Hadoop笔记之搭建环境
Hadoop的环境搭建分为单机模式、伪分布式模式、完全分布式模式。
因为我的本本比较挫,所以就使用伪分布式模式。
安装JDK
一般Linux自带的Java运行环境都是Open JDK,我们到官网下载Oracle JDK(http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html):

需要注意的是官网上直接右键复制的话是下载不成功的,F12,单机,看网络请求包:
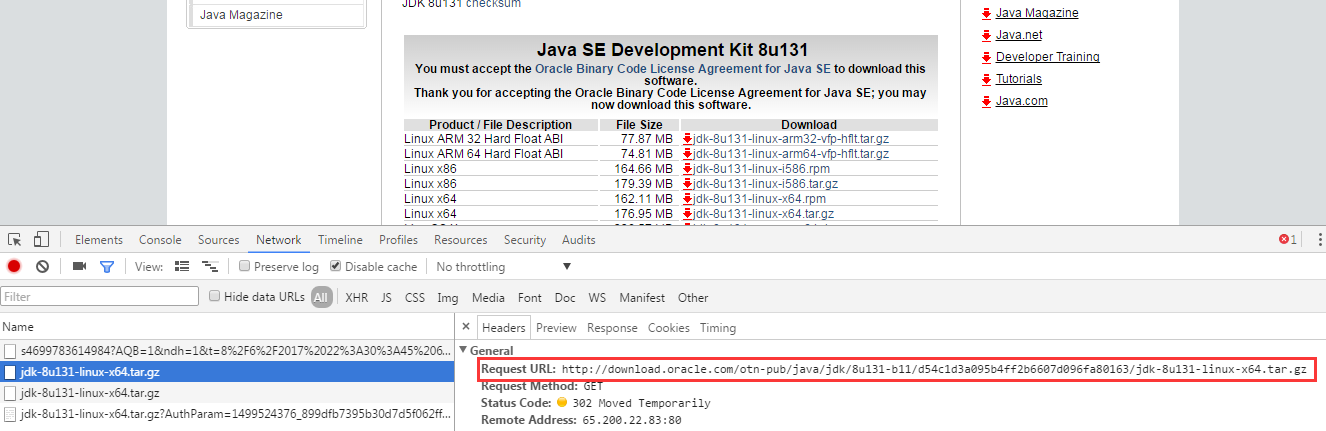
然后复制地址wget即可:
wget http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
解压:
tar zxvf jdk-8u131-linux-x64.tar.gz
配置相关的环境变量:
vim /etc/profile
如果还没有vim的话可以使用yum install vim来安装,在profile文件末尾追加:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
重新加载profile:
source /etc/profile
查看Java版本:

如果是默认的话就是Open JDK,这里已经换成了Oracle JDK了,JDK安装完成。
配置SSH免密码登录
在当前用户目录下新建隐藏文件.ssh:
mkdir .ssh
cd到.ssh目录中,生成公钥和私钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
把公钥追加到授权key中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后尝试直接连接到本地:
ssh -version
第一次可能会有提示,再之后登陆的时候会直接登陆进来而无需每次都输入密码。
安装Hadoop
到官网找到一个合适的版本 http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.8.0/:
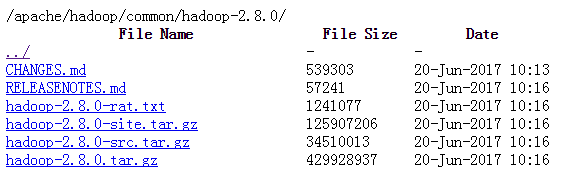
使用wget下载到本地:
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz

如果wget还没有安装的话,使用下面的命令安装:
yum install wget
解压targz文件:
tar zxvf hadoop-2.8.0.tar.gz
修改Hadoop的配置文件($HADOOP_HOME/etc/hadoop):
vim core-site.xml
编辑内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.2.131:9000</value>
</property>
</configuration>
需要注意的是这里配置的路径中不能使用~来代替宿主目录,不然后面初始化的时候找不到此目录就会报NPE。
编辑mapred-site.xml.template文件:
vim mapred-site.xml.template
修改内容:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.2.131:9001</value>
</property>
</configuration>
编辑hdfs-site.xml文件:
vim hdfs-site.xml
编辑内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/tmp/dfs/data</value>
</property>
</configuration>
初始化Hadoop目录,在$HADOOP_HOME/bin下执行:
./hdfs namenode -format
出现这个就说明初始化成功了:
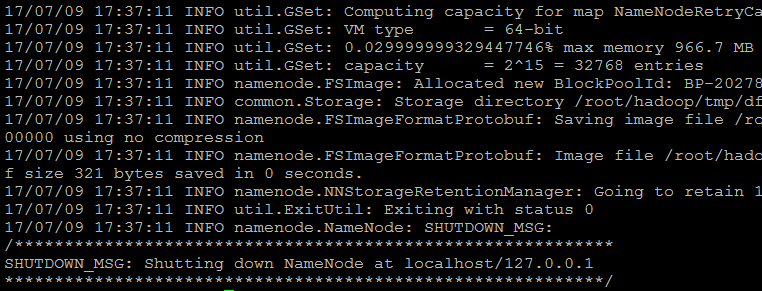
启动NameNode和DataNode守护进程:
切换到$HADOOP_HOME/sbin下,执行:
./start-dfs.sh
如果启动的时候报了这个错的话:

切换到$HADOOP_HOME下,执行:
vim etc/hadoop/hadoop-env.sh
在文件的末尾追加$JAVA_HOME变量:
export JAVA_HOME=/usr/local/jdk1.8.0_131
启动完毕使用jps命令查看进程信息:
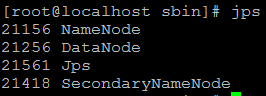
上面这样子说明就是启动成功了。
在浏览器中输入http://192.168.2.131:50070可查看web界面。
但是这个时候要使用hadoop命令还必须得去特定的目录下使用,将其加入到$PATH中:
vim /etc/profile
在文件尾部追加:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/usr/local/hadoop-2.8.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
重新加载一下:
source /etc/profile
测试一下:

.
Hadoop笔记之搭建环境的更多相关文章
- struts2学习笔记--动手搭建环境+第一个helloworld项目
在Myeclipse中已经内置好了struts2的环境,但是为了更好的理解,这里自己从头搭建一下: 前期准备:下载struts2的完整包,下载地址:https://struts.apache.org/ ...
- [转]Java Web笔记:搭建环境和项目配置(MyEclipse 2014 + Maven + Tomcat)
来源:http://www.jianshu.com/p/56caa738506a 0. 绪言 Java Web开发中,除了基础知识外,开发环境搭建,也是一项基本功.开发环境包括了IDE.项目管理.项目 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(4) ——搭建开发环境及编写Hello World
Hadoop学习笔记(4) ——搭建开发环境及编写Hello World 整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA.在linux下开发JAVA还数eclip ...
- 【深入浅出 Yarn 架构与实现】1-2 搭建 Hadoop 源码阅读环境
本文将介绍如何使用 idea 搭建 Hadoop 源码阅读环境.(默认已安装好 Java.Maven 环境) 一.搭建源码阅读环境 一)idea 导入 hadoop 工程 从 github 上拉取代码 ...
- 【自动化学习笔记】_环境搭建Selenium2+Eclipse+Java+TestNG_(一)
目录 第一步 安装JDK 第二步 下载Eclipse 第三步 在Eclipse中安装TestNG 第四步 下载Selenium IDE.SeleniumRC.IEDriverServer 第五步 下 ...
- Linux巩固记录(3) hadoop 2.7.4 环境搭建
由于要近期使用hadoop等进行相关任务执行,操作linux时候就多了 以前只在linux上配置J2EE项目执行环境,无非配置下jdk,部署tomcat,再通过docker或者jenkins自动部署上 ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
随机推荐
- Mac下Git的基础操作
目前最火的版本控制软件是Git了吧,今天简单梳理一下Mac下Git的基础操作~~ 一.什么是Git Git是一个分布式代码管理工具,用于敏捷的处理或大或小的项目,类似的工具还有svn. 基于Git的快 ...
- jdk&tomcat环境变量配置及同时运行多个tomcat方法
一:jdk配置 安装jdk1.7.0_51,安装过程中所有选项保持默认:最后配置 JDK的环境变量: 在“我的电脑”上点右键—>“属性”—>“高级”—>“环境变量(N)”. 1.新建 ...
- 【转载】mysql建表date类型不能设置默认值
如题,mysql建表date类型的不能设置一个默认值,比如我这样: CREATE TABLE `new_table` ( `biryhday` datetime NULL DEFAULT '1996- ...
- Tomcat安装及配置详解
Tomcat安装及配置详解 一,Tomcat简介 Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,Tomcat是Apache 软件基金会(Apache Software Found ...
- 第104天:web字体图标使用方法
字体图标经常使用的是 阿里图标库的:http://www.iconfont.cn/ icomoon图标库的:https://icomoon.io/ 一.阿里库字体图标使用 第一步: 首先进入阿里巴巴矢 ...
- post方法的数据类型
form-data.x-www-form-urlencoded.raw.binary的区别 1. form-data 就是http请求中的multipart/form-data,它会将表单的数据处理为 ...
- 洛谷 P4390 [BOI2007]Mokia 摩基亚 解题报告
P4390 [BOI2007]Mokia 摩基亚 题目描述 摩尔瓦多的移动电话公司摩基亚(\(Mokia\))设计出了一种新的用户定位系统.和其他的定位系统一样,它能够迅速回答任何形如"用户 ...
- SSH不能连接并提示REMOTE HOST IDENTIFICATION HAS CHANGED解决
SSH不能连接并提示REMOTE HOST IDENTIFICATION HAS CHANGED解决方法: 如果提示信息如下: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ ...
- 框架----Django框架知识点整理
一.cbv cbv(class-base-view) 基于类的视图 fbv(func-base-view) 基于函数的视图 a.基本演示 urlpatterns = [ url(r'^login.ht ...
- Codeforces Round #298 (Div. 2)A B C D
A. Exam time limit per test 1 second memory limit per test 256 megabytes input standard input output ...