elasticsearch配合mysql实现全文搜索
之前用了sphinx,发现很多东西很久都没更新过了,之前只是知道有elasticsearch这个东西,还以为是java才能用,所以一直没有去了解过,也许sphinx慢慢会被淘汰了吧。
前置条件:需要安装jdk,并配置了 JAVA_HOME。
需要下载的东西
Elasticsearch:
https://www.elastic.co/products/elasticsearch
Logstash:
https://www.elastic.co/products/logstash
mysql-connector:
https://dev.mysql.com/downloads/connector/j/5.1.html
另外:可以安装 kibana,有更友好的数据展示。
elasticsearch、logstash、kibana 的安装在 mac 下可以 brew install
中文搜索需要安装中文分词插件(需要自己去github下载对应的版本 https://github.com/medcl/elasticsearch-analysis-ik/releases):
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip
logstash 和 mysql-connector 是用来实现同步 mysql 数据到 elasticsearch 的。
logstash 配置:https://github.com/elastic/logstash/issues/3429
logstash 需要安装 logstash-input-jdbc 插件:(这一步可能会卡很久,可能的原因是,这个插件使用ruby开发,安装过程需要下载 gem,但是国外的源太慢。)
logstash/bin/plugin install logstash-input-jdbc
logstash 的配置使用查看:https://github.com/elastic/logstash/issues/3429
下面是本机测试配置:
input {
jdbc {
jdbc_driver_library => "/usr/local/elasticsearch/plugins/logstash/mysql-connector-java-5.1.44-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.0.200:3306/vegent?characterEncoding=UTF-8&useSSL=false"
jdbc_user => "test"
jdbc_password => "test"
statement => "SELECT * FROM vegent"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => "192.168.0.200"
index => "vegent"
}
}
2018-06-02 更新:
上面的配置挖了个坑,因为没有限制条件,而且指定了 schedule,所以会一直插入重复索引。
网上有说加以下条件就可以了(没有实践,不指定是否可行):
WHERE id > :sql_last_value
启动Logstash:logstash -f logstash-mysql.conf ,这个logstash-mysql.conf 就是上面的配置。
查看elasticsearch是否同步数据成功:curl '192.168.0.200:9200/_cat/indices?v',如果看到大小在增长则说明同步成功了。
附:解决 gem 下载慢的问题(使用淘宝源)
1、gem sources --add https://ruby.taobao.org/ --remove https://rubygems.org/
2、gem sources -l,确保只有 ruby.taobao.org,
如果 还是显示 https://rubygems.org/ 进入 home的 .gemrc 文件
sudo vim ~/.gemrc
手动删除 https://rubygems.org/
3、修改Gemfile的数据源地址,这个 Gemfile 位于 logstash 目录下,修改 source 的值 为: "https://ruby.taobao.org",修改 Gemfile.jruby-1.9.lock, 找到 remote 修改它的值为: https://ruby.taobao.org (可能有几个 remote 出现,修改后面是 url 那个,替换掉 url)。
4、安装 logstash-input-jdbc,按上面的命令。
5、关于同步的问题,上面设置了一分钟一次,并且无条件同步,实际上是可以只同步那些更新过的数据的,这里还没来得及做深入研究。而且上面的配置还有个问题是,只做插入,而不是更新原有数据,这样其实并不是我们想要的结果。
更新:sql 语句里面可以配置只同步更新过的数据,但是这个更新需要我们去定义,好比如,数据库有一个 update_time 字段,我们更新的时候更新该字段(timestamp类型),这样我们可以把 sql 语句写为 "SELECT * FROM vegent where update_time > :sql_last_value",这个 sql_last_value 在这个时候会是上一次执行该 sql 的时间戳,这样也就实现了更新操作。另外还有一个问题是,elasticsearch 和 logstash 默认使用 UTC 时间戳,这样如果我们保存的是 PRC 时区的时间戳,这样就会有问题,因为这样 logstash 的同步语句中的时间戳是 -8:00 的,所以,还要在配置文件中加上:jdbc_default_timezone => "UTC",最后如下:
最后发现这样虽然 sql 语句时间戳正常了,但是建立的索引里面的时间戳还是 UTC 的时间戳。
最后把 UTC 改为 PRC,最后都正常了,还是和上面一样的情况,索引里面的 @timestamp 还是 UTC 的时间戳。
google 了一下,发现这个好像是不能配置的。这样怎么办呢,也许可以保存 UTC 的时间戳吧,取数据的时候再转 PRC 。(后面证实了这个猜想有点多余,还是应该使用 UTC)
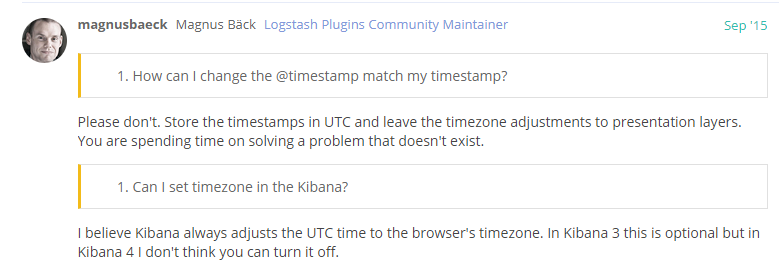
上图链接:https://discuss.elastic.co/t/how-to-set-timestamp-timezone/28401
另外一个猜想是:其实这个@timestamp 对我们的同步更新数据没影响,后来想想发现也是,其实没影响:

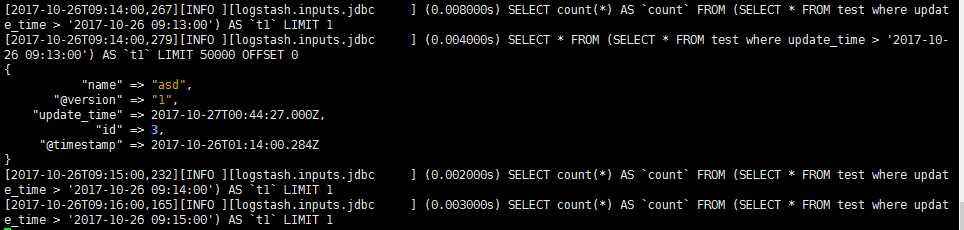
上图中, :sql_last_value 是我们上一次进行 sql 查询的时间。而不是我之前以为的索引里面的 @timestamp 字段,想想也对,如果索引有 100w 数据,那么我应该取那一条记录的 @timestamp 作为 :sql_last_value 呢?
所以结论还是,jdbc_default_timezone 使用 UTC 就可以了。有个需要注意的问题是 时间戳字段要使用 mysql 的timestamp。
jdbc {
jdbc_driver_library => "/home/vagrant/logstash/mysql-connector-java-5.1.44-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.0.200:3306/test?characterEncoding=UTF-8&useSSL=false"
jdbc_user => "test"
jdbc_password => "test"
jdbc_default_timezone => "UTC"
statement => "SELECT * FROM test where update_time > :sql_last_value"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
schedule => "* * * * *"
}
查询例子:
curl 'localhost:9200/vegent/_search?pretty=true' -d '
{
"query" : { "match" : { "type" : "冬瓜" }}
}'
输出(一部分):

查询 type 字段包含了 "冬瓜" 的所有记录。vegent 是索引的名称。?pretty=true 是指定友好输出格式。
返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录,里面子字段的含义如下。
total:返回记录数,本例是487893条。
max_score:最高的匹配程度,本例是5.598418。
hits:返回的记录组成的数组。
logstash 文档地址:https://www.elastic.co/guide/en/logstash/index.html
其他问题:
1、无法远程连接,默认只允许本机连接,可以修改配置文件 elasticsearch/config/elasticsearch.yml
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1
transport.host: localhost
transport.tcp.port: 9300
http.port: 9200
network.host: 0.0.0.0
2、上面的 "同步",并不是真正的同步,当有新数据的时候,上面做的只是把新数据继续加到索引里面,而不是根据对应的 id 去删除原来的数据,这些需要自己做其他操作,目前还没做深入了解。
elasticsearch配合mysql实现全文搜索的更多相关文章
- paip.mysql fulltext 全文搜索.最佳实践.
paip.mysql fulltext 全文搜索.最佳实践. 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blo ...
- MySQL中文全文搜索
我们在mysql数据中可以使用match against语句解决中文全文搜索的问题 先看一个例句: SELECT * FROM v9_search WHERE `siteid`= '1' AND `t ...
- ElasticSearch利用IK实现全文搜索
要做到中文全文检索还需要按照中文分词库 ,这里就使用 IK来设置 安装中文分词库 相关命令: whereis elasticsearch 找到目录 进入 到/usr/elasticsearch/bin ...
- MySQL 全文搜索支持, mysql 5.6.4支持Innodb的全文检索和类memcache的nosql支持
背景:搞个个人博客的全文搜索得用like啥的,现在mysql版本号已经大于5.6.4了也就支持了innodb的全文搜索了,刚查了下目前版本号都到MySQL Community Server 5.6.1 ...
- mysql 全文搜索的FULLTEXT
FULLTEXT索引 创建FULLTEXT索引语法 创建table的时候创建fullText索引 CREATE TABLE table_name( column1 data_type, column2 ...
- 如何在MySQL中获得更好的全文搜索结果
如何在MySQL中获得更好的全文搜索结果 很多互联网应用程序都提供了全文搜索功能,用户可以使用一个词或者词语片断作为查询项目来定位匹配的记录.在后台,这些程序使用在一个SELECT 查询中的LIKE语 ...
- MySQL全文搜索
http://www.yiibai.com/mysql/full-text-search.html 在本节中,您将学习如何使用MySQL全文搜索功能. MySQL全文搜索提供了一种实现各种高级搜索技术 ...
- 使用ElasticSearch服务从MySQL同步数据实现搜索即时提示与全文搜索功能
最近用了几天时间为公司项目集成了全文搜索引擎,项目初步目标是用于搜索框的即时提示.数据需要从MySQL中同步过来,因为数据不小,因此需要考虑初次同步后进行持续的增量同步.这里用到的开源服务就是Elas ...
- 在 Laravel 项目中使用 Elasticsearch 做引擎,scout 全文搜索(小白出品, 绝对白话)
项目中需要搜索, 所以从零开始学习大家都在用的搜索神器 elasiticsearch. 刚开始 google 的时候, 搜到好多经验贴和视频(中文的, 英文的), 但是由于是第一次接触, 一点概念都没 ...
随机推荐
- cmake-cmake.1-3.11.4机翻
指数 下一个 | 上一个 | CMake » git的阶段 git的主 最新发布的 3.13 3.12 3.11.4 3.10 3.9 3.8 3.7 3.6 3.5 3.4 3.3 3.2 3.1 ...
- Machine Learning方法总结
Kmeans——不断松弛(?我的理解)模拟,将点集分成几堆的算法(堆数需要自己定). 局部加权回归(LWR)——非参数学习算法,不用担心自变量幂次选择.(因此当二次欠拟合, 三次过拟合的时候不妨尝试这 ...
- 随机生成30道四则运算-NEW
补充:紧跟上一个随机生成30道四则运算的题目,做了一点补充,可以有真分数之间的运算,于是需要在原来的基础上做一些改进. 首先指出上一个程序中的几个不足:1.每次执行的结果都一样,所以不能每天给孩子出3 ...
- Redis中的GETBIT和SETBIT(转载)
Redis是in-memery的数据库,其优势不言而喻.详细可以阅读一下官网的介绍.https://redis.io 其主要有五种数据类型:strings,lists,sets,hashes.在学习到 ...
- Maven学习——1、安装与修改Maven的本地仓库路径
1.1.下载 官网 http://maven.apache.org/download.cgi 1.2.安装配置 apache-maven-3.3.3-bin.zip 解压下载的压缩包 1.3.配置环境 ...
- BZOJ 1226 学校食堂(状压DP)
状压DP f(i,j,k)表示前i−1个人已经吃了饭,且在i之后的状态为j的人也吃了饭(用二进制表示后面的状态),最后吃的那个人是i之后的第k个 (注意k可以是负数) 然后 如果j&1=1那么 ...
- bzoj1093[ZJOI2007]最大半连通子图(tarjan+拓扑排序+dp)
Description 一个有向图G=(V,E)称为半连通的(Semi-Connected),如果满足:?u,v∈V,满足u→v或v→u,即对于图中任意两点u,v,存在一条u到v的有向路径或者从v到u ...
- 【bzoj3560】DZY Loves Math V 欧拉函数
题目描述 给定n个正整数a1,a2,…,an,求 的值(答案模10^9+7). 输入 第一行一个正整数n. 接下来n行,每行一个正整数,分别为a1,a2,…,an. 输出 仅一行答案. 样例输入 3 ...
- 【bzoj1005】[HNOI2008]明明的烦恼 Prufer序列+高精度
题目描述 给出标号为1到N的点,以及某些点最终的度数,允许在任意两点间连线,可产生多少棵度数满足要求的树? 输入 第一行为N(0 < N < = 1000),接下来N行,第i+1行给出第i ...
- LeetCode 696. Count Binary Substrings
Give a string s, count the number of non-empty (contiguous) substrings that have the same number of ...