C#集合--数组
Array类是所有一维和多维数组的隐式基类,同时也是实现标准集合接口的最基本的类型。Array类实现了类型统一,因此它为所有数组提供了一组通用的方法,不论这些数组元素的类型,这些通用的方法均适用。
正因为数组如此重要,所以C#为声明数组和初始化数组提供了明确的语法。在使用C#语法声明一个数组时,CLR隐式地构建Array类--合成一个伪类型以匹配数组的维数和数组元素的类型。而且这个伪类型实现了generic集合接口,比如IList<string>接口。
CLR在创建数组类型实例时会做特殊处理--在内存中为数组分配连续的空间。这就使得索引数组非常高效,但这却阻止了对数组的修改或调正数组大小。
Array类实现了IList<T>接口和IList接口。Array类显示地实现了IList<T>接口,这是为了保证接口的完整性。但是在固定长度集合比如数组上调用IList<T>接口的Add或Remove方法时,会抛出异常(因为数组实例一旦声明之后,就不能更改数组的长度)。Array类提供了一个静态的Resize方法,使用这个方法创建一个新的数组实例,然后复制当前数组的元素到新的实例。此外,在程序中,当在任何地方引用一个数组都会执行最原始版本的数组实例。因此如果希望集合大小可以调整,那么你最好使用List<T>类。
数组元素可以是值类型也可以是引用类型。值类型数组元素直接存在数组中,比如包含3个整数的数组会占用24个字节的连续内存。而引用类型的数组元素,占用的空间和一个引用占用的空间一样(32位环境中4个字节,64为环境中8个字节)。我们先来看下面的代码:
int[] numbers =new int[3];
numbers[0] =1;
numbers[1] = 7; StringBuilder[] builders = new StringBuilder[5];
builders[0] = new StringBuilder("Builder1");
builders[1] = new StringBuilder("Builder2");
builders[2] = new StringBuilder("Builder3");
对应的内存分配变化如下面几张图所示:
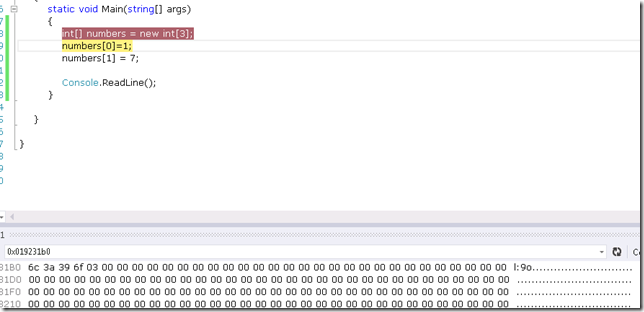
执行完int[] numbers=new int[3]之后,在内存中分配了8×3=24个字节,每个字节都为0。
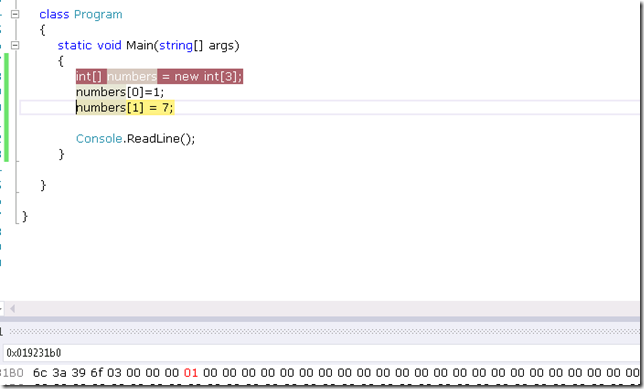
执行完numbers[0]=1之后,数组声明后的第一个8字节变为00 00 00 01。
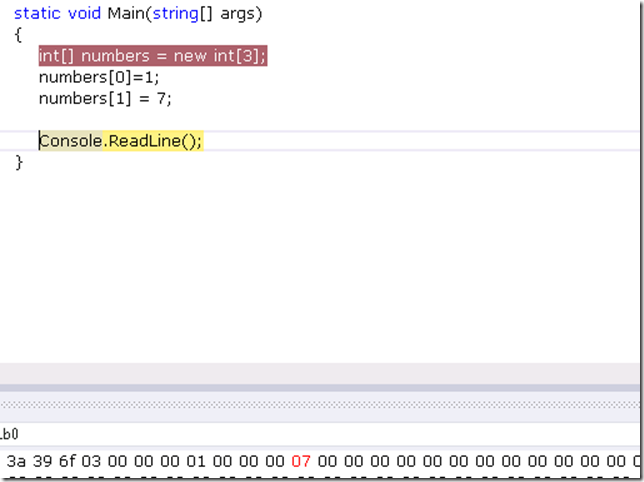
同样地,执行完numbers[1]=7之后,第二段8个字节变为00 00 00 07。
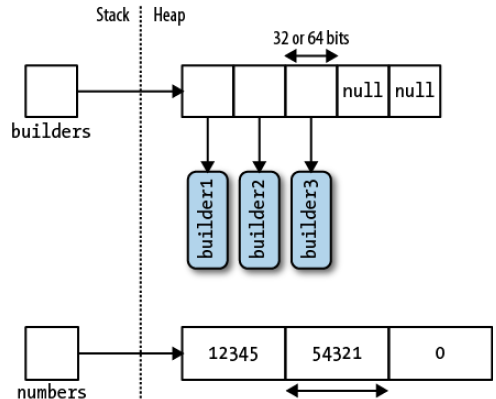
对应引用类型的数组,我们用一张图来说明内存分配:

看起来分复杂,其实内存分配示意图如下
通过Clone方法可以克隆一个数组,比如arrayB = arrayA.Clone()。但是,克隆数组执行浅拷贝,也就是说数组自己包含的那部分内容才会被克隆。简单说,如果数组包含的是值类型对象,那么克隆了这些对象的值。而数组的子元素是引用类型,那么仅仅克隆引用类型的地址。
StringBuilder[] builders2 = builders;
ShtringBuilder[] shallowClone = (StringBuilder[])builders.Clone();
与之对应的内存分配示意图:
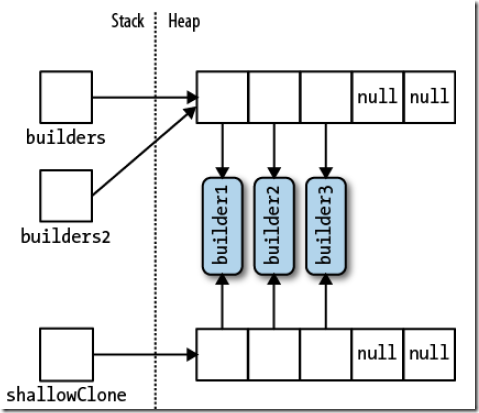
如果需要执行深拷贝,即克隆引用类型的子对象;那么你需要遍历数组并手动的克隆每个数组元素。深克隆规则也适用于.NET其他集合类型。
尽管数组在设计时,主要使用32位的索引,它也在一定程度上支持64位索引,这需要使用那些既接收Int32又接收Int64类型参数的方法。这些重载方法在实际中并没有意义,因为CLR不允许任何对象--包括数组在内--的大小超过2G(无论32位的系统还是64位的系统)
构造数组和索引数组
创建数组和索引数组的最简单方式就是通过C#语言的构建器
Int[] myArray={1,2,3};
int first=myArray[0];
int last = myArray[myArray.Length-1];
或者,你可以通过调用Array.CreateInstance方法动态地创建一个数组实例。你可以通过这种方式指定数组元素的类型和数组的维度。而GetValue和SetValue方法允许你访问动态创建的数组实例的元素。
Array a = Arrat.CreateInstance(typeof(string), 2);
a.SetValue('hi", 0);
a.SetValue("there",1);
string s = (string)a.getValue(0); string[] cSharpArray = (string[])a;
string s2 = cSharpArray[0];
动态创建的零索引的数组可以转换为一个匹配或兼容的C#数组。比如,如果Apple是Fruit的子类,那么Apple[]可以转换成Fruit[]。这也是为什么object[]没有作为统一的数组类型,而是使用Array类;答案在于object[]不仅与多维数组不兼容,而且还与值类型数组不兼容。因此我们使用Array类作为统一的数组类型。
GetValue和SetValue对编译器生成的数组也起作用,若想编写一个方法处理任何类型的数组和任意维度的数组,那么这两个方法非常有用。对于多维数组,这两个方法可以把一个数组当作索引参数。
public object GetValue(params int[] indices)
public void SetValue(object value, params int[] indices)
下面的方法在屏幕打印任意数组的第一个元素,无论数组的维度
void WriteFirstValue (Array a)
{
Console.Write (a.Rank + "-dimensional; "); int[] indexers = new int[a.Rank];
Console.WriteLine ("First value is " + a.GetValue (indexers));
}
void Demo()
{
int[] oneD = { 1, 2, 3 };
int[,] twoD = { {5,6}, {8,9} };
WriteFirstValue (oneD); // 1-dimensional; first value is 1
WriteFirstValue (twoD); // 2-dimensional; first value is 5
}
在使用SetValue方法时,如果元素与数组类型不兼容,那么会抛出异常。
无论采取哪种方式实例化一个数组之后,那么数组元素自动初始化了。对于引用类型元素的数组而言,初始化数组元素就是把null值赋给这些数组元素;而对于值类型数组元素,那么会把值类型的默认值赋给数组元素。此外,调用Array类的Clear方法也可以完成同样的功能。Clear方法不会影响数组大小。这和常见的Clear方法(比如ICollection<T>.Clear方法)不一样,常见的Clear方法会清除集合的所有元素。
遍历数组
通过foreach语句,可以非常方便地遍历数组:
int[] myArray = { 1, 2, 3};
foreach (int val in myArray)
Console.WriteLine (val);
你还可以使用Array.ForEach方法来遍历数组
public static void ForEach<T> (T[] array, Action<T> action);
该方法使用Action代理,此代理方法的签名是(接收一个参数,不返回任何值):
public delegate void Action<T> (T obj);
下面的代码显示了如何使用ForEach方法
Array.ForEach (new[] { 1, 2, 3 }, Console.WriteLine);
你可能会很好奇Array.ForEach是如何执行的,它就是这么执行的
public static void ForEach<T>(T[] array, Action<T> action) {
if( array == null) {
throw new ArgumentNullException("array");
}
if( action == null) {
throw new ArgumentNullException("action");
}
Contract.EndContractBlock();
for(int i = 0 ; i < array.Length; i++) {
action(array[i]);
}
}
在内部执行for循环,并调用Action代理。在上面的实例中,我们调用Console.WriteLine方法,所以可以在屏幕上输出1,2,3。
获取数组的长度和维度
Array提供了下列方法或属性以获取数组的长度和数组的维度:
public int GetLength (int dimension);
public long GetLongLength (int dimension); public int Length { get; }
public long LongLength { get; } public int GetLowerBound (int dimension);
public int GetUpperBound (int dimension); public int Rank { get; }
GetLength和GetLongLength返回指定维度的长度(0表示一维数组),Length和LongLength返回数组中所有元素的总数(包含了所有维度)。
GetLowerBound和GetUpperBound对于多维数组非常有用。GetUpperBound返回的结果等于指定维度的GetLowerBound+指定维度的GetLength
搜索数组
Array类对外提供了一系列方法,以在一个维度中查找元素。比如:
- BinarySearch方法:在一个排序后的数组中快速找到指定元素;
- IndexOf/LastIndex方法:在未排序的数组中搜索指定元素;
- Find/FindLast/FindIndex/FindLastIndex/FindAll/Exists/TrueForAll方法:根据指定的Predicated<T>(代理)在未排序的数组中搜索一个或多个元素。
如果没有找到指定的值,数组的这些搜索方法不会抛出异常。相反,搜索方法返回-1(假定数组的索引都是以0开始),或者返回generic类型的默认值(int返回0,string返回null)。
二进制搜索速度很快,但是它仅仅适用于排序后的数组,而且数组的元素是根据大小排序,而不是根据相等性排序。正因为如此,所以二进制搜索方法可以接收IComparer或IComparer<T>对象以对元素进行排序。传入的IComparer或IComparer<T>对象必须和当前数组所使用的排序比较器一致。如果没有提供比较器参数,那么数组会使用默认的排序算法。
IndexOf和LastIndexOf方法对数组进行简单的遍历,然后根据指定的值返回第一个(或最后一个)元素的位置。
以断定为基础(predicate-based)的搜索方法接受一个方法代理或lamdba表达式判断元素是否满足“匹配”。一个断定(predicate)是一个简单的代理,该代理接收一个对象并返回bool值:
public delegate bool Precicate<T>(T object);
下面的例子中,我们搜索字符数组中包含字母A的字符:
static void Main(string[] args)
{
string[] names = { "Rodney", "Jack", "Jill" };
string match = Array.Find(names, ContainsA);
Console.WriteLine(match); Console.ReadLine();
} static bool ContainsA(string name)
{
return name.Contains("a");
}
上面的代码可以简化为:
static void Main(string[] args)
{
string[] names = { "Rodney", "Jack", "Jill" };
string match = Array.Find(names, delegate(string name) { return name.Contains("a"); });
Console.WriteLine(match); Console.ReadLine();
}
如果使用lamdba表达式,那么代码还可以更简洁:
static void Main(string[] args)
{
string[] names = { "Rodney", "Jack", "Jill" };
string match = Array.Find(names, name=>name.Contains("a"));
Console.WriteLine(match); Console.ReadLine();
}
FindAll方法则从数组中返回满足断言(predicate)的所有元素。实际上,该方法等同于Enumerable.Where方法,只不过数组的FindAll是从数组中返回匹配的元素,而Where方法从IEnumerable<T>中返回。
如果数组成员满足指定的断言(predicate),那么Exists方法返回True,该方法等同于Enumerable.Any方法。
所以数组的所有成员都满足指定的断言(predicate),那么TrueForAll方法返回True,该方法等同于Enumerable.All方法。
对数组排序
数组有下列自带的排序方法:
public static void Sort<T>(T[] array);
public static void Sort(Array array);
public static void Sort(TKey, TValue)(TKey[] keys, TValue[] items);
public static void Sort(Array keys[], Array items);
上面的方法都有重载的版本,重载方法接受下面这些参数:
- int index,从指定索引位置开始排序
- int length,从指定索引位置开始,需要排序的元素的个数
- ICompare<T> comparer,用于排序决策的对象
- Comparison<T> comparison,用于排序决策的代理
下面的代码演示了如何实现一个简单的排序:
static void Main(string[] args)
{
int[] numbers = { 3,2,1};
Array.Sort(numbers);
foreach (int number in numbers)
Console.WriteLine(number); Console.ReadLine();
}
Sort方法还可以接收两个两个数组类型的参数,然后基于第一个数组的排序结果,对每个数组的元素进行排序。下面的例子中,数字数组和字符数组都按照数字数组的顺序进行排序。
static void Main(string[] args)
{
int[] numbers = { 3,2,1};
string[] names = { "C", "B", "E" };
Array.Sort(numbers, names);
foreach (int number in numbers)
Console.WriteLine(number); // 1, 2,3 foreach (string name in names)
Console.WriteLine(name); // E, B, C Console.ReadLine();
}
Array.Sort方法要求数组实现了IComparer接口。这就是说C#的大多数类型都可以排序。如果数组元素不能进行比较,或你希望重载默认的排序,那么你需要在调用Sort方法时,需提供自定义的Comparison。所以自定义排序算法有下面两种实现方式:
1)通过一个帮助对象实现IComparer或IComparer<T>接口
public static void Sort(Array array, IComparer comparer)
public static void Sort<T>(T[] array, System.Collections.Generic.IComparer<T> comparer)
2)通过Comparison接口
public static void Sort<T>(T[] array, Comparison<T> comparison)
Comparison代理遵循IComparer<T>.CompareTo语法:
public delegate int Comparison<T> (T x, T y);
如果x的位置在y之前,那么返回-1;如果x在y之后,返回1,如果位置相同,那么返回0。
我们来看一下Array的Sort<T>(T[]array, Comparison<T> comparison)方法的源代码:
public static void Sort<T>(T[] array, Comparison<T> comparison) {
......
IComparer<T> comparer = new FunctorComparer<T>(comparison);
Array.Sort(array, comparer);
}
由此,可内部,Comparison<T>转换成IComparer<T>,因此在实际中,需要实现自定义排序时,如果需要考虑性能,那么推荐使用第一种方式。此外,我们分析Sort<T>(T[] array, System.Collections.Generic.IComparer<T> comparer)的源代码,
public static void Sort<T>(T[] array, int index, int length, System.Collections.Generic.IComparer<T> comparer)
{
... if (length > 1)
{
if (comparer == null || comparer == Comparer<T>.Default)
{
if (TrySZSort(array, null, index, index + length - 1))
{
return;
}
} ArraySortHelper<T>.Default.Sort(array, index, length, comparer);
}
}
我们可以看到,首先尝试调用调用非托管代码的Sort方法,如果成功排序,直接返回。否则调用非托管代码(C#的ArraySortHelper)的Sort方法进行排序:
public void Sort(T[] keys, int index, int length, IComparer<T> comparer)
{
…
try
{
if (comparer == null)
{
comparer = Comparer<T>.Default;
} if (BinaryCompatibility.TargetsAtLeast_Desktop_V4_5)
{
IntrospectiveSort(keys, index, length, comparer);
}
else
{
DepthLimitedQuickSort(keys, index, length + index - 1, comparer, IntrospectiveSortUtilities.QuickSortDepthThreshold);
}
}
catch (IndexOutOfRangeException)
{
IntrospectiveSortUtilities.ThrowOrIgnoreBadComparer(comparer);
}
catch (Exception e)
{
throw new InvalidOperationException(Environment.GetResourceString("InvalidOperation_IComparerFailed"), e);
}
}
如果有兴趣,可以继续分析IntrospectiveSort方法和DepthLimitedQuickSort,不过MSDN已经给出了总结,

意识是说,排序算法有三种:
- 如果分区大小小于16,那么使用插入排序算法
- 如果分区的大小超过2*LogN,N是数组的范围,那么使用堆排序
- 其他情况,则使用快排
反转数组的元素
使用下面的方法,可以反转数组的所有元素或部分元素
public static void Reverse (Array array);
public static void Reverse (Array array, int index, int length);
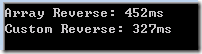
如果你在乎性能,那么请不要直接调用Array的Reverse方法,而是应该创建一个自定义的RerverseComparer。比如下面的例子中,调用Array.Reverse和CustomReverse在我的电脑上两者的性能高差距为20%左右
class Program
{
static void Main(string[] args)
{
int seeds = 100000; Staff[] staffs = new Staff[seeds];
Random r = new Random();
for (int i = 0; i < seeds; i++)
staffs[i] = new Staff { StaffNo = r.Next(1, seeds).ToString() }; ArrayReverse(staffs);
CustomReverse(staffs); Console.ReadLine();
} static void ArrayReverse(Staff[] staffs)
{
DateTime t1 = DateTime.Now;
Array.Sort(staffs);
Array.Reverse(staffs);
DateTime t2 = DateTime.Now;
Console.WriteLine("Array Reverse: " + (t2 - t1).Milliseconds + "ms");
} static void CustomReverse(Staff[] staffs)
{
DateTime t1 = DateTime.Now;
Array.Sort(staffs, new StaffComparer());
DateTime t2 = DateTime.Now;
Console.WriteLine("Custom Reverse: " + (t2 - t1).Milliseconds + "ms");
} internal class Staff : IComparable
{
public string StaffNo { get; set; }
public string Name { get; set; } public int CompareTo(object obj)
{
Staff x = obj as Staff; return this.StaffNo.CompareTo(x.StaffNo);
}
} internal class StaffComparer : IComparer<Staff>
{
public int Compare(Staff x, Staff y)
{
return y.StaffNo.CompareTo(x.StaffNo);
}
}
}
执行结果:
复制数组
Array提供了四个方法以实现浅拷贝:Clone,CopyTo,Copy和ConstrainedCopy。前两个方法是实例方法,后面两个是静态方法。
Clone方法返回一个全新的(浅拷贝)数组 。CopyTo和Copy方法复制数组的连续子集。复制一个多维矩形数组需要你的多维索引映射到一个线性索引。比如,一个3×3的数组position,那么postion[1,1]对应的线性索引为1*3+1=4。原数组和目标数组的范围可以交换,不会带来任何问题。
ConstrainedCopy执行原子操作,如果所要求的元素不能全部成功地复制,那么操作回滚。
Array还提供AsReadOnly方法,它返回一个包装器,以防止数组元素的值被更改。
最后,Clone方法是由外部的非托管代码实现
protected extern Object MemberwiseClone()
同样地,Copy,CopyTo, ConstraintedCopy也都是调用外部实现
internal static extern void Copy(Array sourceArray, int sourceIndex, Array destinationArray, int destinationIndex, int length, bool reliable);
转换数组和缩减数组大小
Array.ConvertAll创建并返回一个类型为TOutput的新数组,调用Converter代理以复制元素到新的数组中。Converter的定义如下:
public delegate TOutput Converter<TInput,TOutput>(TInput input)
下面的代码展示了如果把一个浮点数数组转换成int数组
float[] reals = { 1.3f, 1.5f, 1.8f };
int[] wholes = Array.ConvertAll(reals, f => Convert.ToInt32(f));
foreach (int a in wholes)
Console.WriteLine(a); //->1,2,2
Resize方法创建一个新数组,然后复制元素到新数组,然后返回新数组;原数组不发生改变。
C#集合--数组的更多相关文章
- ruby pluck用法,可以快速从数据库获取 对象的 指定字段的集合数组
可以快速从数据库获取 对象的 指定字段的集合数组 比如有一个users表,要等到user的id数组: select id from users where age > 20; 要实现在如上sql ...
- 集合 数组 定义 转换 遍历 Arrays API MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- jquery遍历集合&数组&标签
jquery遍历集合&数组的两种方式 CreateTime--2017年4月24日08:31:49Author:Marydon 方法一: $(function(){ $("inp ...
- Delphi基本类型--枚举 子界 集合 数组
[plain] view plain copy <strong>根据枚举定义集合 </strong> TMyColor = (mcBlue, mcRed); TMyColorS ...
- 【Scala篇】--Scala中集合数组,list,set,map,元祖
一.前述 Scala在常用的集合的类别有数组,List,Set,Map,元祖. 二.具体实现 数组 1.创建数组 new Array[Int](10) 赋值:arr(0) = xxx Array[ ...
- SpringMVC,SpringBoot使用ajax传递对象集合/数组到后台
假设有一个bean名叫TestPOJO. 1.使用ajax从前台传递一个对象数组/集合到后台. 前台ajax写法: var testPOJO=new Array(); //这里组装testPOJO数组 ...
- Ruby 集合数组常用遍历方法
迭代器简介 先简单介绍一下迭代器. 1.一个Ruby迭代器就是一个简单的能接收代码块的方法(比如each这个方法就是一个迭代器).特征:如果一个方法里包含了yield调用,那这个方法肯定是迭代器: 2 ...
- SpringMVC方法传递集合数组
背景:实体集合作为参数 数据准备: 1.实体类 class A {private int id; private String name; } 2.集合json字符串 [{"id&quo ...
- 集合数组与String的互转
1.集合转成数组: 转之前集合里面存的什么类型的数据,就new什么类(特别:存的是基本数据的封装类,就要new他的封装类) 例如: 1.1集合: ArrayList<Character> ...
随机推荐
- C++混合编程之idlcpp教程Lua篇(2)
在上一篇 C++混合编程之idlcpp教程(一) 中介绍了 idlcpp 工具的使用.现在对 idlcpp 所带的示例教程进行讲解,这里针对的 Lua 语言的例子.首先看第一个示例程序 LuaTuto ...
- vimium: 浏览器神器
chrome firefox 都有 vimium (firefox 中为vimfx), 快捷键也差不多 下边是chrome中快捷键示意图: G = shift + g (其他同理) c+e = ctr ...
- 《Linux内核设计与实现》读书笔记(十三)- 虚拟文件系统
虚拟文件系统(VFS)是linux内核和具体I/O设备之间的封装的一层共通访问接口,通过这层接口,linux内核可以以同一的方式访问各种I/O设备. 虚拟文件系统本身是linux内核的一部分,是纯软件 ...
- 团队项目--站立会议 DAY4
小组名称:D&M 参会人员:张靖颜,钟灵毓秀,何玥,赵莹,王梓萱 项目进展: 1.张靖颜:筛选完元素后,把昨天优化完的再进行测试,进行进一步的检验.对于钟灵毓秀和赵莹同学编写的代码进行进一步审 ...
- Html5 学习系列(五)Canvas绘图API快速入门(2)
Canvas绘图API Demos 上一篇文章中,笔者已经给大家演示了怎么快速用Canvas的API绘制一个矩形出来.接下里我会在本文中给各位介绍Canvas的其他API:绘制线条.绘制椭圆.绘制图片 ...
- [C++] socket - 5 [API事件对象实现线程同步]
/*API事件对象实现线程同步*/ #include<windows.h> #include<stdio.h> DWORD WINAPI myfun1(LPVOID lpPar ...
- ActiveMQ第三弹:在Spring中使用内置的Message Broker
在上个例子中我们演示了如何使用Spring JMS来向ActiveMQ发送消息和接收消息.但是这个例子需要先从控制台使用ActiveMQ提供的命令行功能启动一个Message Broker,然后才能运 ...
- atitit...触发器机制 ltrigger mechanism sumup .的总结O8f
atitit...触发器机制 ltrigger mechanism sumup .的总结O8f 1. 触发器的类型 1 2. 实现原理 1 3. After触发器 Vs Instead Of触发器 ...
- atitit.查看预编译sql问号 本质and原理and查看原生sql语句
atitit.查看预编译sql问号 本质and原理and查看原生sql语句 1. 预编译原理. 1 2. preparedStatement 有三大优点: 1 3. How to look gene ...
- java异常处理——题
1.建立exception包,编写TestException.java程序,主方法中有以下代码,确定其中可能出现的异常,进行捕获处理. public class YiChang { public st ...