爬虫技术实现空间相册采集器V.0.0.1版本
一. 功能需求分析:
在很多时候我们需要做这样一个事情:我们想把我们QQ空间上的相册高清图像下载下来,怎么做?到网上找软件?答案是否定的,理由之一:网上很多软件不知有没有病毒,第二它有可能捆了很多不必要的软件,对我们不友好,而且有些需要费用,那该怎么办?难道就无计可施了吗?答案又是否定的,我们可以通过爬虫技术完成一个QQ或者微信相册空间下载器,根据功能需求不同我们可以去改进它让它成为可批量下载的QQ空间下载器,或者做成多线程,图形化界面多功能采集器
二. 环境搭建:
Window+Chrome火狐浏览器+火狐驱动+requests/Linux+phantomjs+phantomjs驱动+requests
三. 技术点分析:
QQ空间是腾讯的产品通过浏览器F12分析请求我们得到与相册相关的链接ajax:
通过实验我们获取到与数据请求成功相关的有几个参数:
g_tk,uin,hostUin,pageNum,pagestart , topicId
其中hostuin是要下载的QQ号,因为下载相册必须要自己先登录所以uin是自己QQ,topicid是QQ相册id可以通过第一个链接获取到,g_tk是QQ加密算法生成的一个数字串,用户在获取登录状态后还必须加上g_tk才能正确返回数据然后通过获取到的图片链接下载图片
一. 技术难点分析:
其他参数都很好获取,就是这个g_tk困扰了我很久,后来通过分析请求和网上找资料最终解决了这个问题,首先我们需要获取g_tk是如何计算的,由于Firefox自带的控制台功能不够用, 这里用Firefox+Firebug来做,其它浏览器应该也有对于的插件F12打开Firebug控制台,刷新QQ空间登录后的界面,然后点击“脚本”

function (a){
a=QZFL.util.URI(a);
var b;
a&&(a.host&&0<a.host.indexOf("qzone.qq.com")?b=QZFL.cookie.get("p_skey"):
a.host&&0<a.host.indexOf("qq.com")&&(b=QZFL.cookie.get("skey")));
b||(b=QZFL.cookie.get("skey")||QZFL.cookie.get("rv2"));
a=5381;
for(var c=0,d=b.length;c<d;++c)
a+=(a<<5)+b.charAt(c).charCodeAt();
return a&2147483647
}
我们可以看到它的值与p_skey或者skey有关,顺序是如果有p_skey那就通过p_skey计算。
终上所述我们得到g_tk计算方式:
def g_tk(p_skey):
hash = 5381;
for i in p_skey:
hash += (hash << 5)
+ ord(i)
return hash &
0x7fffffff
将上面代码整合我们很快就能得到我们想要数据,而p_skey在登录成功后的cookies中,我们为了方便无需通过分析cookie然后传入固定g_tk,我采用了一种很方便的方法,先用自动化框架登录成功后得到我们想要的cookie:

通过正则表达式得到p_skey。
一. 效果图:
以输入我的QQ为例

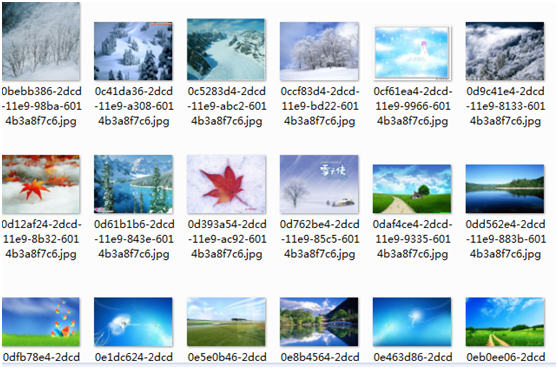
爬虫技术实现空间相册采集器V.0.0.1版本的更多相关文章
- swing版网络爬虫-丑牛迷你采集器2.0
swing版网络爬虫-丑牛迷你采集器2.0 http://www.javacoo.com/code/704.jhtml 整合JEECMS http://bbs.jeecms.com/fabu/3186 ...
- WEB页面采集器编写经验之一:静态页面采集器
严格意义来说,采集器和爬虫不是一回事:采集器是对特定结构的数据来源进行解析.结构化,将所需的数据从中提取出来:而爬虫的主要目标更多的是页面里的链接和页面的TITLE. 采集器也写过不少了,随便写一点经 ...
- 使用webcollector爬虫技术获取网易云音乐全部歌曲
最近在知乎上看到一个话题,说使用爬虫技术获取网易云音乐上的歌曲,甚至还包括付费的歌曲,哥瞬间心动了,这年头,好听的流行音乐或者经典老歌都开始收费了,只能听不能下载,着实很郁闷,现在机会来了,于是开始研 ...
- 【RSYSLOG】rsyslog作为日志采集器安装配置说明
RSYSLOG is the rocket-fast system for log processing. About 由于环境基于CentOS 6.7 x64,rsyslog本身就是OS的组件,由于 ...
- 淘宝IP地址库采集器c#代码
这篇文章主要介绍了淘宝IP地址库采集器c#代码,有需要的朋友可以参考一下. 最近做一个项目,功能类似于CNZZ站长统计功能,要求显示Ip所在的省份市区/提供商等信息.网上的Ip纯真数据库,下载下来一看 ...
- javacoo/CowSwing 丑牛迷你采集器
丑牛迷你采集器是一款基于Java Swing开发的专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从 网页上抓取结构化的文本.图片.文件等资源信息,可编辑筛选处理后选择发布到网站 ...
- [WPF源代码]QQ空间相册下载工具
放一个WPF源代码,源代码地址 http://download.csdn.net/detail/witch_soya/6195987 代码没多少技术含量,就是用WPF做的一个QQ空间相册下载工具,效果 ...
- .net 爬虫技术
关于爬虫 从搜索引擎开始,爬虫应该就出现了,爬的对象当然也就是网页URL,在很长一段时间内,爬虫所做的事情就是分析URL.下载WebServer返回的HTML.分析HTML内容.构建HTTP请求的模拟 ...
- 网络爬虫技术Jsoup——爬到一切你想要的(转)
转自:http://blog.csdn.net/ccg_201216323/article/details/53576654 本文由我的微信公众号(bruce常)原创首发, 并同步发表到csdn博客, ...
随机推荐
- geodocker-geomesa安装指南
最近研究geopyspark原本以为大数据研究能告一段落,因为... 开玩笑的,还要一起建设社会主义呢!! 背景 geotrellis作为一个处理遥感数据的框架,对于遥感数据支 ...
- Ubuntu移除mysql后重新安装
首先删除mysql: sudo apt-get remove mysql-* 然后清理残留的数据 dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg ...
- Ftp修改为主被动模式命令
FTP是有两种数据连接模式的,主动模式和被动模式. PORT(主动)方式:客户端向服务器的FTP端口(默认是21)发送连接请求,服务器接受连接,建立一条命令链路.当需要传送数据时,客户端在命令链路上用 ...
- springboot 多线程执行
一.springboot开线程执行异步任务 1.Spring通过任务执行器TaskExecutor,来实现多线程和并发编程,使用ThreadPoolTaskExecutor可实现一个基于线程池的Tas ...
- Linux iptables用法与NAT
1.相关概念 2.iptables相关用法 3.NAT(DNAT与SNAT) 相关概念 防火墙除了软件及硬件的分类,也可对数据封包的取得方式来分类,可分为代理服务器(Proxy)及封包过滤机制(IP ...
- 微信小程序客服消息开发实战:实时在手机上接收小程序客服消息通知,以及在手机上回复
在微信小程序开发中,可以非常方便的集成客服功能,只需要一行代码便可以将用户引导至客服会话界面.这行代码就是: <button open-type="contact" bind ...
- 从Android源码修改cpu信息
cpuinfo 网上的文章都是怎么查看/proc/cpuinfo,一直以为这种东西没法改呢,我还是太天真了./proc/cpuinfo是个文件,只读,想直接写肯定不行的.今天研究了一下,发现它的输出逻 ...
- spring的核心组件及作用(一)
Spring的核心组件有: Context Core Bean. 如果要在这三个核心组件上挑出一个最核心的组件,那就是Bean组件了. Spring的特性功能有:WEB ORM AOP ...
- Python-图像处理库PIL图像变换transpose和transforms函数
1.transpose有这么几种模式FLIP_LEFT_RIGHT ,FLIP_TOP_BOTTOM ,ROTATE_90 ,ROTATE_180 ,ROTATE_270,TRANSPOSE ,TRA ...
- .NET Core微服务之基于Ocelot实现API网关服务(续)
Tip: 此篇已加入.NET Core微服务基础系列文章索引 一.负载均衡与请求缓存 1.1 负载均衡 为了验证负载均衡,这里我们配置了两个Consul Client节点,其中ClientServic ...