hadoop2.7.7 分布式集群安装与配置
环境准备
服务器四台:
| 系统信息 | 角色 | hostname | IP地址 |
| Centos7.4 | Mster | hadoop-master-001 | 10.0.15.100 |
| Centos7.4 | Slave | hadoop-slave-001 | 10.0.15.99 |
| Centos7.4 | Slave | hadoop-slave-002 | 10.0.15.98 |
| Centos7.4 | Slave | hadoop-slave-003 | 10.0.15.97 |
四台节点统一操作操作
创建操作用户
gourpadd hduser
useradd hduser -g hduser 切换用户并配置java环境变量
笔者这里用的1.8的
JAVA_HOME=~/jdk1.8.0_151
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export PATH 配置/etc/hosts
10.0.15.100 hadoop-master-001
10.0.15.99 hadoop-data-001
10.0.15.98 hadoop-data-002
10.0.15.97 hadoop-data-003 设置ssh免密
这个网上比较多,这里不在累述
安装流程(所有节点,包括master与slave)
下载hadoop并安装
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
tar -zxvf hadoop-2.7.7.tar.gz
移动并修改权限
chown hduser:hduser hadoop-2.7.7
mv hadoop-2.7.7 /usr/local/hadoop
切换用户并配置环境变量
su - hduser
vim .basrc #变量信息
export JAVA_HOME=/home/hduser/jdk1.8.0_151
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
修改Master配置文件
vim hadoop-env.sh
/**/
配置java路径
export JAVA_HOME=/home/hduser/jdk1.8.0_151
/**/
vim core-site.xml
/**/
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master-001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_data/hadoop_tmp</value>
</property>
</configuration>
/**/
vim hdfs-site.xml
/**/
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop_data/hdfs/namenode</value> #创建真实的路径用来存放名称节点
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop_data/hdfs/datanode</value> #创建真实的路径用了存放数据
</property>
</configuration>
/**/
vim mapred-site.xml
/**/
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
/**/
vim yarn-site.xml
/**/
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master-001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master-001:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master-001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-master-001:8025</value>
</property>
#使用hadoop yarn运行pyspark时,不添加下面两个参数会报错
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
/**/
修改Slave配置文件
vim hadoop-env.sh
/**/
配置java路径
export JAVA_HOME=/home/hduser/jdk1.8.0_151
/**/
vim core-site.xml
/**/
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master-001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_data/hadoop_tmp</value>
</property>
</configuration>
/**/
vim hdfs-site.xml
/**/
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/data/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
/**/
vim mapred-site.xml
/**/
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master-001:54311</value>
</property>
</configuration>
/**/
vim yarn-site.xml
/**/
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-master-001:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-master-001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-master-001:8025</value>
</property>
#使用hadoop yarn运行pyspark时,不添加下面两个参数会报错
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
/**/
其他操作(所有节点,包括master与slave)
#执行hadoop 命令报WARNING解决办法
vim log4j.properties添加如下行
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
启动操作
安装并配置完成后返回master节点格式化namenode
cd /data/hadoop_data/hdfs/namenode
hadoop namenode -format 在master节点执行命令
start-all.sh //启动
stop-all.sh //关闭
异常处理
hadoop数据节点查看hdfs文件时:
ls: No Route to Host from hadoop-data-002/10.0.15.98 to hadoop-master-001:9000 failed on socket timeout exception: java.net.NoRouteToHostException: 没有到主机的路由; For more details see: http://wiki.apache.org/hadoop/NoRouteToHost 解决方式数据节点telnet namenode的9000端口
正常原因/etc/hosts中主机名与ip地址不符或者端口未开放防火墙引起
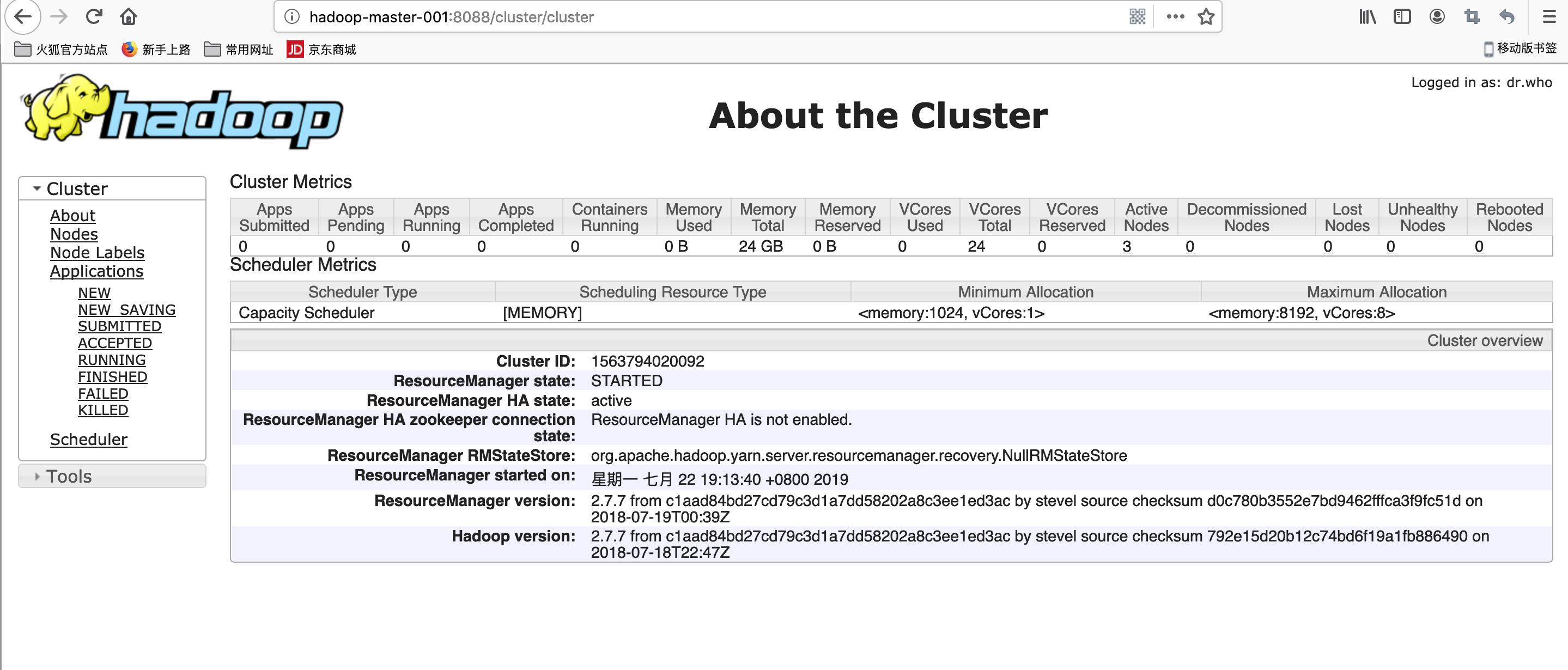
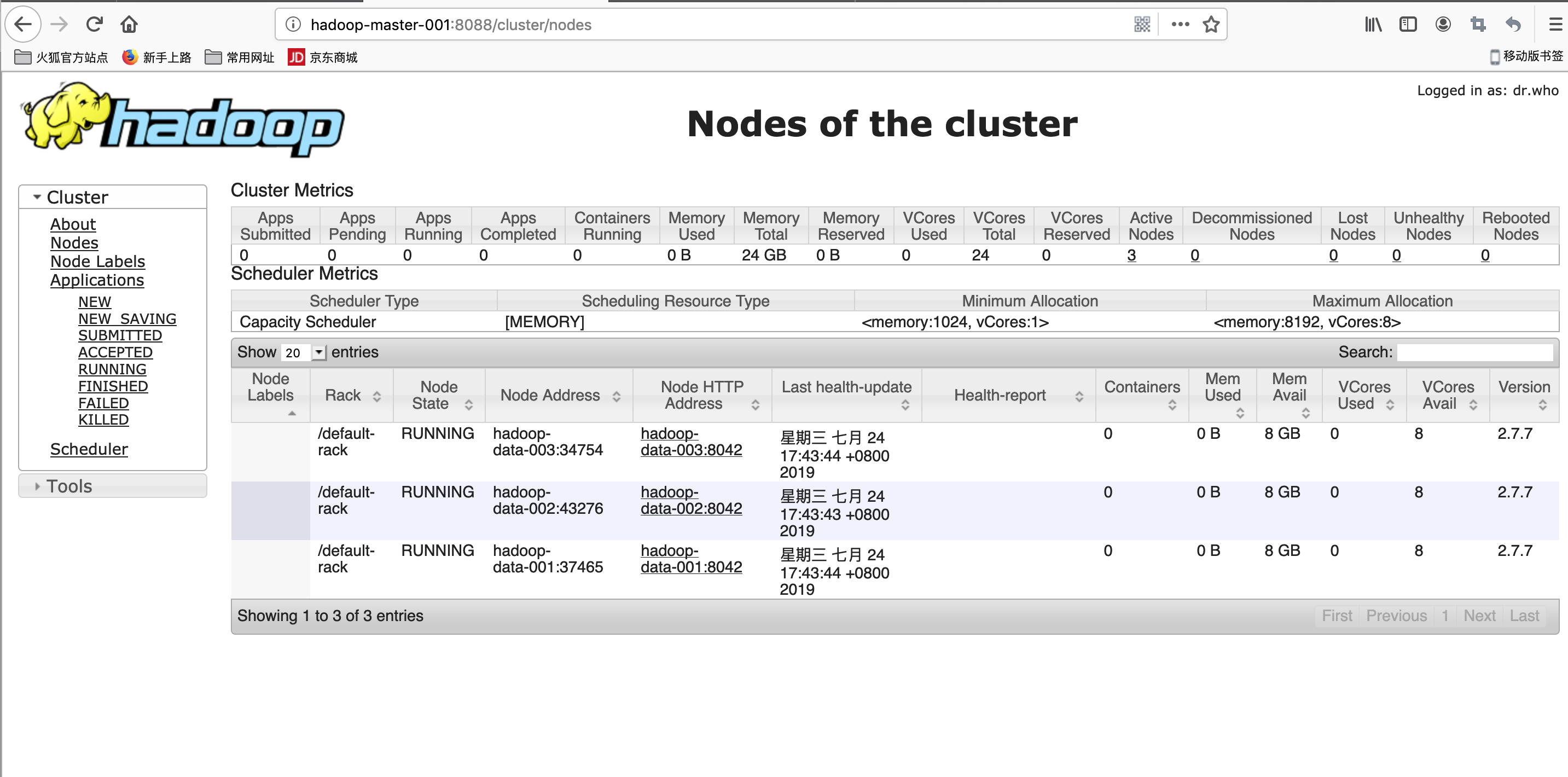
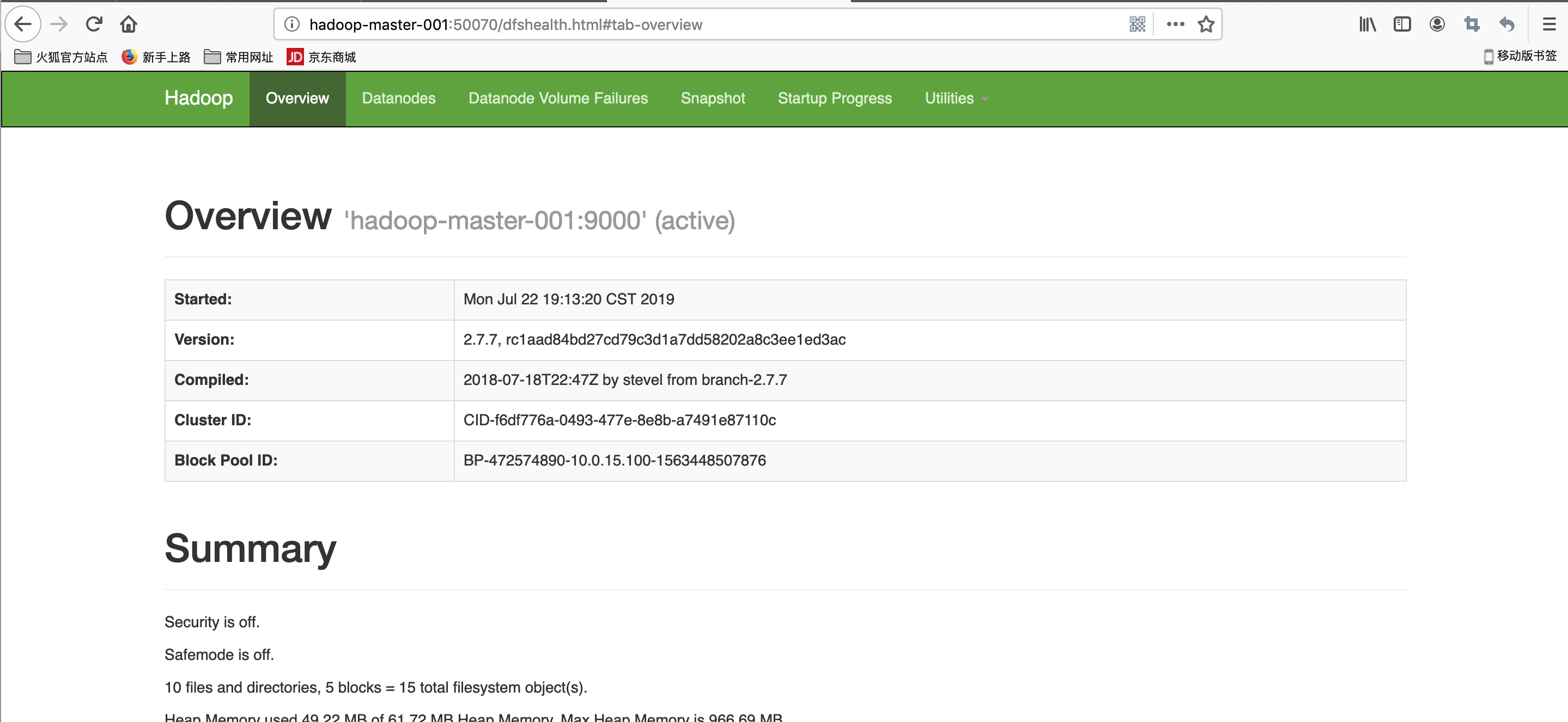
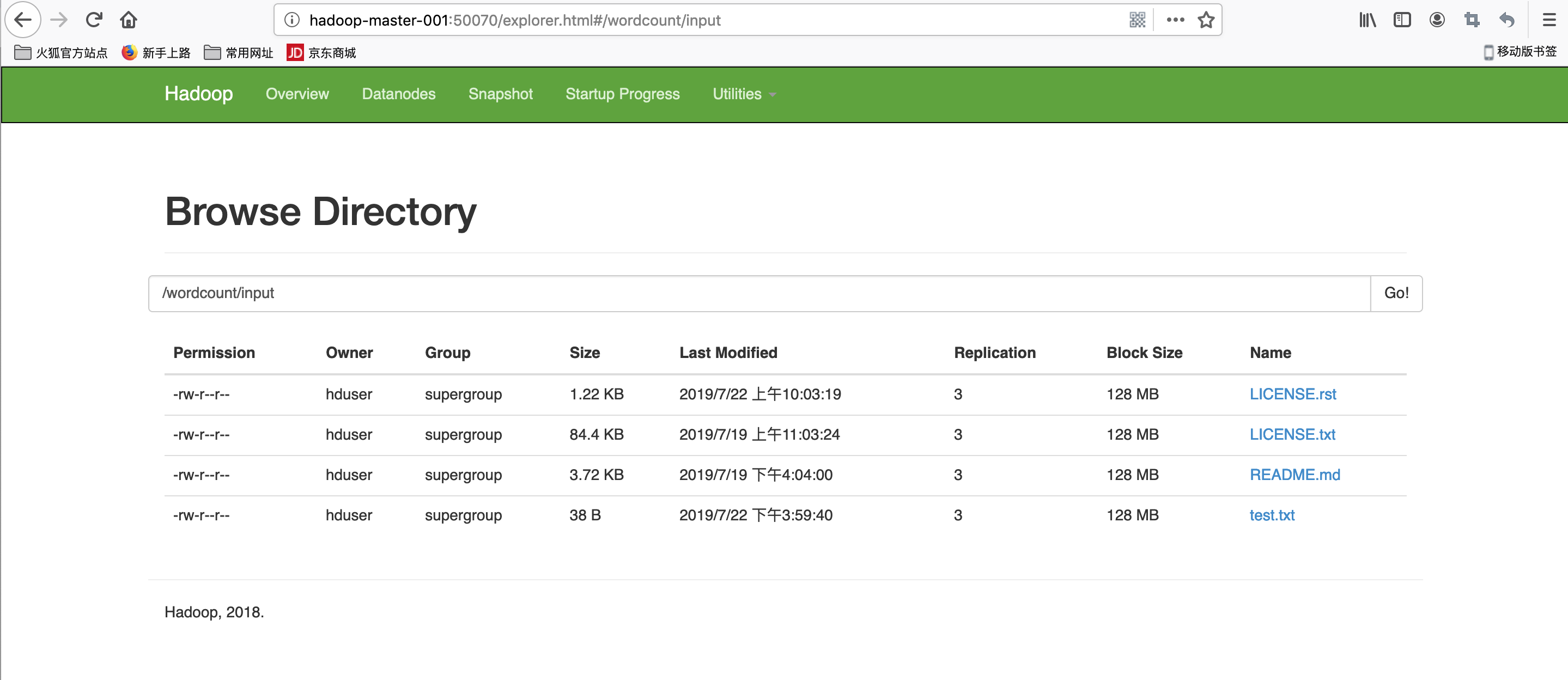
效果图
扩展连接
hadoop2.7.7 分布式集群安装与配置的更多相关文章
- Hadoop2.7.3分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 二.文件准备 2.1 文件名称 hadoop-2.7.3.tar.g ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- Springboot 2.0.x 集成基于Centos7的Redis集群安装及配置
Redis简介 Redis是一个基于C语言开发的开源(BSD许可),开源高性能的高级内存数据结构存储,用作数据库.缓存和消息代理.它支持数据结构,如 字符串.散列.列表.集合,带有范围查询的排序集,位 ...
- ActiveMQ 高可用集群安装、配置(ZooKeeper + LevelDB)
ActiveMQ 高可用集群安装.配置(ZooKeeper + LevelDB) 1.ActiveMQ 集群部署规划: 环境: JDK7 版本:ActiveMQ 5.11.1 ZooKeeper 集群 ...
- MySQL集群安装与配置
MySQL集群安装与配置 文章目录 [隐藏] 一.mysql集群安装 二.节点配置 三.首次启动节点 四.测试服务是否正常 五.安全关闭和重启 MySQL Cluster 是 MySQL 适合于分 ...
随机推荐
- Linux用户组
1.介绍 类似于角色,系统可以对有共性的多个用户进行统一的管理 2.增加组 groupadd 组名 3.删除组 groupdel 组名 4.增加用户时直接为用户指定组 useradd -g 用 ...
- 问题分析——Maven打包后发版,静态资源找不到
一.背景 Xxl-Job-Admin(开源分布式调度中心)项目在本地运行正常,Jenkins发版到测试环境,发版成功后,打开管理页面,页面css.js找不到. 怀疑是Maven没有把静态资源打包进去导 ...
- 第四章 基本TCP套接字编程 第五章 TCP客户/服务器程序实例
TCP客户与服务器进程之间发生的重大事件时间表 TCP服务器 socket() --- bind() --- listen() --- accept() --- read() --- write -- ...
- Asis_2016_b00ks wp
目录 程序基本信息 程序漏洞 利用思路 exp脚本 参考 程序基本信息 程序漏洞 有一个读入函数,程序的所有输入都靠它读取,这个程序有个很明显的off_by_one漏洞,在输入时多输入一个0字符. 利 ...
- apache配置https重定向
apache配置https重定向 一.总结 一句话总结: 网上找不到答案的原因是因为没有精准的描述问题,没有把问题描述清楚:尽量把关键词描述清楚 1.apache将80端口重定向443的具体步骤(在 ...
- TynSerial序列(还原)TClientDataSet
TynSerial序列(还原)TClientDataSet 可以一次性序列(还原)多个TClientDataSet. 1)TClientDataSet查询数据 procedure TForm1.Qry ...
- java 抽象类为什么不能被实例化?
我把CSDN论坛里面的一个帖子内容list到下面,自己看着理解,东家一言,西家一语,杂合起来,基本上也就理解了java中的抽象类为什么不能被实例化了. 因篇幅有限,只能罗列部分留言 以下内容不分先后顺 ...
- LC 992. Subarrays with K Different Integers
Given an array A of positive integers, call a (contiguous, not necessarily distinct) subarray of A g ...
- vs2012编译的程序不能在XP和2003下执行问题的解决方法
问题如题,通过无数次百度和谷歌后,发现,微软已经确认这是一个缺陷,安装Vs2012的update 3的升级包就可以解决问题.同时,在分发包的地方,vcredist_x86.exe 随程序分发一份就可以 ...
- c# 如何给 dataGridView里添加一个自增长列(列名为序号)
System.Data.DataTable table = new DataTable(); System.Data.DataColumn column = new Da ...