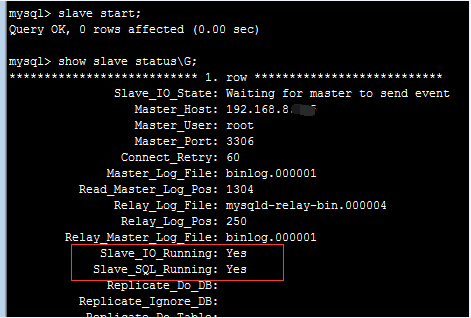
到此,从库配置完成,只等主库更新数据了
注意:上一步可能会遇到的问题(一定要记得先停止从库改完后再启动从库) 错误:当执行show slave status\G 时,发现slave_IO_Running:no时,并且下面的error_log还报错了,类似这种 Slave can not handle replication events with时 原因:是你的master和slave的mysql版本不一样,mysql5.6的binlog_checksum默认设置的是crc32。 而MySQL5.5 或者更早的版本默认值是None,所以可以将两个服务器的校验都设为none,或者crc32。
四、开始实验
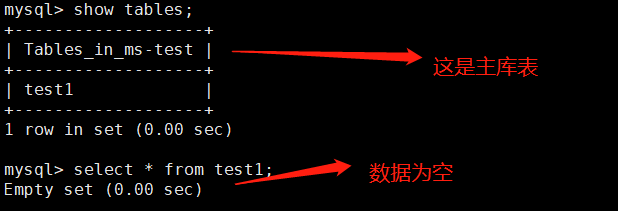
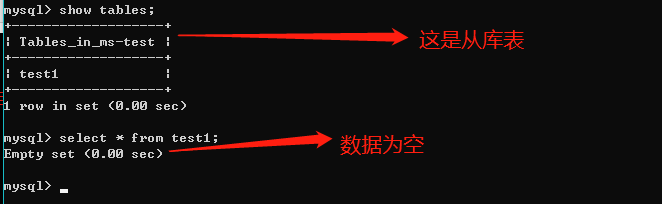
1、主库表test1和从库表test1里面都没有数据
2、在主库中添加一条数据,再查看从库表是否有这条数据
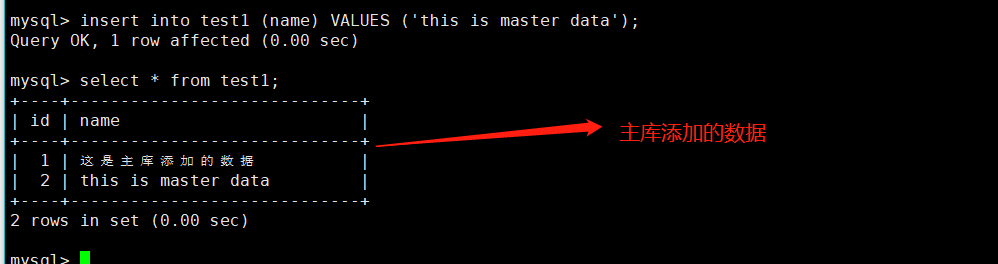

以上就是本篇文章的全部内容了,关于主从复制--读写分离就到这里了。
参考链接:https://www.cnblogs.com/zhoujie/p/mysql1.html
MySQL 主从复制实战解析的更多相关文章
- mySQL主从复制实战
随着访问量的不断增加,单台MySQL数据库服务器压力不断增加,需要对MYSQL进行优化和架构改造,MYQSL优化如果不能明显改善压力情况,可以使用高可用.主从复制.读写分离来.拆分库.拆分表来进行优化 ...
- 14、mysql主从复制实战
14. 1.服务器准备: 一台服务器,多实例,客户端编码是utf8,服务端编码是utf8; [root@backup 3308]#netstat -tunlp | grep 330 tcp 0 0 0 ...
- 13、mysql主从复制原理解析
13.1.mysql主从复制介绍: 1.普通文件,磁盘上的文件的同步方法: (1)nfs网络文件共享可以同步数据存储: (2)samba共享数据: (3)ftp数据同步: (4)定时任务:cronta ...
- 详解MySQL主从复制实战 - 基于GTID的复制
基于GTID的复制 简介 基于GTID的复制是MySQL 5.6后新增的复制方式. GTID (global transaction identifier) 即全局事务ID, 保证了在每个在主库上提交 ...
- MySQL(13)---MYSQL主从复制原理
MYSQL主从复制原理 最近在做项目的时候,因为部署了 MYSQL主从复制 所以在这里记录下整个过程.这里一共会分两篇博客来写: 1.Mysql主从复制原理 2.docker部署Mysql主从复制实战 ...
- 【大型网站技术实践】初级篇:搭建MySQL主从复制经典架构
一.业务发展驱动数据发展 随着网站业务的不断发展,用户量的不断增加,数据量成倍地增长,数据库的访问量也呈线性地增长.特别是在用户访问高峰期间,并发访问量突然增大,数据库的负载压力也会增大,如果架构方案 ...
- MySQL 5.7主从复制实战篇
MySQL 5.7主从复制实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装MySQL数据库并启动 1>.在MySQL官方下载相应的安装包(https://dev ...
- 九、linux-msyql下的mysql主从复制深度实战
1.上节基本诉说了mysql主从同步,这里想说明的是,其一从库在请求主库进行同步的时候,是主库的主线程进行用户名.密码的验证,在验证通过后,将请求转交给I/O线程负责同步:其二从库sql线程在读取中继 ...
- 实战-Mysql主从复制
前言: Mysql内建的复制功能是构建大型高性能应用程序的基础.由于目前mysql的高可用性架构MMM和MHA均建立在复制的基础之上,本文就mysql主从复制进行实战描述,希望对读者提供帮助.之前 服 ...
随机推荐
- vue-cli3 中跨域解决方案
此方案只能用于开发环境,线上最好设置同源策略(遇到个后端,装你妈批) 前后端不在同一服务器的情况下,前端要访问后端API,可通过在vue.config.js中配置代理服务器. 0:前提条件 1:安装v ...
- Windows有点腻了?不如试试Ubuntu.
最近在接触Python. 因为担心环境会向Java一样,很容易影响当前的工作电脑. 所以准备搭建一台虚拟机,不过Windows的尺寸是在太大了.所以,选择安装Ubuntu. Ubuntu官方网站地址: ...
- Android ble 蓝牙4.0 总结一
本文介绍Android ble 蓝牙4.0,也就是说API level >= 18,且支持蓝牙4.0的手机才可以使用,如果手机系统版本API level < 18,也是用不了蓝牙4.0的哦 ...
- Android 报错:error: too many padding sections on bottom border
一.发生错误 [我以为我做了一张完美的.9图片,没想到.9图片还需要画左边和上边,尴尬···] 二.解决方法 .9图片造成错误 [具体内容] 最后修改.9图为
- 如何知道一个EXE使用什么开发语言开发的
一般是看EXE调用哪些DLL,这可以使用VC++中的工具Dependency Walker,它可以列出静态链接的所有DLL. 如果EXE中的DLL包括MSVBVM60.DLL,则是使用VB 6.0开发 ...
- C# -- 使用 DriveInfo 获取磁盘驱动器信息
C# -- 使用 DriveInfo 获取磁盘驱动器信息 1. 代码实现 class Program { static void Main(string[] args) { GetComputerDi ...
- 记录Html+Css流程表格
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Vue-cli在webpack内使用雪碧图(响应式)
先执行install cnpm install webpack-spritesmith 文件位置 build\webpack.dev.conf.js 添加内容: const SpritesmithPl ...
- jcrop2.X 取消选框
(原) 官网 0.9.12 API 2.X API 在2.X以下在版本中,api提供了release()方法用于取消选框.但在2.X以上的版本中已经没有这个方法了.于是各种查找,终于解决了如何取消选框 ...
- 一起刷LeetCode
题目列表: 题目 解答 26. 删除排序数组中的重复项 https://www.cnblogs.com/powercai/p/10791735.html 25. k个一组翻转链表 https://ww ...