【集成学习】lightgbm调参案例
lightgbm使用leaf_wise tree生长策略,leaf_wise_tree的优点是收敛速度快,缺点是容易过拟合。
# lightgbm关键参数
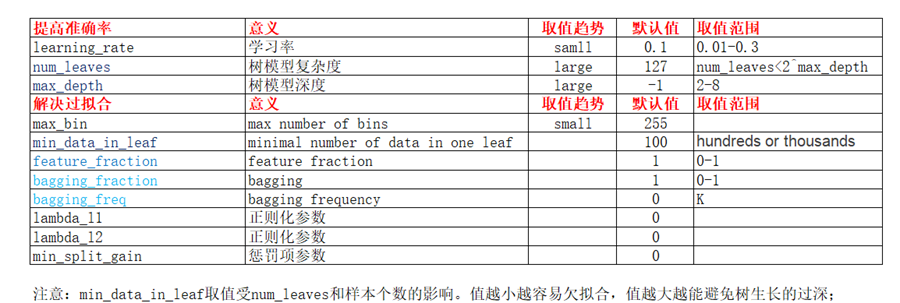
# lightgbm调参方法cv
1 # -*- coding: utf-8 -*-
2 """
3 # 作者:wanglei5205
4 # 邮箱:wanglei5205@126.com
5 # 博客:http://cnblogs.com/wanglei5205
6 # github:http://github.com/wanglei5205
7 """
8 ### 导入模块
9 import numpy as np
10 import pandas as pd
11 import lightgbm as lgb
12 from sklearn import metrics
13
14 ### 载入数据
15 print('载入数据')
16 dataset1 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data1.csv')
17 dataset2 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data2.csv')
18 dataset3 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data3.csv')
19 dataset4 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data4.csv')
20 dataset5 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data5.csv')
21
22 print('数据去重')
23 dataset1.drop_duplicates(inplace=True)
24 dataset2.drop_duplicates(inplace=True)
25 dataset3.drop_duplicates(inplace=True)
26 dataset4.drop_duplicates(inplace=True)
27 dataset5.drop_duplicates(inplace=True)
28
29 print('数据合并')
30 trains = pd.concat([dataset1,dataset2],axis=0)
31 trains = pd.concat([trains,dataset3],axis=0)
32 trains = pd.concat([trains,dataset4],axis=0)
33
34 online_test = dataset5
35
36 ### 数据拆分(训练集+验证集+测试集)
37 print('数据拆分')
38 from sklearn.model_selection import train_test_split
39 train_xy,offline_test = train_test_split(trains,test_size = 0.2,random_state=21)
40 train,val = train_test_split(train_xy,test_size = 0.2,random_state=21)
41
42 # 训练集
43 y_train = train.is_trade # 训练集标签
44 X_train = train.drop(['instance_id','is_trade'],axis=1) # 训练集特征矩阵
45
46 # 验证集
47 y_val = val.is_trade # 验证集标签
48 X_val = val.drop(['instance_id','is_trade'],axis=1) # 验证集特征矩阵
49
50 # 测试集
51 offline_test_X = offline_test.drop(['instance_id','is_trade'],axis=1) # 线下测试特征矩阵
52 online_test_X = online_test.drop(['instance_id'],axis=1) # 线上测试特征矩阵
53
54 ### 数据转换
55 print('数据转换')
56 lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
57 lgb_eval = lgb.Dataset(X_val, y_val, reference=lgb_train,free_raw_data=False)
58
59 ### 设置初始参数--不含交叉验证参数
60 print('设置参数')
61 params = {
62 'boosting_type': 'gbdt',
63 'objective': 'binary',
64 'metric': 'binary_logloss',
65 }
66
67 ### 交叉验证(调参)
68 print('交叉验证')
69 min_merror = float('Inf')
70 best_params = {}
71
72 # 准确率
73 print("调参1:提高准确率")
74 for num_leaves in range(20,200,5):
75 for max_depth in range(3,8,1):
76 params['num_leaves'] = num_leaves
77 params['max_depth'] = max_depth
78
79 cv_results = lgb.cv(
80 params,
81 lgb_train,
82 seed=2018,
83 nfold=3,
84 metrics=['binary_error'],
85 early_stopping_rounds=10,
86 verbose_eval=True
87 )
88
89 mean_merror = pd.Series(cv_results['binary_error-mean']).min()
90 boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
91
92 if mean_merror < min_merror:
93 min_merror = mean_merror
94 best_params['num_leaves'] = num_leaves
95 best_params['max_depth'] = max_depth
96
97 params['num_leaves'] = best_params['num_leaves']
98 params['max_depth'] = best_params['max_depth']
99
100 # 过拟合
101 print("调参2:降低过拟合")
102 for max_bin in range(1,255,5):
103 for min_data_in_leaf in range(10,200,5):
104 params['max_bin'] = max_bin
105 params['min_data_in_leaf'] = min_data_in_leaf
106
107 cv_results = lgb.cv(
108 params,
109 lgb_train,
110 seed=42,
111 nfold=3,
112 metrics=['binary_error'],
113 early_stopping_rounds=3,
114 verbose_eval=True
115 )
116
117 mean_merror = pd.Series(cv_results['binary_error-mean']).min()
118 boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
119
120 if mean_merror < min_merror:
121 min_merror = mean_merror
122 best_params['max_bin']= max_bin
123 best_params['min_data_in_leaf'] = min_data_in_leaf
124
125 params['min_data_in_leaf'] = best_params['min_data_in_leaf']
126 params['max_bin'] = best_params['max_bin']
127
128 print("调参3:降低过拟合")
129 for feature_fraction in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
130 for bagging_fraction in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
131 for bagging_freq in range(0,50,5):
132 params['feature_fraction'] = feature_fraction
133 params['bagging_fraction'] = bagging_fraction
134 params['bagging_freq'] = bagging_freq
135
136 cv_results = lgb.cv(
137 params,
138 lgb_train,
139 seed=42,
140 nfold=3,
141 metrics=['binary_error'],
142 early_stopping_rounds=3,
143 verbose_eval=True
144 )
145
146 mean_merror = pd.Series(cv_results['binary_error-mean']).min()
147 boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
148
149 if mean_merror < min_merror:
150 min_merror = mean_merror
151 best_params['feature_fraction'] = feature_fraction
152 best_params['bagging_fraction'] = bagging_fraction
153 best_params['bagging_freq'] = bagging_freq
154
155 params['feature_fraction'] = best_params['feature_fraction']
156 params['bagging_fraction'] = best_params['bagging_fraction']
157 params['bagging_freq'] = best_params['bagging_freq']
158
159 print("调参4:降低过拟合")
160 for lambda_l1 in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
161 for lambda_l2 in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
162 for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
163 params['lambda_l1'] = lambda_l1
164 params['lambda_l2'] = lambda_l2
165 params['min_split_gain'] = min_split_gain
166
167 cv_results = lgb.cv(
168 params,
169 lgb_train,
170 seed=42,
171 nfold=3,
172 metrics=['binary_error'],
173 early_stopping_rounds=3,
174 verbose_eval=True
175 )
176
177 mean_merror = pd.Series(cv_results['binary_error-mean']).min()
178 boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
179
180 if mean_merror < min_merror:
181 min_merror = mean_merror
182 best_params['lambda_l1'] = lambda_l1
183 best_params['lambda_l2'] = lambda_l2
184 best_params['min_split_gain'] = min_split_gain
185
186 params['lambda_l1'] = best_params['lambda_l1']
187 params['lambda_l2'] = best_params['lambda_l2']
188 params['min_split_gain'] = best_params['min_split_gain']
189
190
191 print(best_params)
192
193 ### 训练
194 params['learning_rate']=0.01
195 lgb.train(
196 params, # 参数字典
197 lgb_train, # 训练集
198 valid_sets=lgb_eval, # 验证集
199 num_boost_round=2000, # 迭代次数
200 early_stopping_rounds=50 # 早停次数
201 )
202
203 ### 线下预测
204 print ("线下预测")
205 preds_offline = lgb.predict(offline_test_X, num_iteration=lgb.best_iteration) # 输出概率
206 offline=offline_test[['instance_id','is_trade']]
207 offline['preds']=preds_offline
208 offline.is_trade = offline['is_trade'].astype(np.float64)
209 print('log_loss', metrics.log_loss(offline.is_trade, offline.preds))
210
211 ### 线上预测
212 print("线上预测")
213 preds_online = lgb.predict(online_test_X, num_iteration=lgb.best_iteration) # 输出概率
214 online=online_test[['instance_id']]
215 online['preds']=preds_online
216 online.rename(columns={'preds':'predicted_score'},inplace=True) # 更改列名
217 online.to_csv("./data/20180405.txt",index=None,sep=' ') # 保存结果
218
219 ### 保存模型
220 from sklearn.externals import joblib
221 joblib.dump(lgb,'lgb.pkl')
222
223 ### 特征选择
224 df = pd.DataFrame(X_train.columns.tolist(), columns=['feature'])
225 df['importance']=list(lgb.feature_importance()) # 特征分数
226 df = df.sort_values(by='importance',ascending=False) # 特征排序
227 df.to_csv("./data/feature_score_20180331.csv",index=None,encoding='gbk') # 保存分数
【集成学习】lightgbm调参案例的更多相关文章
- xgboost&lightgbm调参指南
本文重点阐述了xgboost和lightgbm的主要参数和调参技巧,其理论部分可见集成学习,以下内容主要来自xgboost和LightGBM的官方文档. xgboost Xgboost参数主要分为三大 ...
- LightGBM 调参方法(具体操作)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- LightGBM调参笔记
本文链接:https://blog.csdn.net/u012735708/article/details/837497031. 概述在竞赛题中,我们知道XGBoost算法非常热门,是很多的比赛的大杀 ...
- 自动调参库hyperopt+lightgbm 调参demo
在此之前,调参要么网格调参,要么随机调参,要么肉眼调参.虽然调参到一定程度,进步有限,但仍然很耗精力. 自动调参库hyperopt可用tpe算法自动调参,实测强于随机调参. hyperopt 需要自己 ...
- lightgbm调参方法
gridsearchcv: https://www.cnblogs.com/bjwu/p/9307344.html gridsearchcv+lightgbm cv函数调参: https://www. ...
- LightGBM调参总结
1. 参数速查 使用num_leaves,因为LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth. 大致换算关系:num_ ...
- XGBoost和LightGBM的参数以及调参
一.XGBoost参数解释 XGBoost的参数一共分为三类: 通用参数:宏观函数控制. Booster参数:控制每一步的booster(tree/regression).booster参数一般可以调 ...
- 使用sklearn进行集成学习——实践
系列 <使用sklearn进行集成学习——理论> <使用sklearn进行集成学习——实践> 目录 1 Random Forest和Gradient Tree Boosting ...
- [转]使用sklearn进行集成学习——实践
转:http://www.cnblogs.com/jasonfreak/p/5720137.html 目录 1 Random Forest和Gradient Tree Boosting参数详解2 如何 ...
随机推荐
- JSON and XML Serialization in ASP.NET Web API
https://docs.microsoft.com/en-us/aspnet/web-api/overview/formats-and-model-binding/json-and-xml-seri ...
- 关于Spring Test 小结
1.>public class CustomerPackagePrealertControllerTest extends WebSpringBaseTest{} 2.> @WebApp ...
- Deep Learning入门
今天在看电影的过程中我忽然想起来几件特别郁闷的事,我居然忘了上周三晚上的计算机接口的实验课!然后我又想起来我又忘了上周六晚上的就业指导!然后一阵恐惧与责备瞬间涌了上来.这事要是在以前我绝对会释然的,可 ...
- sublime的一些插件
新安装的sublime缺少一些插件… 1.文件路径没有提示 ctrl+shift+p → install → autofilename 2..html后缀的文件中,使用快捷键!不能自动出现内容 ctr ...
- DataTemplate——数据模板的一个典型例子
下面是ListBox.ItemTemplate(数据模板)应用的“典型”例子,概述如下两点: 1:Grid部分,用来“规划” 数据 显示的 布局(即数据长成什么样子) 2:给DataTempl ...
- are only available on JDK 1.5 and higher
根本原因是项目中的一些配置包括jar包什么的根当前jdk版本(我刚开始用的是1.8的,好像是不支持低版本的springjar包),反正正确的思路是更改jdk版本是最合理的,叫我去把所有spring版本 ...
- 2.SpringMVC源码分析:DispatcherServlet的初始化与请求转发
一.DispatcherServlet的初始化 在我们第一次学Servlet编程,学java web的时候,还没有那么多框架.我们开发一个简单的功能要做的事情很简单,就是继承HttpServlet,根 ...
- Linux系统 SSHD服务安全优化方案
# 1. 修改默认端口 #Port 22 # 2. 修改监听协议,只监听某个或某些网络协议 #AddressFamily any AddressFamily inet # 3. 修改ssh只监听内 ...
- zen cart 空白页面的解决方案
在安装zen cart 这套CMS时, 有时候会由于修改了某些页面或者是由于环境的某些组件的版本问题导致前台页面出现空白页, 由于在空白页面处没有任何提示, 并且在日志中也没有这样的出错提示, 导致在 ...
- C++复习4.函数设计基础
C/C++ 函数设计基础 20130918 函数式程序的基本功能单元,是模块化程序设计的基础,即使函数的功能正确是不够的,因为函数设计的细微缺点很容易导致函数被错用. 了解函数的基本知识,堆栈和堆的相 ...