Solr搜索引擎搭建详细过程
1 什么是solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr可以独立运行在Jetty、Tomcat等这些Servlet容器中。
Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
使用Solr 进行创建索引和搜索索引的实现方法很简单,如下:
* 创建索引:客户端(可以是浏览器可以是Java程序)用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr服务器根据xml文档添加、删除、更新索引 。
* 搜索索引:客户端(可以是浏览器可以是Java程序)用 GET方法向 Solr 服务器发送请求,然后对Solr服务器返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建页面UI的功能,但是
提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
简单来说:Solr类似我们开发的web项目,是一个war包,把它放在tomcat下直接运行就好
2 Solr和Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索应用。Lucene仅提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索应用。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
简单来说:如果不知道Lucene,那么配置Solr方面将寸步难行
这里是一篇以前写的Lucene的使用案列:http://www.cnblogs.com/xuyiqing/p/8696660.html
有一个问题:我们可以使用数据库查询,为什么要用Solr呢?
答案:最大的一个原因是效率会高 很 多 ,还有其他原因,比如SQL无法做到相关度排序等等
另一个问题:我们为什么不用Lucene呢?
答案:Lucene的工作量过大,Solr是基于Lucene的框架,便捷完善,可配置可扩展,可以高效完成站内搜索功能
接下来就开始:
搭建solr服务器(Tomcat):
注意:solr本身可以运行,不过它是运行在jetty上的,相比Tomcat显得不稳定,所以我们要在tomcat中搭建Solr
准备一个Tomcat7和Solr4.10.3:网上下载即可

按这个路径找到solr.war复制到Tomcat的webapp下

然后把这个war包解压了:注意解压后把war包删了,因为solr文件夹里要添加其他东西,但是Tomcat每次启动都会解压war包覆盖,所以需要删了war包
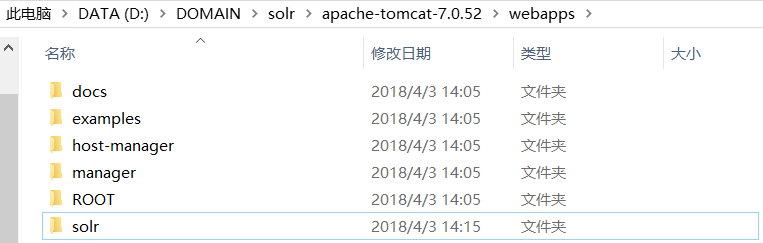
按目录找到这5个包:
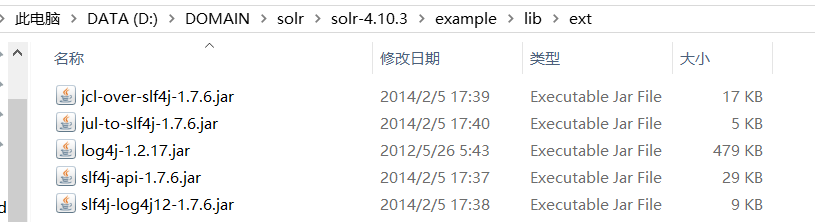
把它们复制到这个文件夹中:

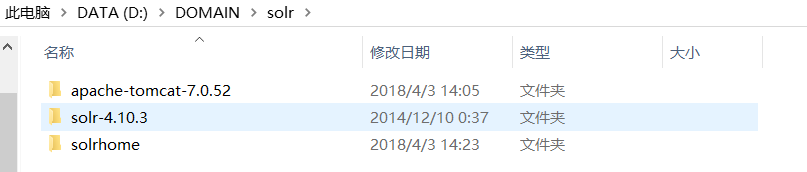
接下来:在刚才的文件夹下新建一个文件夹:solrhome(充当索引库)
把这个路径的这些东西复制过去:
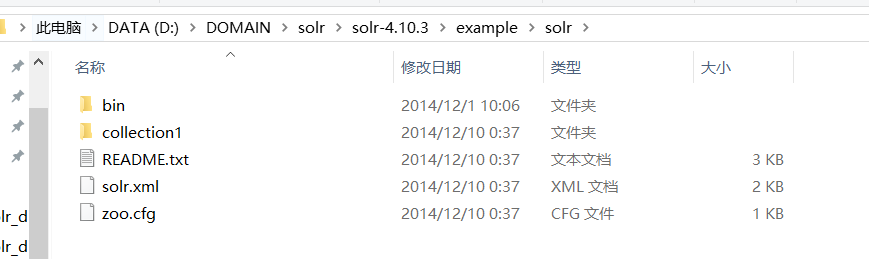
然后修改下这个配置文件:
在40行处修改如下:

好的,启动Tomcat:

我访问8080:
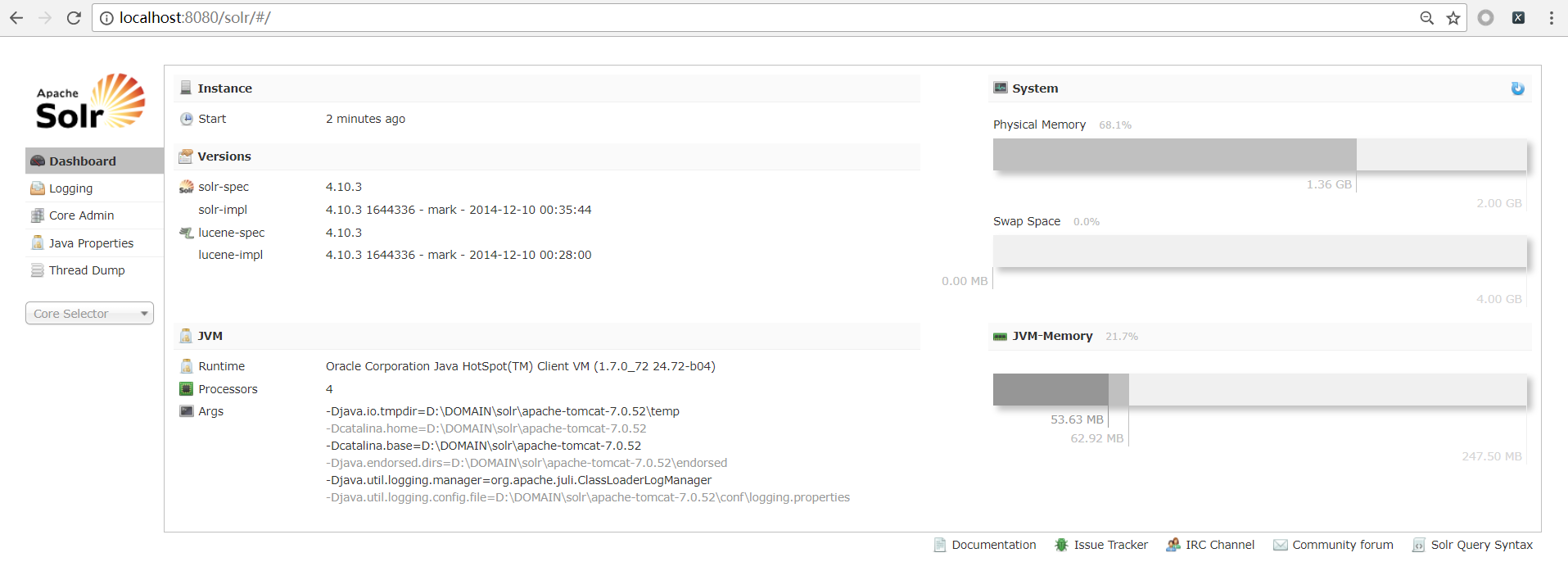
到这里,搭建就成功了!
在这个页面就可以增删改查索引了!
比如增(注意必须有id):

查:
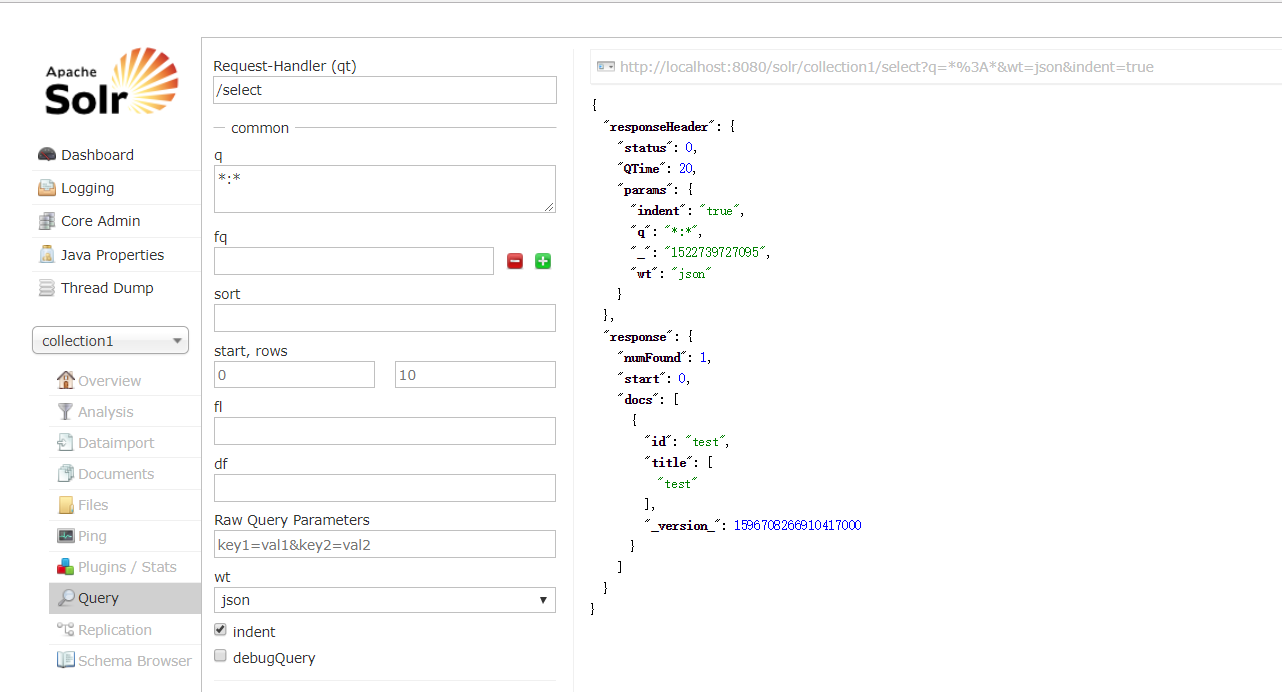
但是还没有结束:
接下来修改配置文件:
打开这里:我们需要关注的是这两个配置文件
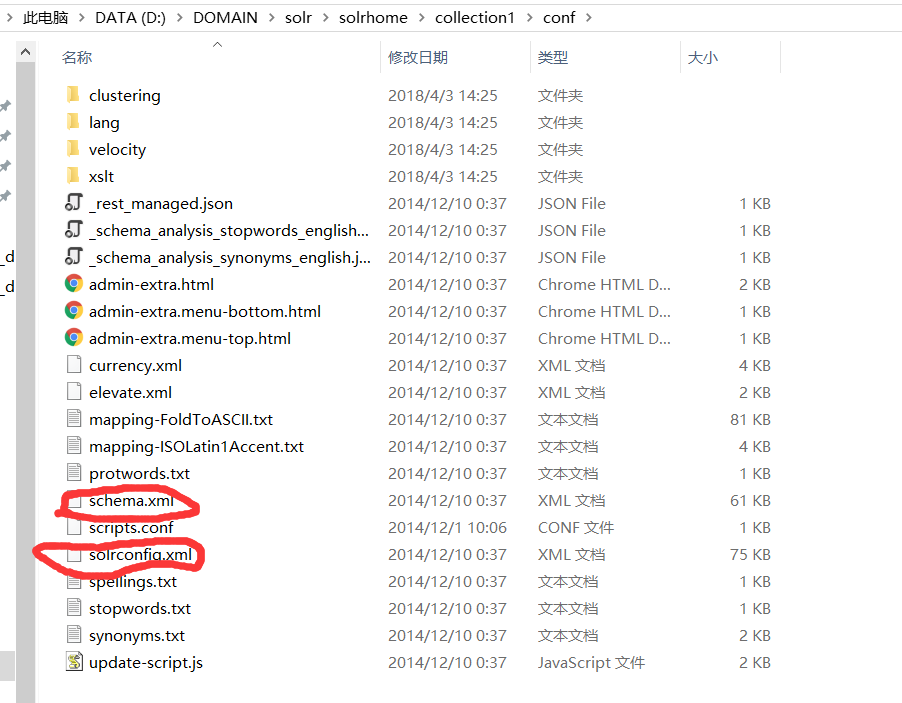
好的,接下来就配置它们:
schema.xml:配置域相关的信息
可以打开看看,里面是域的相关信息,只有里面存在的域才可以使用!
当然,里面还有一种动态域,比如*_s,*_i等等,前缀可以任意写
看看另一个配置文件:
这里要配置中文分词器
先导入这个包:

新建一个文件夹放入IK分析器配置文件:

这三个配置文件Lucene文章中:http://www.cnblogs.com/xuyiqing/p/8696660.html
注意三个文件的格式:UTF-8无BOM格式编辑
接下来:在刚才提到的schema.xml中配置:加上这一段
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> <field name="title_ik" type="text_ik" indexed="true" stored="true"/>
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
新建的这两个域支持IK分析器
测试下:重启Tomcat
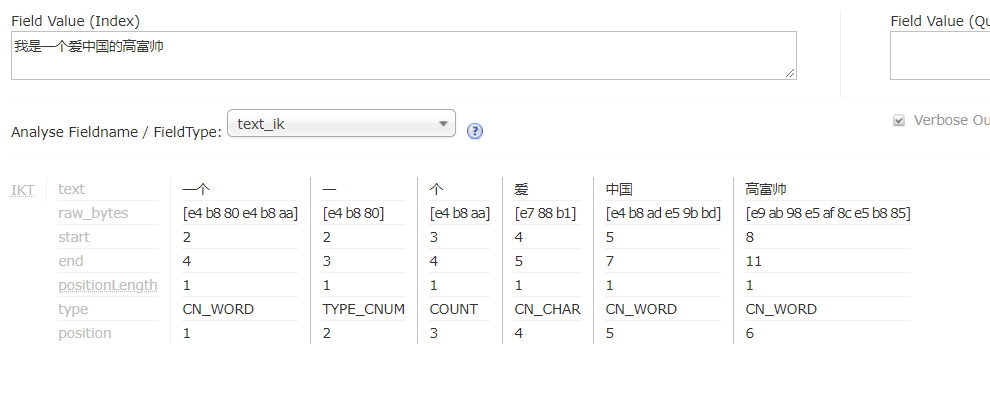
分析成功!
接下来,介绍下如何从数据库导入数据:
首先,导入包(注意位置):

打开上面提到过的solrconfig.xml配置文件:
加入下面这些代码:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
在当前目录下新建一个data-config.xml:
这里导入以前我做的BBS项目中用户的表
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/Blog"
user="root" password="xuyiqing"/>
<document>
<entity name="user"
query="select * from blog_user" >
<field column="u_id" name="id"></field>
<field column="username" name="username"></field>
<field column="u_password" name="password"></field>
<field column="qq" name="qq"></field>
<field column="avatar" name="avatar"></field>
<field column="article_count" name="count"></field>
</entity>
</document>
</dataConfig>
只写这些不够的,还要在schema.xml中配置域:
<field name="username" type="text_ik" indexed="true" stored="true"/>
<field name="password" type="text_ik" indexed="false" stored="false"/>
<field name="qq" type="text_ik" indexed="true" stored="true"/>
<field name="avatar" type="string" indexed="false" stored="true"/>
<field name="count" type="float" indexed="true" stored="true"/>
保存!重启tomcat

导入成功!
我们查询一下(成功):

可以按条件查询:
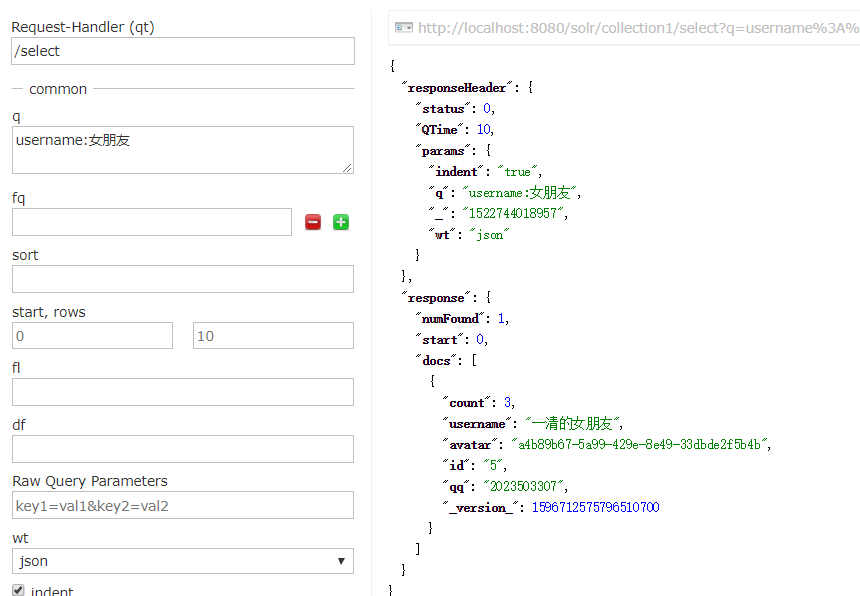
到这里搭建Solr就成功了
SolrJ:通过SorlJ的API操作Solr:
陆续更新
如果有大佬愿意打赏,感谢:

Solr搜索引擎搭建详细过程的更多相关文章
- Centos 6.5 GitLab安装配置搭建详细过程
GitLab搭建详细过程 一.前提 系统:Centos 6.5 软件版本:gitlab-7.8.4 Selinux:关闭 防火墙规则:先清空(搭建好了后续自己添加相关放行规则) 二.yum源配置和 ...
- IDEA SpringBoot多模块项目搭建详细过程(转)
文章转自https://blog.csdn.net/zcf980/article/details/83040029 项目源码: 链接: https://pan.baidu.com/s/1Gp9cY1Q ...
- centos下hadoop2.6.0集群搭建详细过程
一 .centos集群环境配置 1.创建一个namenode节点,5个datanode节点 主机名 IP namenodezsw 192.168.129.158 datanode1zsw 192.16 ...
- GitLab搭建详细过程
一.前提 系统:Centos 6.5 软件版本:gitlab-7.8.4 Selinux:关闭 防火墙规则:先清空(搭建好了后续自己添加相关放行规则) 二.yum源配置和相关依赖包 1.添加epel源 ...
- windows 2008r2+php5.6.28环境搭建详细过程
安装IIS7 安装php 网站验证 安装IIS7 1.打开服务器管理器(开始-计算机-右键-管理-也可以打开),添加角色 直接下一步 勾选Web服务器(IIS),下一步,有个注意事项继续下一步(这里我 ...
- Learning Discriminative and Transformation Covariant Local Feature Detectors实验环境搭建详细过程
依赖项: Python 3.4.3 tensorflow>1.0.0, tqdm, cv2, exifread, skimage, glob 1.安装tensorflow:https://www ...
- Redis集群搭建详细过程整理备忘
三.安装配置 1.环境 使用2台centos服务器,每台机器上部署3个实例,集群为三个主节点与三个从节点: 192.168.5.144:6380 192.168.5.144:6381 192.168. ...
- windows 2008r2+php5.6.28搭建详细过程
安装IIS7 1.打开服务器管理器(开始-计算机-右键-管理-也可以打开),添加角色 直接下一步 勾选Web服务器(IIS),下一步,有个注意事项继续下一步(这里我就不截图了) 勾选ASP.NET会弹 ...
- Solr集群搭建详细教程(一)
一.Solr集群的系统架构 注:欢迎大家转载,非商业用途请在醒目位置注明本文链接和作者名dijia478,商业用途请联系本人dijia478@163.com. SolrCloud(solr 云)是So ...
随机推荐
- 【BZOJ3670】动物园(KMP算法)
[BZOJ3670]动物园(KMP算法) 题面 BZOJ 题解 神TM阅读理解题 看完题目之后 想暴力: 搞个倍增数组来跳\(next\) 每次暴跳\(next\) 复杂度\(O(Tnlogn)\) ...
- animate 动画滞后执行的解决方案
jQuery动画: animate 容易出现连续触发.滞后反复执行的现象: 针对 jQuery 中 slideUp.slideDown.animate 等动画运用时出现的滞后反复执行等问题的解决方法有 ...
- ORM Basic
ORM即object relational mapping 对象关系映射程序,可以在操作数据库的时候使用自有的语言而不必使用数据库的语言. 在python中,最强大的ORM框架就是SQLAlchemy ...
- IntelliJ IDEA 源值1.5已过时,将在未来所有版本中删除
1. 修改Maven的Settings.xml文件添加如下内容 <profile> <id>jdk-1.8</id> <activation> < ...
- linux修改时区
Linux修改时区 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任 CentOS6: 查看以前的时区: [root@localhost mysq ...
- Nginx配置ThinkPHP下的url重写(隐藏入口)
搭建好项目后,在网址上输入域名,只能访问首页,其他页面全是404. 在域名后面和控制器前面加上index.php就可以访问. 在tp5官网手册查找后进行配置修改. 打开nginx.conf 后 ,在s ...
- linux学习之路--(三)文件系统
一.文件系统 rootfs:根文件系统 FHS:linux /boot:系统启动相关的文件,如内核.initrd,grub(bootloader) /dev:设备文件:不存储内容,就是个访问入口 块设 ...
- Junit test使用
1.导入maven依赖 <dependency> <groupId>junit</groupId> <artifactId>junit</arti ...
- 自动识别移动端还是PC端
平时在开发中经常会遇到这样的需求,除了开发PC端之外,还会同时开发移动端.对于简单的页面,可以使用bootstrap之类的框架实现响应式页面,可是当页面很复杂的时候,就需要开发一个移动端页面,一个PC ...
- python全栈开发-Day2 布尔、流程控制、循环
python全栈开发-Day2 布尔 流程控制 循环 一.布尔 1.概述 #布尔值,一个True一个False #计算机俗称电脑,即我们编写程序让计算机运行时,应该是让计算机无限接近人脑,或者说人 ...