ctf-HITCON-2016-houseoforange学习
目录
堆溢出点
利用步骤
创建第一个house,修改top_chunk的size
创建第二个house,触发sysmalloc中的_int_free
创建第三个house,泄露libc和heap的地址
创建第四个house,触发异常
一点疑惑
参考资料
堆溢出点

图1 堆溢出点
edit函数中没有对那么长度进行校验。
利用步骤
创建第一个house,修改top_chunk的size
top_chunk的size也不是随意更改的,因为在sysmalloc中对这个值还要做校验
assert ((old_top == initial_top (av) && old_size == ) ||
((unsigned long) (old_size) >= MINSIZE &&
prev_inuse (old_top) &&
((unsigned long) old_end & (pagesize - )) == )); /* Precondition: not enough current space to satisfy nb request */
assert ((unsigned long) (old_size) < (unsigned long) (nb + MINSIZE));
所以要满足:
- 大于MINSIZE(0X10)
- 小于所需的大小 + MINSIZE
- prev inuse位设置为1
- old_top + oldsize的值是页对齐的
创建第二个house,触发sysmalloc中的_int_free
如果要触发sysmalloc中_int_free,那么本次申请的堆大小也不能超过mp_.mmap_threshold,因为代码中也会根据请求值来做出不同的处理。
if (av == NULL
|| ((unsigned long) (nb) >= (unsigned long) (mp_.mmap_threshold)
&& (mp_.n_mmaps < mp_.n_mmaps_max)))
如果请求的堆块大小nb大于等于mp_.mmap_threshold就可能走mmap分支,而不是扩展原来heap的大小了。
触发_int_free后,top_chunk就被释放到unsortbin中了。以下将它称作old_top。之所以要这样操作,是因为程序本身的限制,让我们不能分配到想要的内存区。
本身的限制:
- 一次操作的对象只能是最近一次创建的house指针
- 没有释放操作
通过这种方式,在空闲区有了堆块,也就存在了链表指针,通过一定的方式就拿到想要的数据了。
创建第三个house,泄露libc和heap的地址
本次创建house分配的堆块从unsortbin中分配,指定的大小要小于old_top,系统会将old_top切分成两块。
在把old_top从unsortbin链中取下后,会将其插入相应的largebin中
/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;//将old_top从unsortbin中取下
bck->fd = unsorted_chunks (av);
…
victim_index = largebin_index (size);//计算old_top大小在largebin那个层次
bck = bin_at (av, victim_index);
fwd = bck->fd;
…
victim->fd_nextsize = victim->bk_nextsize = victim;//将old_top的fd_nextsize和bk_nextsize都指向old_top本身
…
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;//将old_top加入largebin链表中
bck->fd = victim;
在后面分割堆块后,保存有指针信息的堆块会被分配给用户,而且这些信息malloc不会擦除。
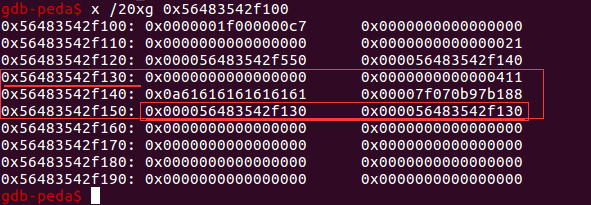
图2 old_top加入largebin链表中
剩下的堆块(下文依然称之为为old_top)又被加入到unsortbin中了。
然后输入8个字节,调用see函数,那么bk处保存的指针信息就得到了。这个就是unsortbin的地址,这个地址处于libc中,减掉一个偏移就是libc的起始地址了。
重新输入24个字节,调用see函数,那么bk_nextsize处保存的指针信息就得到了。这个是本次分割前的old_top块起始地址。减掉一个偏移就是heap的起始地址了。
为第四步触发异常布局内存。
本题的利用思路,是通过修改IO_list_all指针来控制异常处理的流程到我们指定的函数。如何触发异常,第四步会说。
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
bck = victim->bk;
…
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
IO_list_all的地址需要拿到libc.so后才能确定。通过覆盖此时的old_top的size域和bk指针,来重写IO_list_all。
将bk指针覆盖为&IO_list_all -0x10,因此IO_list_all被重写为unsortbin-0x10。
将size域设置为0x60。为什么是0x60而不是70、80呢?
先来看看,设置为0x60后会给后续的malloc造成什么影响。
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
…
if (in_smallbin_range (size))
{
victim_index = smallbin_index (size);// victim_index=6
bck = bin_at (av, victim_index);//bck=&av->bins[10]-0x10
fwd = bck->fd;
}
…
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;//old_top被加入av->bins[10]的链表中了。
bck->fd = victim;
0x60属于smallbin的范围了,所以此时的old_top被加入到smallbin[4]的链表中。又为何要加入到smallbin[4]中呢?此时IO_list_all=&unsortbin-0x10,距离smallbin[4]的偏移是0x60,再来看看IO_FILE的结构体
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
…
可以看到,IO_FILE偏移0x60的字段是struct _IO_marker *_markers,偏移0x68的字段是struct _IO_FILE *_chain。而这两个的值恰恰是old_top的起始地址。
原来改为0x60是为了将old_top加入smallbin[4],而smallbin[4]的fd和bk指针恰好对应于IO_FILE结构体中的_markers和_chain字段。这个时候,算是明白参考文章所说,无法控制main_arena中的数据,但是通过chain链,将控制转移到我们到我们能控制的地方。

图3 IO_list_all被重写后
那如何使用chain字段呢?
while (fp != NULL)
{
…
fp = fp->_chain;
当fp指向old_top的时候,那一切都好说了。为了使用vtable,我们还要过一段校验代码。
if (((fp->_mode <= && fp->_IO_write_ptr > fp->_IO_write_base)
#if defined _LIBC || defined _GLIBCPP_USE_WCHAR_T
|| (_IO_vtable_offset (fp) ==
&& fp->_mode > && (fp->_wide_data->_IO_write_ptr
> fp->_wide_data->_IO_write_base))
#endif
)
&& _IO_OVERFLOW (fp, EOF) == EOF)
- fp->_mode <= 0不成立,所以
- _IO_vtable_offset (fp) == 0、fp->_mode > 0和fp->_wide_data->_IO_write_ptr> fp->_wide_data->_IO_write_base必须成立
- 我们将vtable的值改写成我们构造的vtable起始地址
- 将_wide_data字段改写成IO_FILE中字段_IO_read_ptr的地址 //此处错误,在参考的利用脚本中并不是改成_IO_read_ptr的地址。而是vtable前0x28个字节,这些字节恰好能满足fp->_wide_data->_IO_write_ptr> fp->_wide_data->_IO_write_base。当然,也可以改成IO_FILE中字段_IO_read_ptr的地址,但是在payload中需要额外构造一些数据来满足条件了
而传递给over函数的参数是fp,fp指向old_top,起始处被写为”/bin/sh\0x00”
创建第四个house,触发异常
如上面第三步所述,old_top的size被改写为0x60,本次分配的时候,会先从unsortbin中取下old_top,加入到smallbin[4],同时,unsortbin.bk也被改写成了&IO_list_all-0x10,所以此时的victim->size=0那么不会通过校验,进入malloc_printerr,触发异常。
一点疑惑
关于前面调用_int_free将old_top释放到unsortbin我是一笔带过。但是这个地方有一点问题。
old_size = (old_size - * SIZE_SZ) & ~MALLOC_ALIGN_MASK;
set_head (old_top, old_size | PREV_INUSE);
chunk_at_offset (old_top, old_size)->size = ( * SIZE_SZ) | PREV_INUSE;
chunk_at_offset (old_top, old_size + * SIZE_SZ)->size = ( * SIZE_SZ) | PREV_INUSE;
if (old_size >= MINSIZE){
_int_free (av, old_top, );
old_top被释放之前,用最后的0x20个字节构造了两个chunk的header信息。size都设置为2 * SIZE_SZ。但是就是这里有问题。
nextchunk = chunk_at_offset(p, size);
nextsize = chunksize(nextchunk);
if (__builtin_expect (nextchunk->size <= * SIZE_SZ, )
|| __builtin_expect (nextsize >= av->system_mem, ))
{
errstr = "free(): invalid next size (normal)";
goto errout;
这个校验会不通过。但是事实却是通过了。很困惑。不知道自己哪点理解出现了偏差。
近来才想起来还有这个问题没处理,其实代码已经告诉我答案了。
chunk_at_offset (old_top, old_size)->size = (2 * SIZE_SZ) | PREV_INUSE;
此时size设置了prev_inuse位,自然在后面的校验中大于2 * SIZE_SZ
__builtin_expect (nextchunk->size <= 2 * SIZE_SZ
参考资料
[1] CTF Pwn之创造奇迹的Top Chunk
http://bobao.360.cn/ctf/detail/178.html
[2] HITCON CTF Qual 2016 - House of Orange Write up
http://4ngelboy.blogspot.jp/2016/10/hitcon-ctf-qual-2016-house-of-orange.html
[3] glibc-2.23源码
ctf-HITCON-2016-houseoforange学习的更多相关文章
- 参加 Tokyo Westerns / MMA CTF 2nd 2016 经验与感悟 TWCTF 2016 WriteUp
洒家近期参加了 Tokyo Westerns / MMA CTF 2nd 2016(TWCTF) 比赛,不得不说国际赛的玩法比国内赛更有玩头,有的题给洒家一种一看就知道怎么做,但是做出来还需要洒家拍一 ...
- [原题复现]-HITCON 2016 WEB《babytrick》[反序列化]
前言 不想复现的可以访问榆林学院信息安全协会CTF训练平台找到此题直接练手 HITCON 2016 WEB -babytrick(复现) 原题 index.php 1 <?php 2 3 inc ...
- Hitcon 2016 Pwn赛题学习
PS:这是我很久以前写的,大概是去年刚结束Hitcon2016时写的.写完之后就丢在硬盘里没管了,最近翻出来才想起来写过这个,索性发出来 0x0 前言 Hitcon个人感觉是高质量的比赛,相比国内的C ...
- 【CTF】后续深入学习内容
1.i春秋 https://www.ichunqiu.com/course/451 搜索black hat,可以看到黑帽大会的内容.免费. 2.wireshark 基础篇 1)由于Wireshark是 ...
- 2016年学习JavaScript是怎样的一种体验(转)
转自:http://www.zcfy.cc/article/how-it-feels-to-learn-javascript-in-2016-hacker-noon-1871.html 在这篇文章的写 ...
- sql server 2016 JSON 学习笔记
虽然现在win服务器已经几乎不用了,但是网上看到2016开始原生支持json 还是想试试 建立一个表 id int , json varchar(2000) json字段中输入数据 {"r ...
- 想学习CTF的一定要看这篇,让你学习效率提升80%
在学习CTF过程中你是否遇到这样的情况: 下定决心想要学习CTF,不知道从哪里开始? 找了一堆CTF相关的知识学习,但是知识点太凌乱,没有统一明确的学习路径. 又或者理论学习完,没有相应的实操环境? ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
随机推荐
- quick-cocos2dx-2.2.4环境搭建
1.Quick-Coco2d-x介绍 Quick-Coco2d-x是Cocos2d-x在Lua上的增强和扩展版本,廖宇雷廖大觉得官方Cocos2d-x的Lua版本不是太好用,于是便在官方Lua版本的基 ...
- tornado WebSocket详解
1.什么是WebSocketwebsocket和长轮询的区别是客户端和服务器之间是持久连接的双向通信.协议使用ws://URL格式,但它在是在标准HTTP上实现的. 2.tornado的WebSock ...
- java 高精度 四则运算
java的大数处理对于ACM中的大数来说,相当的简单啊: 整数的运算 BigInteger 小数的运算 BigDecimal 导入类: import java.util.Scanner; im ...
- 虚拟机下安装centos7方法,修改系统语言为简体中文的方法
说明 自己装系统时一般都可以自定义选择系统语言.可是云端服务器一般都是安装好的镜像,默认系统语言为英文,对于初学者可能还会有搞不懂的计算机词汇.这里简单说一下centos7怎么修改系统语言为中文. 虚 ...
- C++虚函数解析(转载)
虚函数详解第一篇:对象内存模型浅析 C++中的虚函数的内部实现机制到底是怎样的呢? 鉴于涉及到的内容有点多,我将分三篇文章来介绍. 第一篇:对象内存模型浅析,这里我将对对象的内存模型进 ...
- Makefile 8——使用依赖关系文件
Makefile中存在一个include指令,它的作用如同C语言中的#include预处理指令.在Makefile中,可以通过include指令将自动生成的依赖关系文件包含进来,从而使得依赖关系文件中 ...
- python学习笔记(7)--爬虫隐藏代理
说明: 1. 好像是这个网站的代理http://www.xicidaili.com/ 2. 第2,3行的模块不用导入,之前的忘删了.. 3. http://www.whatismyip.com.tw/ ...
- 16C554在LINUX上的移植(AT91)
16C554在LINUX上的移植(AT91) linux版本:3.14.17 AT91SAMa5d36 EINTA_0 ARM-IO5 PA14 14 EINTA ...
- Android——加载模式
<activity android:name=".MainActivity" android:launchMode="standard"><! ...
- ApplicationListener接口中的onApplicationEvent被调用两次解决方式
Spring容器初始化完毕后,调用BeanPostProcessor这个类,这个类实现ApplicationListener接口,重写onApplicationEvent方法, 方法中就是我们自己要在 ...