什么是spark(二) RDD
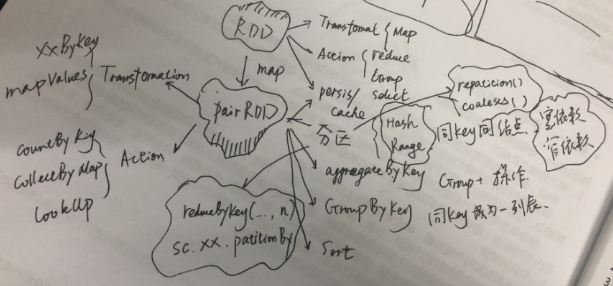
其实你会发现很多概念都是基于RDD提出来的,比如分区,缓存这些操作的对象其实都是RDD;所以不要讲spark的分区,这其实很不专业,分区其实是属于RDD的概念(只有pair RDD才有分区概念)
RDD在(一)已经介绍了RDD,本质上是数据的描述(检索条件)以及处理描述(算法);等待着Action调用之后将会根据数据描述来获取数据,然后再根据算法来处理获取到的数据。简单讲,RDD包含了两部分:一部分是本身定义了数据的描述:比如设置数据源inputRDD = sc.textFile("log.txt")另外一部分RDD提供了对于数据的操作接口:比如filter,union等。
那么在处理数据上面有两类操作,一类是Transformation(map, flatMap);上段提到的数据的描述就是在Transformation中定义,处理描述其实也是在其实在T中描述;当且建档Action类函数被调用了才会触发,比如reduce(),才会执行数据获取和数据处理;所以,spark里面的数据处理其实是一个延迟处理(Lazy Evaluation);一类是Action(reduce,first,take,folder,foreach等);所有的Transformation操作返回的都是RDD,所有的Action返回的是单值或者集合对象;这个是T和A的本质区别,因为T是用于形成DAG,定义了要如何对数据进行准备(transform就是变形的意思,可以理解为对数据的处理),A则是为了获取可操作数据,定了我要什么样的数据。
还有第三类操作,就是persis/cache;用于避免请求相同数据频繁的获取,可以将某次获取的数据RDD进行缓存。cache尽是内存级别缓存,persis则是提供了多种缓存策略。
RDD的最强大的地方其实还是在于PairRDD,一旦RDD是pairRDD,你的数据的想象空间就大了;首先是要把RDD转换为PairRDD,原生的RDD都是单值的;需要通过map来转为PairRDD,将原生单值数据,提取一部分作为key,单值本身或者单值另外一部分作为value(Map是为了改变世界而生,Map函数将会改变RDD的结构和数据);
PairRDD同样有Action和Transformation;但是Transformation的函数明显增多,一大堆在RDD时代是Action的函数,到了PairRDD时代,增加了“ByKey”,之后变成了Transformation,比如reduceByKey,groupByKey等等。PairRDD的action只剩下了:
1. countByKey;
2. collectAsMap;
3. lookup(key);
到了PairRDD最主要的动作之一就是分区;是的分区只能是PairRDD,因为只有PairRDD才有key的概念,分区的依据就是key(无论是Hash还是Range)。注意数据被某些改变key的操作处理后,返回的RDD可能会丢失分区,比如map;但是XXByKey家族的函数都会维持原始PairRDD的分区,因为这些操作并不改变分区。
分区的概念的本质是将数据按照一定规则进行汇聚,汇聚到一个计算节点(一台主机);一个计算节点可以有多个分区;
与分区设置方式,
1.)在调用Transformation函数的在最后一个参数添加为分区数;这个分区默认的应该是大多数都是Hash(Folder是defaultPartition);会造成数据倾斜(数据分布度不够,导致大量数据集中)。parallelize的默认将会根据集群情况来指定分区个数;但是当你想要避免shuffle操作的时候,分区还是需要你来做。
2)在创建的RDD的时候添加
有了Key之后,就可以做以下事情:
1)按照key来进行聚集(aggregation)操作;按照key进行分组,然后对于同组数据进行运算;返回的是[key, handled value];
2)按照key来进行分组(groupping)操作;按照key进行分组,返回[key,items];如果是分组+运算处理,请采用聚集操作
3)按照key来尽心排序(sorting)操作。
什么是spark(二) RDD的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- 解读Spark Streaming RDD的全生命周期
本节主要内容: 一.DStream与RDD关系的彻底的研究 二.StreamingRDD的生成彻底研究 Spark Streaming RDD思考三个关键的问题: RDD本身是基本对象,根据一定时间定 ...
- 08、Spark常用RDD变换
08.Spark常用RDD变换 8.1 概述 Spark RDD内部提供了很多变换操作,可以使用对数据的各种处理.同时,针对KV类型的操作,对应的方法封装在PairRDDFunctions trait ...
- Spark之RDD
Spark学习之路Spark之RDD 目录 一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数 ...
- Spark之RDD容错原理及四大核心要点
一.Spark RDD容错原理 RDD不同的依赖关系导致Spark对不同的依赖关系有不同的处理方式. 对于宽依赖而言,由于宽依赖实质是指父RDD的一个分区会对应一个子RDD的多个分区,在此情况下出现部 ...
- Spark RDD :Spark API--Spark RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
随机推荐
- SpringBoot下的值注入
在我们实际开发项目中,经常会遇到一些常量的配置,比如url,暂时不会改变的字段参数,这个时候我们最好是不要直接写死在代码里的,因为这样编写的程序,应用扩展性太差了,我们可以直接写在配置文件中然后通过配 ...
- 原生javascript-分享自己常用的函数
[一]添加监听事件 addHandler:function(node,type,fn){if(node.addEventListener){ node.addEventListener(type,fn ...
- IOS加载PDF文件
今天的任务是:在iOS上加载显示pdf文件. 方法一:利用webview -(void)loadDocument:(NSString *)documentName inView:(UIWebView ...
- 适配器模式(Adapter Pattern)/包装器
将一个类的接口转换成客户希望的另外一个接口.Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作. 模式中的角色 目标接口(Target):客户所期待的接口.目标可以是具体的或 ...
- AndroidStudio构建常见错误解答解决思路
一.Error:Configuration with name 'default' not found.解决思路 出现这问题的原因是你依赖的工程没有make project,意思是你导入项目的工程没有 ...
- SpringInAction--Bean的作用域
Spring定义了多种作用域,我们在使用的时候可以根据使用的需求来选择对应的作用域,这些作用域,包括(第二个括号中为更安全的注解方法,具体更多参数可查看接口代码) 单例(Singleton)(Conf ...
- 有关php的session
From:http://blog.csdn.net/sayigood/article/details/4850480 php中session的用法 PHP中的session默认情况下是使用客户端的Co ...
- PHPStorm 添加支持 PSR-4 命名空间前缀设置
许久没有更新博客啦, 太忙了, 七月这最后一天来写点自己在使用 PHPStorm 上的小却很有用的功能吧. PHPStorm 默认是使用 PSR-0 命名空间规范的, 前提是你需要标记好项目中的源码根 ...
- SoftmaxWithLoss函数和师兄给的loss有哪些区别呢
师兄的: NG教程中提到的:
- moment时间转换插件
在vue中的使用: import moment = from “moment” Vue.prototype.$moment = moment; 获取时间戳 : var res = this.$mome ...