Hash与Map
Hash与Map
面试时经常被问到,什么是Hash?什么是Map?
答:hash采用hash表存储,map一般采用红黑树(RB Tree)实现。因此其memory数据结构是不一样的,而且他们的时间复杂度也是不同的,hash为o(1),map为o(logN)。
什么是Hash
Hash,也可以称为“散列”,,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。这是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出(也就是多对一的关系)。
哈希表的构造
在所有的线性数据结构中,数组的定位速度最快,因为它可通过数组下标直接定位到相应的数组空间,就不需要一个个查找。而哈希表就是利用数组这个能够快速定位数据的结构解决以上的问题的。
"数组可以通过下标直接定位到相应的空间”,对就是这句,哈希表的做法其实很简单,就是把Key通过一 个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标 的数组空间里,而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分 利用到数组的定位性能进行数据定位。
例如: 如果一个hash函数是这样的,
index = value % 5;
如下图中,左边为一个长度为5的指针数据,下标从0到4,每个数据元素都是一个链表的头指针,这样通过value%5就形成了一种一对多的关系,缩小了查找的范围。
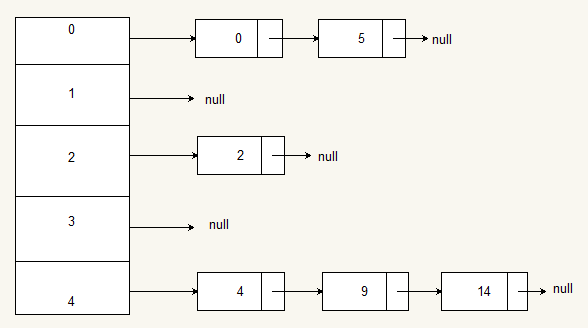
虽然我们不希望发生冲突(同一个key有多个value),但实际上发生冲突的可能性仍是存在的。当关键字值域远大于哈希表的长度,而且事先并不知道关键字的具体取值时。冲突就难免会发生。另外,当关键字的实际取值大于哈希表的长度时,而且表中已装满了记录,如果插入一个新记录,不仅发生冲突,而且还会发生溢出。因此,处理冲突和溢出是哈希技术中的两个重要问题。一般有开放地址法、链地址法。
看到了一个叫做One-Way Hash的算法(来自暴雪的hash算法)。
如果说两个不同的字符串经过一个哈希算法得到的入口点一致有可能,但用三个不同的哈希算法算出的入口点都一致,那几乎可以肯定是不可能的事了,这个几率是1:18889465931478580854784,大概是10的 22.3次方分之一,对一个游戏程序来说足够安全了。第一个hash值作为用来定位,另外两个hash值用来检测。
/*********************************StringHash.h*********************************/ #pragma once #define MAXTABLELEN 1024 // 默认哈希索引表大小
//////////////////////////////////////////////////////////////////////////
// 哈希索引表定义
typedef struct _HASHTABLE
{
long nHashA;
long nHashB;
bool bExists;
}HASHTABLE, *PHASHTABLE ; class StringHash
{
public:
StringHash(const long nTableLength = MAXTABLELEN);
~StringHash(void);
private:
unsigned long cryptTable[0x500];
unsigned long m_tablelength; // 哈希索引表长度
HASHTABLE *m_HashIndexTable;
private:
void InitCryptTable(); // 对哈希索引表预处理
unsigned long HashString(const string& lpszString, unsigned long dwHashType); // 求取哈希值
public:
bool Hash(string url);
unsigned long Hashed(string url); // 检测url是否被hash过
}; /*********************************StringHash.cpp*********************************/ #include "StdAfx.h"
#include "StringHash.h" StringHash::StringHash(const long nTableLength /*= MAXTABLELEN*/)
{
InitCryptTable();
m_tablelength = nTableLength;
//初始化hash表
m_HashIndexTable = new HASHTABLE[nTableLength];
for ( int i = ; i < nTableLength; i++ )
{
m_HashIndexTable[i].nHashA = -;
m_HashIndexTable[i].nHashB = -;
m_HashIndexTable[i].bExists = false;
}
} StringHash::~StringHash(void)
{
//清理内存
if ( NULL != m_HashIndexTable )
{
delete []m_HashIndexTable;
m_HashIndexTable = NULL;
m_tablelength = ;
}
} /************************************************************************/
/*函数名:InitCryptTable
/*功 能:对哈希索引表预处理
/*返回值:无
/************************************************************************/
void StringHash::InitCryptTable()
{
unsigned long seed = 0x00100001, index1 = , index2 = , i; for( index1 = ; index1 < 0x100; index1++ )
{
for( index2 = index1, i = ; i < ; i++, index2 += 0x100 )
{
unsigned long temp1, temp2;
seed = (seed * + ) % 0x2AAAAB;
temp1 = (seed & 0xFFFF) << 0x10;
seed = (seed * + ) % 0x2AAAAB;
temp2 = (seed & 0xFFFF);
cryptTable[index2] = ( temp1 | temp2 );
}
}
} /************************************************************************/
/*函数名:HashString
/*功 能:求取哈希值
/*返回值:返回hash值
/************************************************************************/
unsigned long StringHash::HashString(const string& lpszString, unsigned long dwHashType)
{
unsigned char *key = (unsigned char *)(const_cast<char*>(lpszString.c_str()));
unsigned long seed1 = 0x7FED7FED, seed2 = 0xEEEEEEEE;
int ch; while(*key != )
{
ch = toupper(*key++); seed1 = cryptTable[(dwHashType << ) + ch] ^ (seed1 + seed2);
seed2 = ch + seed1 + seed2 + (seed2 << ) + ;
}
return seed1;
} /************************************************************************/
/*函数名:Hashed
/*功 能:检测一个字符串是否被hash过
/*返回值:如果存在,返回位置;否则,返回-1
/************************************************************************/
unsigned long StringHash::Hashed(string lpszString) {
const unsigned long HASH_OFFSET = , HASH_A = , HASH_B = ;
//不同的字符串三次hash还会碰撞的几率无限接近于不可能
unsigned long nHash = HashString(lpszString, HASH_OFFSET);
unsigned long nHashA = HashString(lpszString, HASH_A);
unsigned long nHashB = HashString(lpszString, HASH_B);
unsigned long nHashStart = nHash % m_tablelength,
nHashPos = nHashStart; while ( m_HashIndexTable[nHashPos].bExists)
{
if (m_HashIndexTable[nHashPos].nHashA == nHashA && m_HashIndexTable[nHashPos].nHashB == nHashB)
return nHashPos;
else
nHashPos = (nHashPos + ) % m_tablelength; if (nHashPos == nHashStart)
break;
} return -; //没有找到
} /************************************************************************/
/*函数名:Hash
/*功 能:hash一个字符串
/*返回值:成功,返回true;失败,返回false
/************************************************************************/
bool StringHash::Hash(string lpszString)
{
const unsigned long HASH_OFFSET = , HASH_A = , HASH_B = ;
unsigned long nHash = HashString(lpszString, HASH_OFFSET);
unsigned long nHashA = HashString(lpszString, HASH_A);
unsigned long nHashB = HashString(lpszString, HASH_B);
unsigned long nHashStart = nHash % m_tablelength,
nHashPos = nHashStart; while ( m_HashIndexTable[nHashPos].bExists)
{
nHashPos = (nHashPos + ) % m_tablelength;
if (nHashPos == nHashStart) //一个轮回
{
//hash表中没有空余的位置了,无法完成hash
return false;
}
}
m_HashIndexTable[nHashPos].bExists = true;
m_HashIndexTable[nHashPos].nHashA = nHashA;
m_HashIndexTable[nHashPos].nHashB = nHashB; return true;
}
适用范围
快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
什么是Map
Map是c++标准库STL提供的一类关联式容器,提供key-value的存储和查找功能。
Map是基于红黑树的(同样set也是),那么它的查找速度是log(n)级别的。
它的优点是占用内存小。
Hash与Map的区别
权衡三个因素: 查找速度, 数据量, 内存使用。
总体来说,hash查找速度会比map快,而且查找速度基本和数据量大小无关,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n) 小,hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑hash。但若你对内存使用特别严格, 希望程序尽可能少消耗内存,那么一定要小心,hash可能会让你陷入尴尬,特别是当你的hash对象特别多时,你就更无法控制了,而且 hash的构造速度较慢。
参考
http://baike.baidu.com/view/20089
http://blog.csdn.net/v_july_v/article/details/6256463
http://panlianghui-126-com.iteye.com/blog/968057
http://singlelove1983.blog.163.com/blog/static/50849047200863122550370/
http://xdeduzb.blog.163.com/blog/static/8199363720111105949345/
http://www.cnblogs.com/ylan2009/archive/2012/04/13/2445101.html
本作品采用知识共享署名-非商业性使用-相同方式共享 3.0 未本地化版本许可协议进行许可。欢迎转载,请注明出处:
转载自:cococo点点 http://www.cnblogs.com/coder2012

Hash与Map的更多相关文章
- POJ 3320 尺取法,Hash,map标记
1.POJ 3320 2.链接:http://poj.org/problem?id=3320 3.总结:尺取法,Hash,map标记 看书复习,p页书,一页有一个知识点,连续看求最少多少页看完所有知识 ...
- HDU4821---字符串hash,map判重
这是2013年长春区域赛的铜牌题...然而第一次做的时候一直觉得会超时的..最后才知道并没有想象中的那么恐怖: 这题有两个注意的地方: (1)h[i] = h[i-1] * seed + s[i] - ...
- HDU——2112HDU Today(SPFA+简单Hash或map+前向星)
HDU Today Time Limit: 15000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- hash与map的区别联系应用(转)
一,hashtable原理: 哈希表又名散列表,其主要目的是用于解决数据的快速定位问题.考虑如下一个场景. 一列键值对数据,存储在一个table中,如何通过数据的关键字快速查找相应值呢?不要告诉我一个 ...
- hash与map的区别联系应用
一,hashtable原理: 哈希表又名散列表,其主要目的是用于解决数据的快速定位问题.考虑如下一个场景. 一列键值对数据,存储在一个table中,如何通过数据的关键字快速查找相应值呢?不要告诉我一个 ...
- [JZOJ 5893] [NOIP2018模拟10.4] 括号序列 解题报告 (Hash+栈+map)
题目链接: https://jzoj.net/senior/#main/show/5893 题目: 题解: 考虑暴力怎么做,我们枚举左端点,维护一个栈,依次加入元素,与栈顶元素和栈内第二个元素相同时弹 ...
- JAVA学习笔记--初探hash与map
先推荐一篇文章 http://blog.csdn.net/cownew/article/details/6478993 也为自己mark
- STL之map应用 +hash表(51nod 1095)
题目:Anigram单词 题意:给出词典,再给出一些单词,求单词的Anigram数量. 思路:先将字串转换成哈希表,然后再用map链接. hash表构造方法汇总:http://www.cnblogs. ...
- poj 2503 Babelfish(Map、Hash、字典树)
题目链接:http://poj.org/bbs?problem_id=2503 思路分析: 题目数据数据量为10^5, 为查找问题,使用Hash或Map等查找树可以解决,也可以使用字典树查找. 代码( ...
随机推荐
- java 下载 断点续传
1 import java.io.BufferedInputStream; 2 import java.io.File; 3 import java.io.FileInputStream; 4 imp ...
- 运行时报错-Verify the Developer App certificate for youraccount is trusted on your device. Open Settings on Mayoyi_sakura and navigate to General -> Device Management, then select your
解决方法:打开手机设置->通用->设备管理,找到编辑工程时的ID资料,点击允许即可.
- C#数据库操作
1.常用的T-Sql语句 查询:SELECT * FROM tb_test WHERE ID='1' AND name='xia' SELECT * FROM ...
- jQuery2
一.类型选择器 jQuery的类型选择器 选择器 说明 :button 选择所有按钮 :checkbox 选择所有复选框 :file 选择所有文件上传输入框 :header 选择所有标题元素(h1,h ...
- 如何创建多个Memcached服务
在学习Memcached时,为了模拟分布存储,常常需要建多个Memcached服务,如何建呢,只能使用命令行了 运行cmd,输入如下命令 sc create "Memcached Serve ...
- MJExtension 中model嵌套Model
+ (NSDictionary *)objectClassInArray { return @{@"comment": [Comment class]};}
- Android学习之 Intent详解
一. Intent 作用 Intent 是一个将要执行的动作的抽象的描述,一般来说是作为参数来使用,由Intent来协助完成android各个组件之间的通讯.比如说调用startActivity()来 ...
- iOS 1 到 iOS 10 ,我都快老了
iOS 1:iPhone诞生 虽然很难想像,但初代iPhone在问世时在功能方面其实远远落后于那时的竞争对手,比如Windows Mobile.Palm OS.塞班.甚至是黑莓.它不支持3G.多任务. ...
- [C#-SQLite] SQLite一些奇怪的问题
今天整C#的DAO层,我用的2013, 用的4.0的.NetFramework刚刚创建完Helper就出现异常 + Connection "helper.Connecti ...
- 11 个 Linux 上最佳的图形化 Git 客户端
Git是软件开发和若干其他版本控制任务免费和开源的分布式版本控制系统.它被设计用来以应付一切从小到非常大的项目,基于速度,效率和数据完整性. Linux用户主要通过命令行管理Git,不过,一些图形用户 ...