从编辑距离、BK树到文本纠错
搜索引擎里有一个很重要的话题,就是文本纠错,主要有两种做法,一是从词典纠错,一是分析用户搜索日志,今天我们探讨使用基于词典的方式纠错,核心思想就是基于编辑距离,使用BK树。下面我们来逐一探讨:
编辑距离
1965年,俄国科学家Vladimir
Levenshtein给字符串相似度做出了一个明确的定义叫做Levenshtein距离,我们通常叫它“编辑距离”。
字符串A到B的编辑距离是指,只用插入、删除和替换三种操作,最少需要多少步可以把A变成B。例如,从FAME到GATE需要两步(两次替换),从GAME到ACM则需要三步(删除G和E再添加C)。Levenshtein给出了编辑距离的一般求法,就是大家都非常熟悉的经典动态规划问题。
class LevenshteinDistanceFunction {
private final boolean isCaseSensitive;
public LevenshteinDistanceFunction(boolean isCaseSensitive) {
this.isCaseSensitive = isCaseSensitive;
}
public int distance(CharSequence left, CharSequence right) {
int leftLength = left.length(), rightLength = right.length();
// special cases.
if (leftLength == 0)
return rightLength;
if (rightLength == 0)
return leftLength;
// Use the iterative matrix method.
int[] currentRow = new int[rightLength + 1];
int[] nextRow = new int[rightLength + 1];
// Fill first row with all edit counts.
for (int i = 0; i <= rightLength; i++)
currentRow[i] = i;
for (int i = 1; i <= leftLength; i++) {
nextRow[0] = i;
for(int j = 1; j <= rightLength; j++) {
int subDistance = currentRow[j - 1]; // Distance without insertions or deletions.
if (!charEquals(left.charAt(i - 1), right.charAt(j - 1), isCaseSensitive))
subDistance++; // Add one edit if letters are different.
nextRow[j] = Math.min(Math.min(nextRow[j - 1], currentRow[j]) + 1, subDistance);
}
// Swap rows, use last row for next row.
int[] t = currentRow;
currentRow = nextRow;
nextRow = t;
}
return currentRow[rightLength];
}
}
BK树
编辑距离的经典应用就是用于拼写检错,如果用户输入的词语不在词典中,自动从词典中找出编辑距离小于某个数n的单词,让用户选择正确的那一个,n通常取到2或者3。
这个问题的难点在于,怎样才能快速在字典里找出最相近的单词?可以像 使用贝叶斯做英文拼写检查(c#) 里是那样,通过单词自动修改一个单词,检查是否在词典里,这样有暴力破解的嫌疑,是否有更优雅的方案呢?
1973年,Burkhard和Keller提出的BK树有效地解决了这个问题。BK树的核心思想是:
令d(x,y)表示字符串x到y的Levenshtein距离,那么显然:
d(x,y) = 0 当且仅当 x=y (Levenshtein距离为0 <==> 字符串相等)
d(x,y) = d(y,x) (从x变到y的最少步数就是从y变到x的最少步数)
d(x,y) + d(y,z) >= d(x,z) (从x变到z所需的步数不会超过x先变成y再变成z的步数)
最后这一个性质叫做三角形不等式。就好像一个三角形一样,两边之和必然大于第三边。
BK建树
首先我们随便找一个单词作为根(比如GAME)。以后插入一个单词时首先计算单词与根的Levenshtein距离:如果这个距离值是该节点处头一次出现,建立一个新的儿子节点;否则沿着对应的边递归下去。例如,我们插入单词FAME,它与GAME的距离为1,于是新建一个儿子,连一条标号为1的边;下一次插入GAIN,算得它与GAME的距离为2,于是放在编号为2的边下。再下次我们插入GATE,它与GAME距离为1,于是沿着那条编号为1的边下去,递归地插入到FAME所在子树;GATE与FAME的距离为2,于是把GATE放在FAME节点下,边的编号为2。
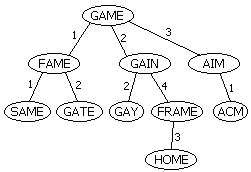
BK查询
如果我们需要返回与错误单词距离不超过n的单词,这个错误单词与树根所对应的单词距离为d,那么接下来我们只需要递归地考虑编号在d-n到d+n范围内的边所连接的子树。由于n通常很小,因此每次与某个节点进行比较时都可以排除很多子树。
可以通过下图(来自 超酷算法(1):BK树 (及个人理解))理解:
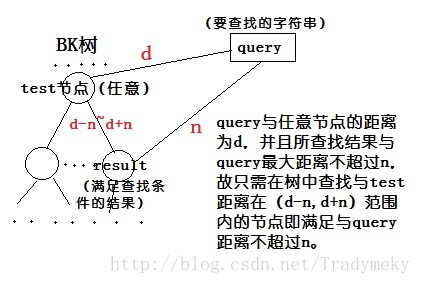
BK 实现
知道了原理实现就简单了,这里从github找一段代码
建树:
public boolean add(T t) {
if (t == null)
throw new NullPointerException();
if (rootNode == null) {
rootNode = new Node<>(t);
length = 1;
modCount++; // Modified tree by adding root.
return true;
}
Node<T> parentNode = rootNode;
Integer distance;
while ((distance = distanceFunction.distance(parentNode.item, t)) != 0
|| !t.equals(parentNode.item)) {
Node<T> childNode = parentNode.children.get(distance);
if (childNode == null) {
parentNode.children.put(distance, new Node<>(t));
length++;
modCount++; // Modified tree by adding a child.
return true;
}
parentNode = childNode;
}
return false;
}
查找:
public List<SearchResult<T>> search(T t, int radius) {
if (t == null)
return Collections.emptyList();
ArrayList<SearchResult<T>> searchResults = new ArrayList<>();
ArrayDeque<Node<T>> nextNodes = new ArrayDeque<>();
if (rootNode != null)
nextNodes.add(rootNode);
while(!nextNodes.isEmpty()) {
Node<T> nextNode = nextNodes.poll();
int distance = distanceFunction.distance(nextNode.item, t);
if (distance <= radius)
searchResults.add(new SearchResult<>(distance, nextNode.item));
int lowBound = Math.max(0, distance - radius), highBound = distance + radius;
for (Integer i = lowBound; i <= highBound; i++) {
if (nextNode.children.containsKey(i))
nextNodes.add(nextNode.children.get(i));
}
}
searchResults.trimToSize();
Collections.sort(searchResults);
return Collections.unmodifiableList(searchResults);
}
使用BK树做文本纠错
准备词典,18万的影视名称:
测试代码:
static void outputSearchResult( List<SearchResult<CharSequence>> results){
for(SearchResult<CharSequence> item : results){
System.out.println(item.item);
}
}
static void test(BKTree<CharSequence> tree,String word){
System.out.println(word+"的最相近结果:");
outputSearchResult(tree.search(word,Math.max(1,word.length()/4)));
}
public static void main(String[] args) {
BKTree<CharSequence> tree = new BKTree(DistanceFunctions.levenshteinDistance());
List<String> testStrings = FileUtil.readLine("./src/main/resources/act/name.txt");
System.out.println("词典条数:"+testStrings.size());
long startTime = System.currentTimeMillis();
for(String testStr: testStrings){
tree.add(testStr.replace(".",""));
}
System.out.println("建树耗时:"+(System.currentTimeMillis()-startTime)+"ms");
startTime = System.currentTimeMillis();
String[] testWords = new String[]{
"湄公河凶案",
"葫芦丝兄弟",
"少林足球"
};
for (String testWord: testWords){
test(tree,testWord);
}
System.out.println("测试耗时:"+(System.currentTimeMillis()-startTime)+"ms");
}
结果:
词典条数:18513
建树耗时:421ms
湄公河凶案的最相近结果:
湄公河大案
葫芦丝兄弟的最相近结果:
葫芦兄弟
少林足球的最相近结果:
少林足球
笑林足球
测试耗时:20ms
参考:
http://blog.csdn.net/tradymeky/article/details/40581547
https://github.com/sk-scd91/BKTree
https://www.cnblogs.com/data2value/p/5707973.html
作者:Jadepeng
出处:jqpeng的技术记事本--http://www.cnblogs.com/xiaoqi
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
从编辑距离、BK树到文本纠错的更多相关文章
- 超酷算法-BK树
前几天无意间遇到一个博客,觉得写得挺好的,自己之前的时候有个不好的习惯,那就是遇到了好资源第一反应就是收藏起来然后却很少再看!!这是坏习惯,要改!于是今天就开始通读了,读的第二篇是BK树.觉得有点意思 ...
- 调用百度API进行文本纠错
毕设做的是文本纠错方面,然后今天进组见研究生导师 .老师对我做的东西蛮感兴趣.然后介绍自己现在做的一些项目,其中有个模块需要有用到文本纠错功能. 要求1:有多人同时在线编辑文档,然后文档功能有类似Wo ...
- 拼写纠错的利器,BK树算法
BK树或者称为Burkhard-Keller树,是一种基于树的数据结构,被设计于快速查找近似字符串匹配,比方说拼写纠错,或模糊查找,当搜索”aeek”时能返回”seek”和”peek”. 本文首先剖析 ...
- 【.net 深呼吸】将目录树转化为文本
大伙都知道,文件系统是树形结构的,有时候我们会想到把目录的层次结构变为纯文本形式,就像这样: ├─Windows-universal-samples-master │ ├─Samples │ │ ├─ ...
- HDU 4323 Magic Number(编辑距离DP)
http://acm.hdu.edu.cn/showproblem.php?pid=4323 题意: 给出n个串和m次询问,每个询问给出一个串和改变次数上限,在不超过这个上限的情况下,n个串中有多少个 ...
- paddle&蜜度 文本智能较对大赛经验分享(17/685)
引言 我之前参加了一个中文文本智能校对大赛,拿了17名,虽然没什么奖金但好歹也是自己solo拿的第一个比较好的名次吧,期间也学到了一些BERT应用的新视角和新的预训练方法,感觉还挺有趣的,所以在这里记 ...
- 后缀树 & 后缀数组
后缀树: 字符串匹配算法一般都分为两个步骤,一预处理,二匹配. KMP和AC自动机都是对模式串进行预处理,后缀树和后缀数组则是对文本串进行预处理. 后缀树的性质: 存储所有 n(n-1)/2 个后缀需 ...
- ztree树的模糊搜索功能
在做机场项目的时候,业务为一个input框,点击的时候出现一个下拉树,这个下拉树是所有的设备,由于设备太多,加上分了区域,为了更好的用户体验,设计一个模糊搜索的功能,方便用户进行选择 具体实现过程如下 ...
- fp-growth树创建代码及详细注释
事务集过滤重排: #FP树节点结构 class treeNode: def __init__(self,nameValue,numOccur,parentNode): self.name=nameVa ...
随机推荐
- 第六章 JDBC
第一章 JDBC 一.JDBC的简介 1.什么是JDBC JDBC是java数据库连接(java database connectivity)技术的简称,它充当了java应用程序与各个不同数据库之间进 ...
- sql server 2008 18456错误
来自:http://blog.csdn.net/qishuangquan/article/details/6024767 百度搜18456错误几乎只能搜到一篇文章,并不是说结果条数,而是所有的文章都是 ...
- 使用phpExcel导出excel时,报500错
在自己本地导出excel没有问题,但是放到服务器出现500的错误! 解决方法:查看控制器引用的header文件,是否包含空格,如下: header('Pragma:public'); ...
- 前端工程化grunt
1.grunt是什么? grunt是基于nodejs的前端构建工具.grunt用于解决前端开发的工程问题. 2.安装nodejs Grunt和所有grunt插件都是基于nodejs来运行的. 安装了n ...
- C++大数精度计算(带小数点)
转: (原出处不可考,若有侵权,请联系我立即删除) 头文件: // WTNumber.h: interface for the CWTNumber class. // //////////////// ...
- UVa12100,Printer Queue
水题,1A过的 数据才100,o(n^3)都能过,感觉用优先队列来做挺麻烦的,直接暴力就可以了,模拟的队列,没用stl #include <iostream> #include <c ...
- Hi Java!!!---来自十八岁的程序员随笔
9月23日我正式加入了程序员的行列,在哪以前我都不知道程序员到底是干嘛的,电脑对于我来说也不过是打打游戏,玩玩QQ.转眼间一个月了,我真正的喜欢上了这门行业,当自己写出一个程序的时候特别有成就感,哪怕 ...
- 【转】循环冗余校验(CRC)算法入门引导
原文地址:循环冗余校验(CRC)算法入门引导 参考地址:https://en.wikipedia.org/wiki/Computation_of_cyclic_redundancy_checks#Re ...
- tp5上传图片添加永久素材到微信公众号
$file = request()->file('image');if(!$file){ $res['status'] = false; $res['msg'] = '必须上传文件'; retu ...
- SpringMVC 异常的处理
Spring MVC处理异常有3种方式: (1)使用Spring MVC提供的简单异常处理器SimpleMappingExceptionResolver: (2)实现Spring的异常处理接口Hand ...