爬 NationalData ,虽然可以直接下,但还是爬一下吧
爬取的是分省月度数据,2017年的,包括:居民消费价格指数,食品烟酒类居民消费价格指数,衣着类居民消费价格指数,居住类居民消费价格指数,生活用品及服务类居民消费价格指数,交通和通信类居民消费价格指数,教育文化和娱乐类居民消费价格指数,医疗保健类居民消费价格指数,其他用品和服务类居民消费价格指数。
打开网站,地区数据-----分省月度数据,如图:
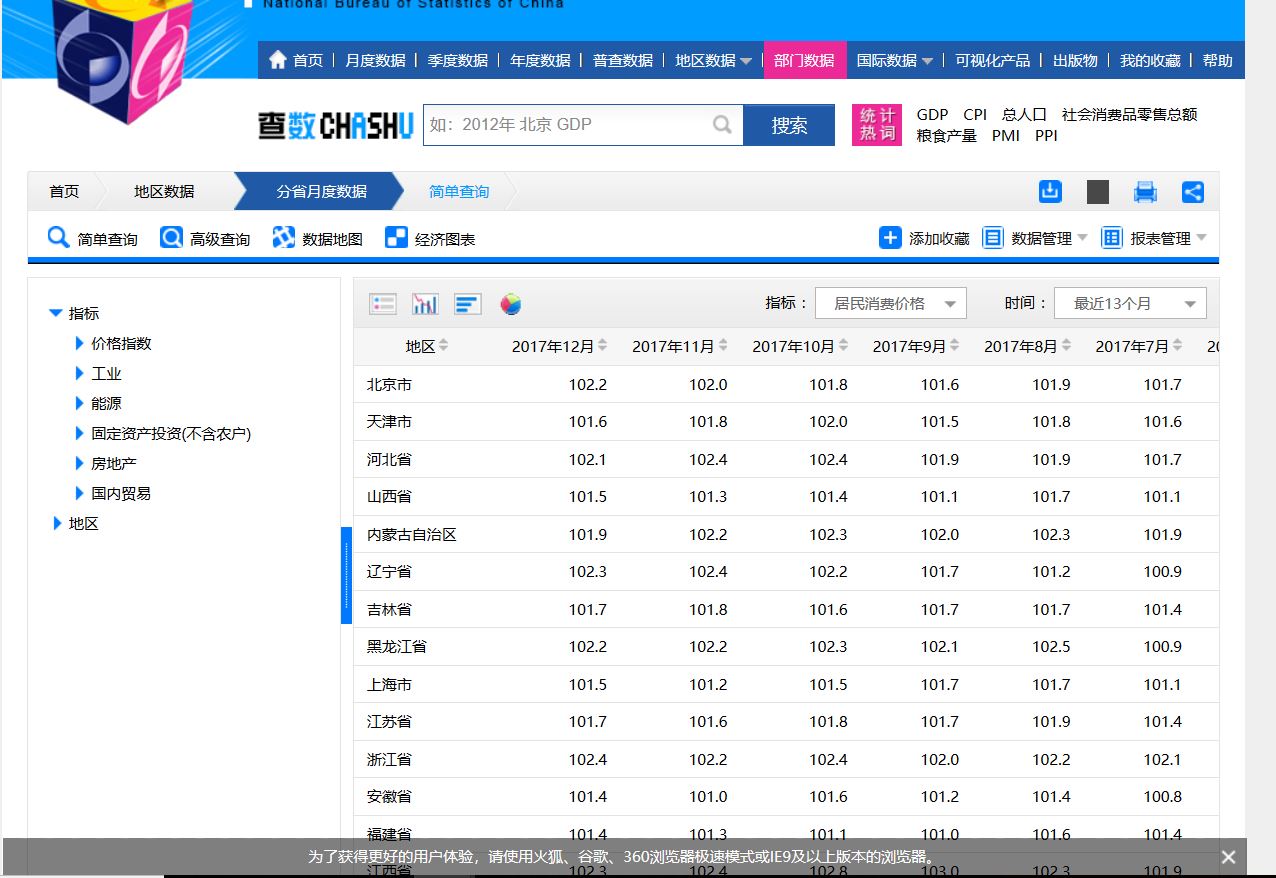
按F12,在按F5会出现3个请求url:
1:http://data.stats.gov.cn/easyquery.htm
2:http://data.stats.gov.cn/easyquery.htm?m=getOtherWds&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[]&k1=1516511359046
3:http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[{"wdcode":"zb","valuecode":"A01010101"}]&dfwds=[]&k1=1516511359249
这三个请求url都有用,但这个爬虫只用了两个:2,3
2的效果图:

3的效果图:

代码如下:
import urllib
from urllib import request
from json import loads
import pymssql # 发起请求
def getRequestBody(url):
return urllib.request.urlopen(url).read().decode('utf8')
# 获取指标类型
def getTarget(url):
body = getRequestBody(url)
print('body', body)
dicts = loads(body)
return dicts['returndata'] url = 'http://data.stats.gov.cn/easyquery.htm?m=getOtherWds&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[]&k1=1516507560165'
targetList_returnData = getTarget(url) # list
print('targetList_returnData',targetList_returnData)
for targetIndex_returnData in range(len(targetList_returnData)):
targetDict_returnData = dict(targetList_returnData[targetIndex_returnData]) # dict
targetList_nodes = targetDict_returnData['nodes'] # list
# 请求无法得到,但却有,只能硬来了
targetList_nodes.append({'code': 'A01010106', 'name': '交通和通信类居民消费价格指数(上年同月=100)', 'sort': '1'})
targetList_nodes.append({'code': 'A01010107', 'name': '教育文化和娱乐类居民消费价格指数(上年同月=100)', 'sort': '1'})
targetList_nodes.append({'code': 'A01010108', 'name': '医疗保健类居民消费价格指数(上年同月=100)', 'sort': '1'})
targetList_nodes.append({'code': 'A01010109', 'name': '其他用品和服务类居民消费价格指数(上年同月=100)', 'sort': '1'})
print('targetList_nodes',targetList_nodes)
for targetIndex_nodes in range(len(targetList_nodes)):
targetDict_nodes = dict(targetList_nodes[targetIndex_nodes]) # dict
print(targetDict_nodes['code'],targetDict_nodes['name'])
#
url1 = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=fsyd&rowcode=reg&colcode=sj' \
'&wds=[{"wdcode":"zb","valuecode":"%s"}]&dfwds=[]' %(targetDict_nodes['code'])
body1 = getRequestBody(url1)
print('body1',body1)
dictAll = loads(body1)
# 获取wdnodes键的name,以name当表名
dataList2 = dictAll['returndata']['wdnodes']
dataList2.pop()
name = dataList2[0]['nodes'][0]['cname']
if name.find('(') != -1:
name = name[:name.find('(')] + '2017'
print(name)
# 获取wdnodes键的地区
regionList = dataList2[1]['nodes']
# 获取datanodes键的内容
dataList1 = dictAll['returndata']['datanodes']
# 控制遍历,以删除2016年12月的数据,只要2017年的数据
index = 1
# 控制插入的地区
region = 0
# 存储具体数据
data = []
for dataIndex1 in range(len(dataList1)):
if index <= 12:
# 获取‘datanodes’的指数数据
data_f = dataList1[dataIndex1]['data']['data']
print(data_f,index)
data.append(data_f)
conn = pymssql.connect(host='localhost', user='sa', password='123456c', database='NationalData', charset='utf8')
cur = conn.cursor()
if index == 12:
print(regionList[region]['cname'])
sql ='''insert into {} values('{}',{},{},{},{},{},{},{},{},{},{},{},{});'''\
.format(name,regionList[region]['cname'],data[0],data[1],data[2],data[3],data[4],data[5],data[6],data[7],data[8],data[9],data[10],data[11])
region += 1
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
elif index == 13:
data = []
index = 0
index += 1
break
数据库有如下表:
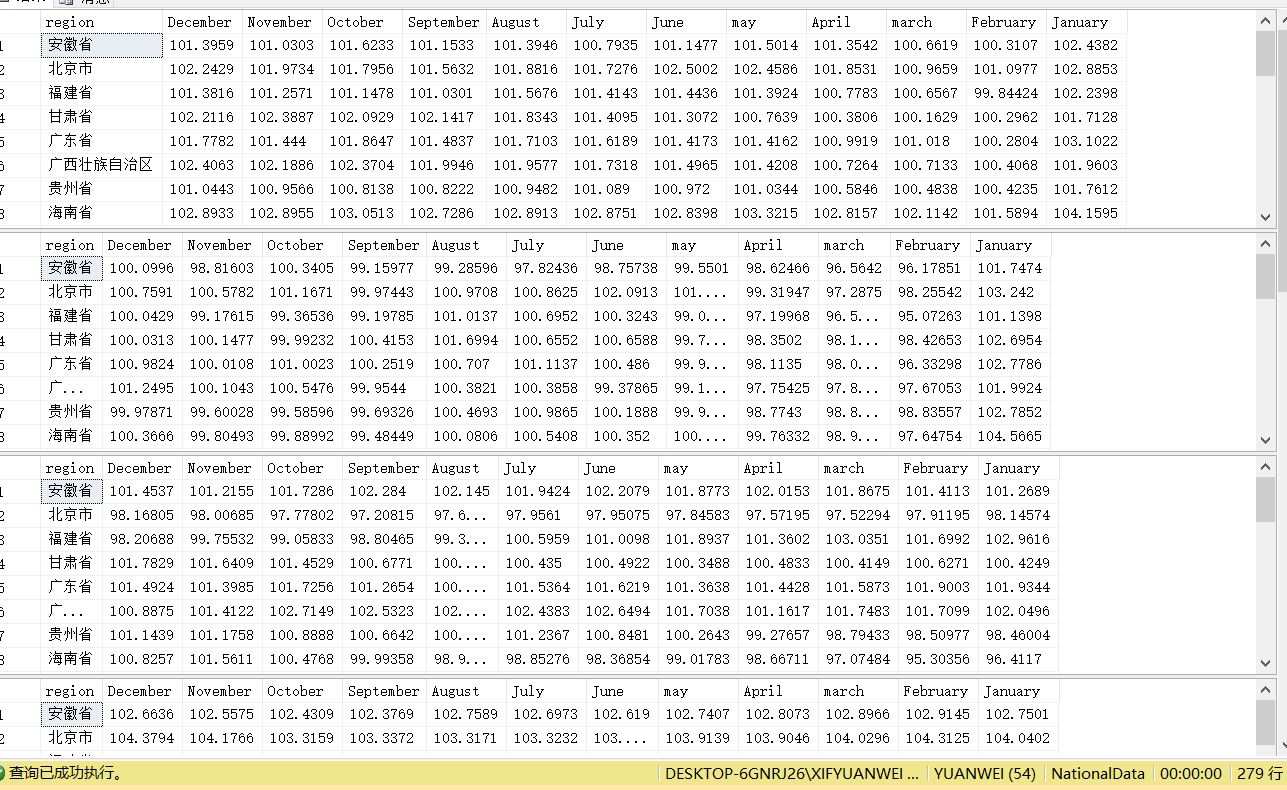
结果:
爬 NationalData ,虽然可以直接下,但还是爬一下吧的更多相关文章
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- 一个简单的爬取b站up下所有视频的所有评论信息的爬虫
心血来潮搞了一个简单的爬虫,主要是想知道某个人的b站账号,但是你知道,b站在搜索一个用户时,如果这个用户没有投过稿,是搜不到的,,,这时就只能想方法搞到对方的mid,,就是 space.bilibil ...
- MOJITO 发布一周,爬一波弹幕分析下
MOJITO 最近一直啥都没写,追个热点都赶不上热乎的,鄙视自己一下. 周董的新歌 「MOJITO」 发售(6 月 12 日的零点)至今大致过去了一周,翻开 B 站 MV 一看,播放量妥妥破千万,弹幕 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests.BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名.图片.名称.演 ...
- Scrapy 实现爬取多页数据 + 多层url数据爬取
项目需求:爬取https://www.4567tv.tv/frim/index1.html网站前三页的电影名称和电影的导演名称 项目分析:电影名称在初次发的url返回的response中可以获取,可以 ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
- Python反爬:利用js逆向和woff文件爬取猫眼电影评分信息
首先:看看运行结果效果如何! 1. 实现思路 小编基本实现思路如下: 利用js逆向模拟请求得到电影评分的页面(就是猫眼电影的评分信息并不是我们上述看到的那个页面上,应该它的实现是在一个页面上插入另外一 ...
随机推荐
- C++ 头文件系列(list)
简介 list实现的实际上是双向链表,所以叫它doubly-linked list也许更好. 因为实现的是双向链表,所以它有两个非常重要的性质: 双向 链表 双向 双向意味着----给定一个元素,我们 ...
- c语言库函数测试
1.函数名: abort功 能: 异常终止一个进程用 法: void abort(void);程序例: #include <stdio.h> #include <stdlib.h ...
- ES6常用语法
ECMAScript 6(以下简称ES6)是JavaScript语言的下一代标准.因为当前版本的ES6是在2015年发布的,所以又称ECMAScript 2015. 也就是说,ES6就是ES2015. ...
- bzoj 4199 [NOI2015]寿司晚宴
Description 为了庆祝 NOI 的成功开幕,主办方为大家准备了一场寿司晚宴.小 G 和小 W 作为参加 NOI 的选手,也被邀请参加了寿司晚宴. 在晚宴上,主办方为大家提供了 n−1 种不同 ...
- Hadoop版本选择
刚开始学习Hadoop时就曾经一直抱怨Hadoop的安装部署为什么这么麻烦,对于一个新手需要捯饬一天才能把分布式环境安装配置好.而对于一个自学Hadoop而周围又没人交流的菜鸟来说,我对Hadoop的 ...
- UWP Windows历史上最漂亮的UWP框架出炉!!!
UWP Windows历史上最漂亮的UWP框架出炉!!! 本框架基于微软的开源项目WTS开发,并在其基础上增加了FDS(流畅设计元素,高光.亚克力等).多语言系统.沉浸式体验(扩展内容到标题栏) 同时 ...
- 与apk签名有关的那些概念与命令
一.概念篇 1.消息摘要-Message Digest 消息摘要:在消息数据上,执行一个单向的hash函数,生成一个固定长度的hash值,这个Hash值就是消息摘要,也成为数字指纹. 消息摘要特点: ...
- 豹哥嵌入式讲堂:ARM开发之文件详解(2)- linker文件
大家好,我是豹哥,猎豹的豹,犀利哥的哥.今天豹哥给大家讲的是嵌入式开发里的linker文件. 在前一节课source文件详解里,豹哥给大家系统地介绍了source文件,source文件是嵌入式工程里典 ...
- hashlib 简单加密
import hashlib def md5(arg):#这是加密函数 md5_pwd = hashlib.md5(bytes('meac',encoding='utf-8')) md5_pwd.up ...
- ASP.NET Core MVC中的 [Required]与[BindRequired]
在开发ASP.NET Core MVC应用程序时,需要对控制器中的模型校验数据有效性,元数据注释(Data Annotations)是一个完美的解决方案. 元数据注释最典型例子是确保API的调用者提供 ...