Hadoop笔记之搭建环境
Hadoop的环境搭建分为单机模式、伪分布式模式、完全分布式模式。
因为我的本本比较挫,所以就使用伪分布式模式。
安装JDK
一般Linux自带的Java运行环境都是Open JDK,我们到官网下载Oracle JDK(http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html):

需要注意的是官网上直接右键复制的话是下载不成功的,F12,单机,看网络请求包:
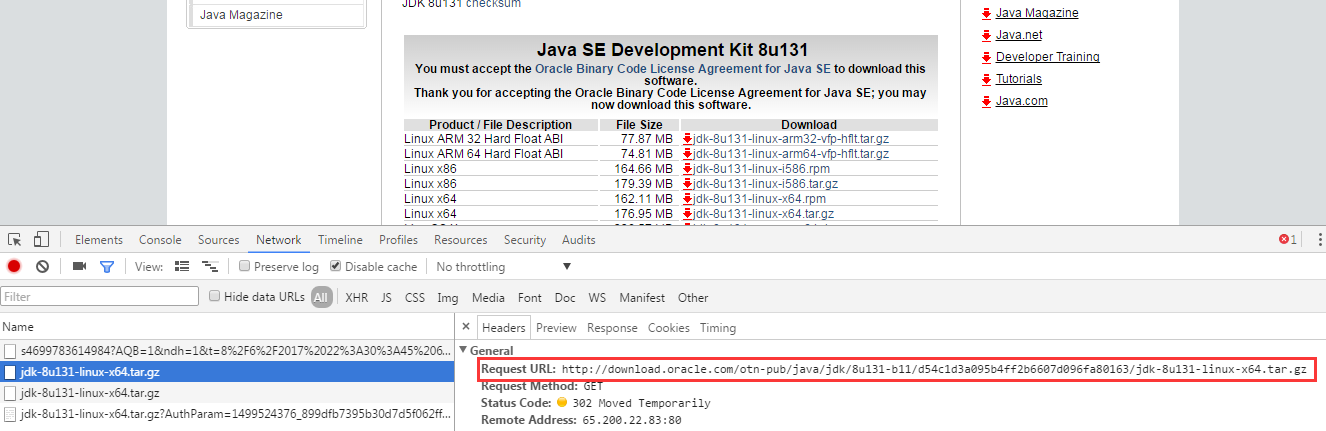
然后复制地址wget即可:
wget http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
解压:
tar zxvf jdk-8u131-linux-x64.tar.gz
配置相关的环境变量:
vim /etc/profile
如果还没有vim的话可以使用yum install vim来安装,在profile文件末尾追加:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
重新加载profile:
source /etc/profile
查看Java版本:

如果是默认的话就是Open JDK,这里已经换成了Oracle JDK了,JDK安装完成。
配置SSH免密码登录
在当前用户目录下新建隐藏文件.ssh:
mkdir .ssh
cd到.ssh目录中,生成公钥和私钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
把公钥追加到授权key中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后尝试直接连接到本地:
ssh -version
第一次可能会有提示,再之后登陆的时候会直接登陆进来而无需每次都输入密码。
安装Hadoop
到官网找到一个合适的版本 http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.8.0/:
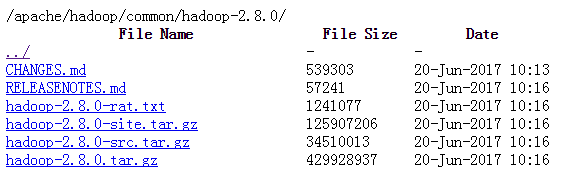
使用wget下载到本地:
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz

如果wget还没有安装的话,使用下面的命令安装:
yum install wget
解压targz文件:
tar zxvf hadoop-2.8.0.tar.gz
修改Hadoop的配置文件($HADOOP_HOME/etc/hadoop):
vim core-site.xml
编辑内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.2.131:9000</value>
</property>
</configuration>
需要注意的是这里配置的路径中不能使用~来代替宿主目录,不然后面初始化的时候找不到此目录就会报NPE。
编辑mapred-site.xml.template文件:
vim mapred-site.xml.template
修改内容:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.2.131:9001</value>
</property>
</configuration>
编辑hdfs-site.xml文件:
vim hdfs-site.xml
编辑内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/tmp/dfs/data</value>
</property>
</configuration>
初始化Hadoop目录,在$HADOOP_HOME/bin下执行:
./hdfs namenode -format
出现这个就说明初始化成功了:
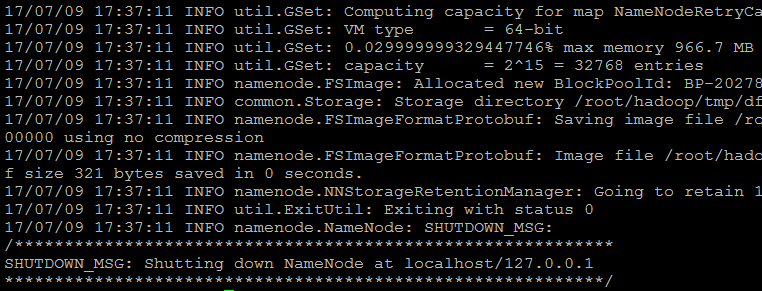
启动NameNode和DataNode守护进程:
切换到$HADOOP_HOME/sbin下,执行:
./start-dfs.sh
如果启动的时候报了这个错的话:

切换到$HADOOP_HOME下,执行:
vim etc/hadoop/hadoop-env.sh
在文件的末尾追加$JAVA_HOME变量:
export JAVA_HOME=/usr/local/jdk1.8.0_131
启动完毕使用jps命令查看进程信息:
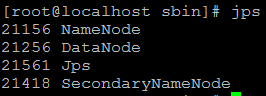
上面这样子说明就是启动成功了。
在浏览器中输入http://192.168.2.131:50070可查看web界面。
但是这个时候要使用hadoop命令还必须得去特定的目录下使用,将其加入到$PATH中:
vim /etc/profile
在文件尾部追加:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/usr/local/hadoop-2.8.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
重新加载一下:
source /etc/profile
测试一下:

.
Hadoop笔记之搭建环境的更多相关文章
- struts2学习笔记--动手搭建环境+第一个helloworld项目
在Myeclipse中已经内置好了struts2的环境,但是为了更好的理解,这里自己从头搭建一下: 前期准备:下载struts2的完整包,下载地址:https://struts.apache.org/ ...
- [转]Java Web笔记:搭建环境和项目配置(MyEclipse 2014 + Maven + Tomcat)
来源:http://www.jianshu.com/p/56caa738506a 0. 绪言 Java Web开发中,除了基础知识外,开发环境搭建,也是一项基本功.开发环境包括了IDE.项目管理.项目 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(4) ——搭建开发环境及编写Hello World
Hadoop学习笔记(4) ——搭建开发环境及编写Hello World 整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA.在linux下开发JAVA还数eclip ...
- 【深入浅出 Yarn 架构与实现】1-2 搭建 Hadoop 源码阅读环境
本文将介绍如何使用 idea 搭建 Hadoop 源码阅读环境.(默认已安装好 Java.Maven 环境) 一.搭建源码阅读环境 一)idea 导入 hadoop 工程 从 github 上拉取代码 ...
- 【自动化学习笔记】_环境搭建Selenium2+Eclipse+Java+TestNG_(一)
目录 第一步 安装JDK 第二步 下载Eclipse 第三步 在Eclipse中安装TestNG 第四步 下载Selenium IDE.SeleniumRC.IEDriverServer 第五步 下 ...
- Linux巩固记录(3) hadoop 2.7.4 环境搭建
由于要近期使用hadoop等进行相关任务执行,操作linux时候就多了 以前只在linux上配置J2EE项目执行环境,无非配置下jdk,部署tomcat,再通过docker或者jenkins自动部署上 ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
随机推荐
- workstation vmware 制作vm模板
[root@VM166136 ~]# cat copy_vmware.sh #!/bin/bash if [ $(id -u) -ne 0 ];then echo "Please use t ...
- 免费各种查询API接口
快递查询 http://www.kuaidi100.com/query?type=quanfengkuaidi&postid=390011492112 (PS:快递公司编码:申通"s ...
- HDU4045_Machine scheduling
题意为要你从编号为1-n的所有机器中间选择出r个机器且每一个机器的编号只差不小于k-1,然后将选择的r个机器分为m组有多少种方案. 其实这题目的两个步骤是相互独立的. 总共的方案数等于选择的方案数乘以 ...
- lucence学习系列之一 基本概念
1. Lucence基本概念 Lucence是一个java编写的全文检索类库,使用它可以为一个应用或者站点增加检索功能. 它通过增加内容到一个全文索引来完成检索功能.然后允许你基于这个索引去查询,返回 ...
- bzoj4032-最短不公共子串
题意 给出两个长度小于等于2000的小写字母串,四个问题: A的最短子串不是B的子串 A的最短子串不是B的子序列 A的最短子序列不是B的子串 A的最短子序列不是B的子序列 分析 虽然求的是不公共,但是 ...
- 【loj6041】「雅礼集训 2017 Day7」事情的相似度 后缀自动机+STL-set+启发式合并+离线+扫描线+树状数组
题目描述 给你一个长度为 $n$ 的01串,$m$ 次询问,每次询问给出 $l$ .$r$ ,求从 $[l,r]$ 中选出两个不同的前缀的最长公共后缀长度的最大值. $n,m\le 10^5$ 题解 ...
- 求n!中因子k的个数
思路: 求n的阶乘某个因子k的个数,如果n比较小,可以直接算出来,但是如果n很大,此时n!超出了数据的表示范围,这种直接求的方法肯定行不通.其实n!可以表示成统一的方式. n!=(km)*(m!)*a ...
- linux设置开机自动启动
有很多中方法,这里只取最简单的一种: 把启动命令放到/etc/rc.d/rc.local文件里这样就可以每次启动的时候自动启动服务了, 注意给rc.local执行权限
- 【单调栈】【CF5E】 Bindian Signalizing
传送门 Description 给你一个环,环上有一些点,点有点权.定义环上两点能相互看见当且仅当两点间存在一个弧使得弧上不存在一个点的点权大于着两个点.求一共有多少个点能互相看到 Input 第一行 ...
- [转载]DataView详解
表示用于排序.筛选.搜索.编辑和导航的 DataTable 的可绑定数据的自定义视图. DataView的功能类似于数据库的视图,他是数据源DataTable的封装对象,可以对数据源进行排序.搜索.过 ...