hadoop-3.0.0-beta1分布式安装
楼主是从Hadoop2.x版本过来的,在工作之余自己搭建了一套3.0的版本来耍一耍,此文章的前置环境准备工作省略。主要介绍一些和Hadoop2.x版本不同的安装之处
Hadoop版本:hadoop-3.0.0-beta1
JDK版本:jdk1.8.0_121
虚拟机版本:Centos6.5
一、前置环境准备
1.1 jdk安装
1.2 免密钥登录
二、 hadoop3.0需要配置的文件有core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、hadoop-env.sh、workers
1.core-site.xml配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop3:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>file:///hadoopv3/tmp</value> //此目录不配置的话,默认是在/temp目录下。Linux系统重启的话此目录会被清空
</property>
</configuration>
2.hdfs-site.xml配置文件
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///hadoopv3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///hadoopv3/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:</value>
</property>
</configuration>
3.workers中设置slave节点,将slave机器的名称写入
hadoop1
hadoop2
hadoop3
4.mapred-site配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.application.classpath</name>
<value>
/home/software/hadoop-3.0.-beta1/etc/hadoop,
/home/software/hadoop-3.0.-beta1/share/hadoop/common/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/common/lib/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/hdfs/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/hdfs/lib/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/mapreduce/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/mapreduce/lib/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/yarn/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
5.yarn-site.xml配置
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>
</configuration>
6.hadoop-env.sh中配置java_home
export JAVA_HOME=/usr/local/java/jdk1..0_121
以上配置完成后,将hadoop整个文件夹复制到其他二台机器。
四、启动hadoop
hdfs namenode -format
注意:格式化的时候只需要在namenode节点执行一次即可
若没有设置路径$HADOOP_HOME/bin为环境变量,则需在$HADOOP_HOME路径下执行
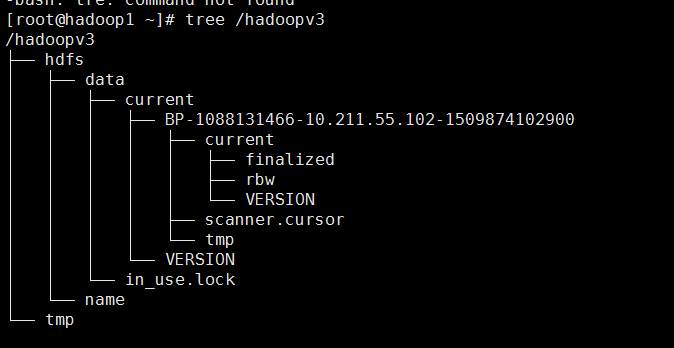
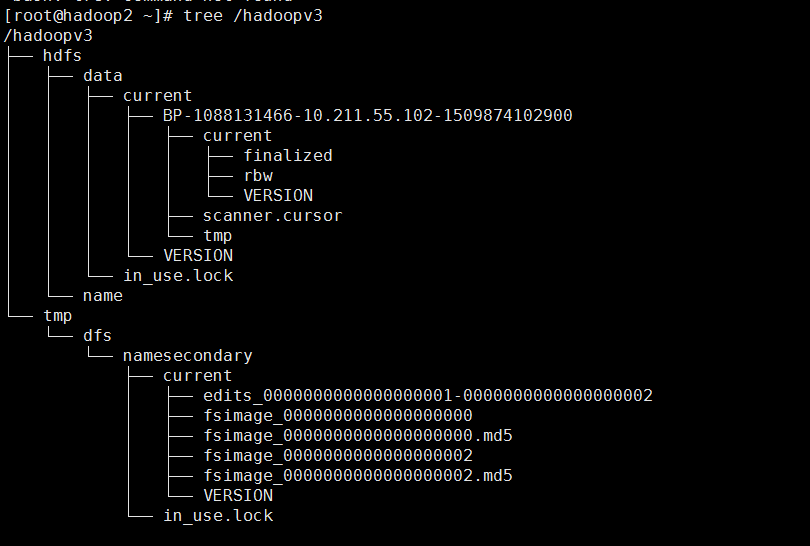
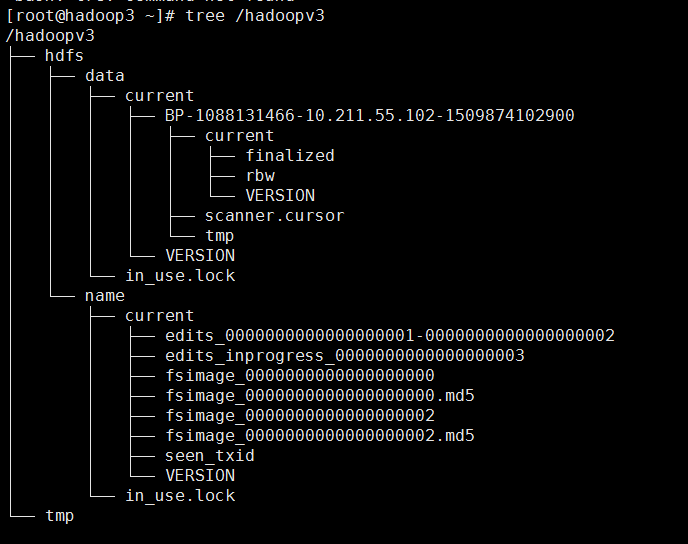
格式化之后三台机器上的目录的结构分别是:
hadoop1:
hadoop2:
hadoop3:
2.启动hdfs及yarn
start-dfs.sh
start-yarn.sh
若没有设置路径$HADOOP_HOME/sbin为环境变量,则需在$HADOOP_HOME路径下执行
现在便可以打开页面http://hadoop3:8088及http://hadoop3:9870;看到下面两个页面时说明安装成功。
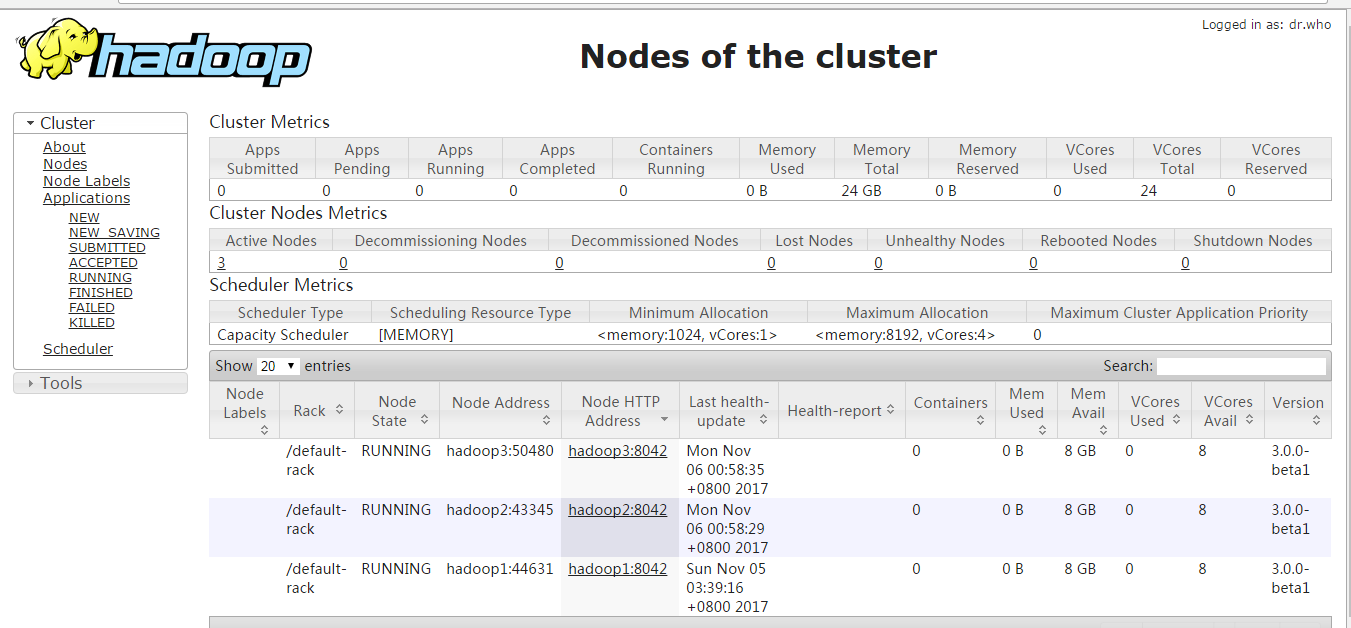

注意:启动的时候会遇到一些问题
问题1:Starting namenodes on [hadoop3]
ERROR: Attempting to launch hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.

解决1:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vi sbin/start-dfs.sh
$ vi sbin/stop-dfs.sh
在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
问题2:
Starting resourcemanager
ERROR: Attempting to launch yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
Starting nodemanagers
ERROR: Attempting to launch yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting launch.
解决2:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vi sbin/start-yarn.sh
$ vi sbin/stop-yarn.sh

hadoop-3.0.0-beta1分布式安装的更多相关文章
- CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装
摘要 CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装 目录[-] 1.系统环境说明 2.安装前的准备工作 2.1 关闭防火墙 2.2 检查ssh安装情况,如果没有则安装ssh ...
- Hadoop2.2.0多节点分布式安装及测试
众所周知,hadoop在10月底release了最新版2.2.很多国内的技术同仁都马上在网络上推出了自己对新版hadoop的配置心得.这其中主要分为两类: 1.单节点配置 这个太简单了,简单到只要懂点 ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- centos 7下Hadoop 2.7.2 伪分布式安装
centos 7 下Hadoop 2.7.2 伪分布式安装,安装jdk,免密匙登录,配置mapreduce,配置YARN.详细步骤如下: 1.0 安装JDK 1.1 查看是否安装了openjdk [l ...
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- Linux下Storm2.1.0的伪分布式安装
官方下载网址:http://storm.apache.org/downloads.html 1.第一步我们先从官网下载解压包 2.然后进行解压 3.配置环境变量 在profile里面插入如下格式语句 ...
- Hadoop + Hive + HBase + Kylin伪分布式安装
问题导读 1. Centos7如何安装配置? 2. linux网络配置如何进行? 3. linux环境下java 如何安装? 4. linux环境下SSH免密码登录如何配置? 5. linux环境下H ...
- Hadoop1.0.4伪分布式安装
前言: 目前,学习hadoop的目的是想配合其它两个开源软件Hbase(一种NoSQL数据库)和Nutch(开源版的搜索引擎)来搭建一个知识问答系统,Nutch从指定网站爬取数据存储在Hbase数据库 ...
- arcsde10.0 for oracle11g 分布式安装教程
[操作系统] oracle :windows server 2008ArcSDE:win7[数据库版本] Oracle 11g [ArcSDE版本] ArcSDE 10.0 1.在要安装ArcSD ...
- Hadoop开发第4期---分布式安装
一.复制虚拟机 由于Hadoop的集群安装需要多台机器,由于条件有限,我是用虚拟机通过克隆来模拟多台机器,克隆方式如下图所示
随机推荐
- RegisterStartupScript 后退重复提示解决方法
我在后台调用RegisterStartupScript注册脚本,提示用户是否要跳转到另外一个页面,可是问题就来了,跳转到另外一个页面后,一旦用户后退,原来的页面就会又提示脚本信息, 后来自己想了想,用 ...
- 使用Navicat连接阿里云服务器上的MySQL数据库=======Linux 开放 /etc/hosts.allow
使用Navicat连接阿里云服务器上的MySQL数据库 1.首先打开Navicat,文件>新建连接> 2,两张连接方法 1>常规中输入数据库的主机名,端口,用户名,密码 这种直接 ...
- CI $_GET
CI默认过滤了$_GET 需要传递get参数时一般直接 /参数一/参数二 详见手册说明:http://codeigniter.org.cn/user_guide/general/controllers ...
- 关于Cocos2d-x中两个场景之间参数的传递
两个场景之间,有的时候要进行参数传递,如果想通过实例化出一个场景,从而得到属性和方法是不对的想法 你有两个场景,第一场景是用户登录界面,第二场景则是你登录后的界面,你如何将用户登录的值传到第二个场景呢 ...
- cookie,Session机制的本质,跨应用程序的session共享
目录:一.术语session二.HTTP协议与状态保持三.理解cookie机制四.理解session机制五.理解javax.servlet.http.HttpSession六.HttpSession常 ...
- 要立刷金组flag了T_T
刷了那么多银组,发现自己好多不会啊... 果然太弱 在这感谢hzwer神犇的blog.. 大部分题解都从黄学长这里来orz. orz.... 果然我太水
- 开源 java CMS - FreeCMS2.3 移动app生成栏目数据
原文地址:http://javaz.cn/site/javaz/site_study/info/2015/28230.html 项目地址:http://www.freeteam.cn/ 生成栏目数据 ...
- 用Python获取Linux资源信息的三种方法
方法一:psutil模块 #!usr/bin/env python # -*- coding: utf-8 -*- import socket import psutil class NodeReso ...
- 复习及总结--.Net线程篇(2)
复习总结 上一篇里讲到了使用委托异步调用的方式来使用多线程,这里介绍几个概念 这里贴出来一个关于应用程序域的帖子 http://www.cnblogs.com/firstyi/archive/2008 ...
- 1-2、superset国际化
最近由于工作需要研究开源可视化项目superset,由于其国际化做不怎么好,故而记录下国际化的过程,本篇本着『授人以鱼不如授人以渔』的原则,只叙述国际化的过程及方法,不提供直接的国际化文件. 为了方便 ...