十八 Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
我们自定义一个main.py来作为启动文件
main.py

#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy.cmdline import execute #导入执行scrapy命令方法
import sys
import os sys.path.append(os.path.join(os.getcwd())) #给Python解释器,添加模块新路径 ,将main.py文件所在目录添加到Python解释器 execute(['scrapy', 'crawl', 'pach', '--nolog']) #执行scrapy命令
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
import urllib.response
from lxml import etree
import re class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
pass
xpath表达式
1、
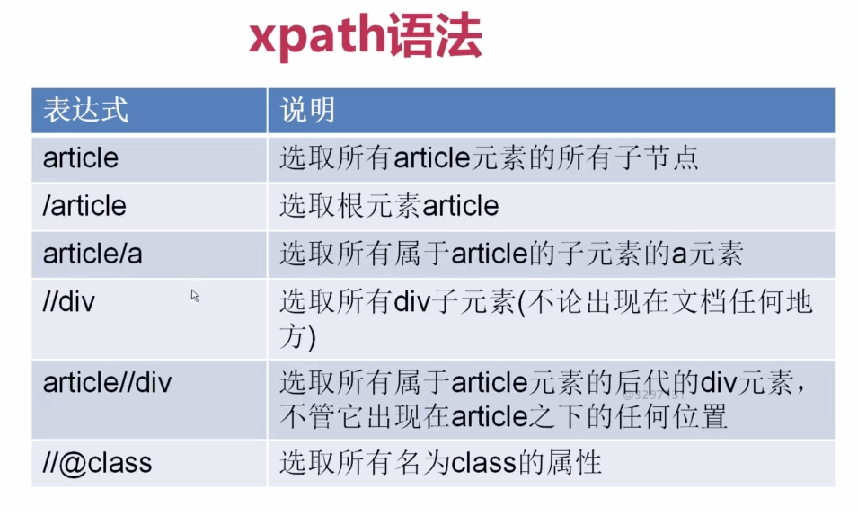
2、
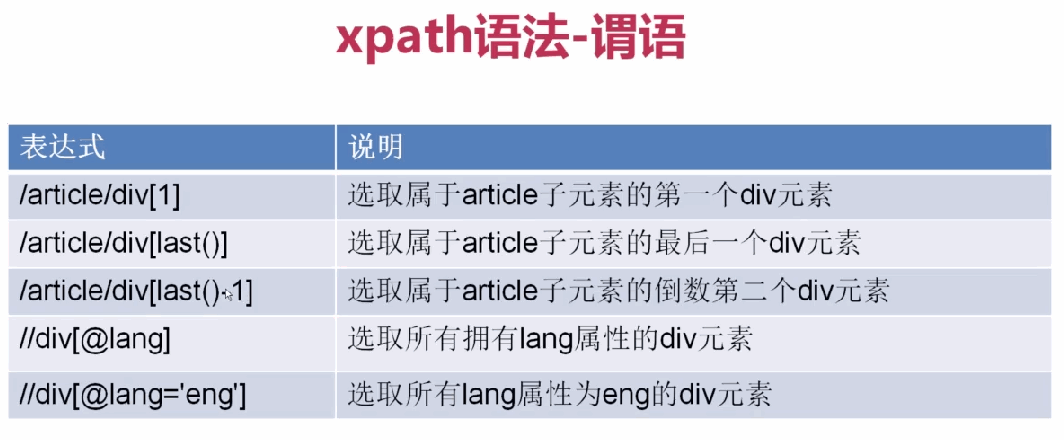
3、

基本使用
allowed_domains设置爬虫起始域名
start_urls设置爬虫起始url地址
parse(response)默认爬虫回调函数,response返回的是爬虫获取到的html信息对象,里面封装了一些关于htnl信息的方法和属性
responsehtml信息对象下的方法和属性
response.url获取抓取的rul
response.body获取网页内容
response.body_as_unicode()获取网站内容unicode编码
xpath()方法,用xpath表达式过滤节点
extract()方法,获取过滤后的数据,返回列表
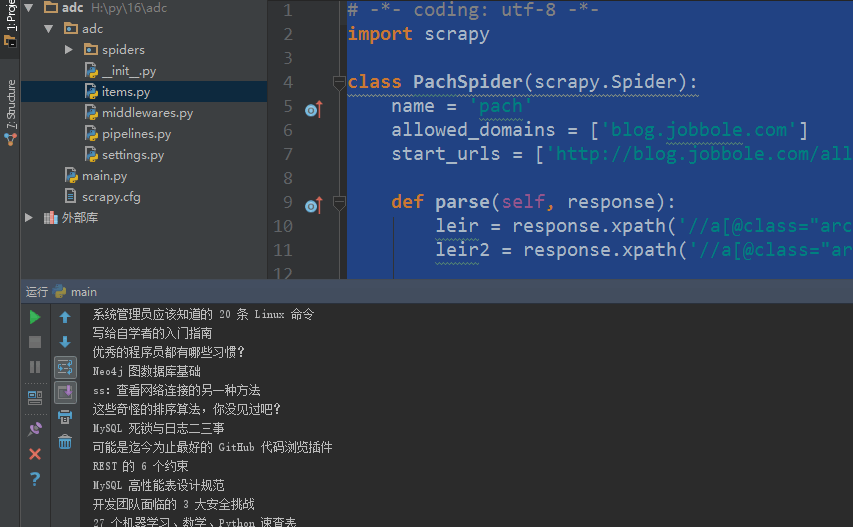
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
leir = response.xpath('//a[@class="archive-title"]/text()').extract() #获取指定标题
leir2 = response.xpath('//a[@class="archive-title"]/@href ').extract() #获取指定url print(response.url) #获取抓取的rul
print(response.body) #获取网页内容
print(response.body_as_unicode()) #获取网站内容unicode编码 for i in leir:
print(i)
for i in leir2:
print(i)
十八 Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式的更多相关文章
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
- 四十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
Django实现搜索功能 1.在Django配置搜索结果页的路由映射 """pachong URL Configuration The `urlpatterns` lis ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 二十九 Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以 ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
随机推荐
- Mock Server 之 moco-runner 使用指南一
文章出处http://ju.outofmemory.cn/entry/96866 用以下命令可以启动moco-runner 服务 java -jar moco-runner-<version&g ...
- SQL Server OBJECTPROPERTY使用方法
OBJECTPROPERTY 返回有关当前数据库中的模式作用域对象的信息.此函数不能用于不是模式范围的对象,例如数据定义语言(DDL)触发器和事件通知. OBJECTPROPERTY 语法: OBJE ...
- Docker+.Net Core 的那些事儿-2.创建Docker镜像
1.从store.docker.com获取.net core镜像 docker pull microsoft/dotnet 2.创建一个.net core项目,并发布 在上篇文章结尾建立的工作目录下, ...
- 51nod 1391 01串(hash+DP)
题目链接题意:给定一个01串S,求出它的一个尽可能长的子串S[i..j],满足存在一个位置i<=x <=j, S[i..x]中0比1多,而S[x + 1..j]中1比0多.求满足条件的最长 ...
- windows7上安装php7和apche2.4
windows7在配置php7+apache2.4 1.下载并安装vc14http://www.microsoft.com/zh-cn/download/details.aspx?id=48145下载 ...
- jenkins windows执行批处理脚本总是失败
使用jenkins 在使用编译vc++的一个项目,在执行批处理脚本的时候总是失败, 但是在控制台无论是管理员还是普通用户都能正常编译,jenkins每次都失败,看日志就是调用一个cmd命令直接失败,e ...
- Java学习第三周摘要
20145307<Java程序设计>第三周学习总结 教材学习内容总结 认识对象 类类型 Java可区分为基本类型和类类型两大类型系统,其中类类型也称为参考类型.sun就是一个类类型变量,类 ...
- 20145335郝昊《java程序设计》第2次实验报告
20145335郝昊<java程序设计>第2次实验报告 实验名称 Java面向程序设计,采用TDD的方式设计有关实现复数类Complex. 理解并掌握面向对象三要素:封装.继承.多态. 运 ...
- 关于C++中的string的小知识点
这是GCC版本5.x的情况下的分析,在GCC版本4.x的情况下std::string的内存布局将不同.逆向C++的过程中经常遇到std::string,它在内存中的状态是什么样呢?我先简单地写了一个程 ...
- set /p= 详解
在批处理中回显信息有两个命令,echo和set /p=<nul,它们的共同点在于都是对程序执行信息的屏幕输出,区别在于echo是换行输出,而set /p=<nul是不换行追回输出,这样说大 ...