flume实时采集mysql数据到kafka中并输出
环境说明
- centos7(运行于vbox虚拟机)
- flume1.9.0(flume-ng-sql-source插件版本1.5.3)
- jdk1.8
- kafka(版本忘了后续更新)
- zookeeper(版本忘了后续更新)
- mysql5.7.24
- xshell
准备工作
flume安装
暂略,后续更新
flume简介
Apache Flume是一个分布式的、可靠的、可用的系统,用于有效地收集、聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储。在大数据生态圈中,flume经常用于完成数据采集的工作。
其实时性很高,延迟大约1-2s,可以做到准实时。
又因为mysql是程序员常用的数据库,所以以flume实时采集mysql数据库为例子。要了解flume如何采集数据,首先要初探其架构:
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是
source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
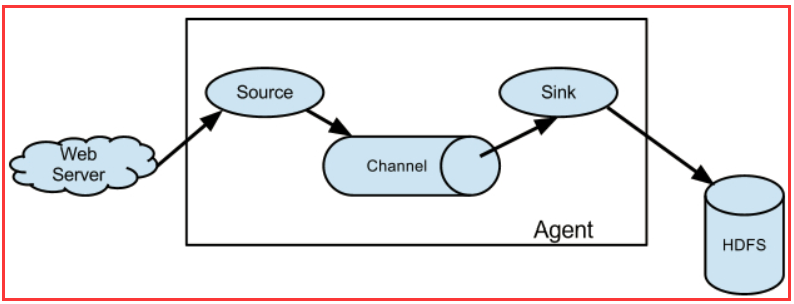
三大组件
source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。
Flume提供了各种source的实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source等。如果内置的Source无法满足需要, Flume还支持自定义Source。
可以看到原生flume的source并不支持sql source,所以我们需要添加插件,后续将提到如何添加。
channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
- MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
- MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。
- FileChannel保证数据的完整性与一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
sink
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
这个例子中,我使用了kafka作为sink
下载flume-ng-sql-source插件
到这里下载flume-ng-sql-source,最新版本是1.5.3。
下载完后解压,我通过idea运行程序,使用maven打包为jar包,改名为flume-ng-sql-source-1.5.3.jar
编译完的jar包要放在放到FLUME_HOME/lib下,FLUME_HOME是自己linux下flume的文件夹,比如我的是 /opt/install/flume
kafka安装
我们使用flume将数据采集到kafka, 并启动一个kafak的消费监控,就能看到实时数据了
jdk1.8安装
暂略,后续更新
zookeeper安装
暂略,后续更新
kafka安装
暂略,后续更新
mysql5.7.24安装
暂略,后续更新
flume抽取mysql数据到kafka实战
新建一个数据库和表
在完成上述的安装工作后就可以开始着手实现demo了
首先我们要抓取mysql的数据,那么必然需要一个数据库和表,并且要记住这个数据库和表的名字,之后这些信息要写入flume的配置文件。
创建数据库:
create database test
创建表:
create table fk(
id int UNSIGNED AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
PRIMARY KEY ( id )
);
新增配置文件(重要)
cd 到flume的conf文件夹中,新增一个文件mysql-flume.conf
[root@localhost ~]# cd /opt/install/flume
[root@localhost flume]# ls
bin conf doap_Flume.rdf lib NOTICE RELEASE-NOTES tools
CHANGELOG DEVNOTES docs LICENSE README.md status
[root@localhost flume]# cd conf
[root@localhost conf]# ls
flume-conf.properties.template log4j.properties
flume-env.ps1.template mysql-connector-java-5.1.35
flume-env.sh mysql-connector-java-5.1.35.tar.gz
flume-env.sh.template mysql-flume.conf
注:mysql-flume.conf本来是没有的,是我生成的,具体配置如下所示
在这个文件中写入:
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user = root
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testTopic
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
这是我的文件,其中一些隐私信息已被我用其他字符串替代了,在写mysql-flume.conf时你可以复制上面的一段代码。下面是这段代码的详细注释,你可以更加带注释版本的代码来修改自己的conf文件
# a1表示agent的名称
# source是a1的输入源
# channels是缓冲区
# sinks是a1输出目的地,本例子sinks使用了kafka
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
# 连接mysql的一系列操作,youhost改为你虚拟机的ip地址,可以通过ifconfig或者ip addr查看
# url中要加入?useUnicode=true&characterEncoding=utf-8&useSSL=false,否则有可能连接失败
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://youhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false
# Hibernate Database connection properties
# mysql账号,一般都是root
a1.sources.src-1.hibernate.connection.user = root
# 填入你的mysql密码
a1.sources.src-1.hibernate.connection.password = xxxxxxxx
a1.sources.src-1.hibernate.connection.autocommit = true
# mysql驱动
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
# 驱动版本过低会无法使用,驱动安装下文会提及
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
# 存放status文件
a1.sources.src-1.status.file.path = /opt/install/flume/status
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.start.from = 0
# 填写需要采集的数据表信息,你也可以使用下面的方法:
# agent.sources.sql-source.table =table_name
# agent.sources.sql-source.columns.to.select = *
a1.sources.src-1.custom.query = select `id`, `name` from fk
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
# 使用kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 这个项目中你创建的或使用的topic名字
a1.sinks.k1.topic = testTopic
# kafka集群,broker列表,由于我没有使用集群所以只有一个
# 如果你搭建了集群,代码如下:agent.sinks.k1.brokerList = kafka-node1:9092,kafka-node2:9092,kafka-node3:9092
a1.sinks.k1.brokerList = 10.100.4.6:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
添加mysql驱动到flume的lib目录下
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.35.tar.gz
tar xzf mysql-connector-java-5.1.35.tar.gz
cp mysql-connector-java-5.1.35-bin.jar /你flume的位置/lib/
启动zookeeper
启动kafka前要启动zookeeper
cd 到zookeeper的bin目录下
启动:
./zkServer.sh start
等待运行
./zkCli.sh
启动kafka
xshell中打开一个新窗口,cd到kafka目录下,启动kafka
bin/kafka-server-start.sh config/server.properties &
新建一个topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
注1:testTopic就是你使用的topic名称,这个和上文mysql-flume.conf里的内容是对应的。
注2:可以使用bin/kafka-topics.sh --list --zookeeper localhost:2181来查看已创建的topic。
启动flume
xshell中打开一个新窗口,cd到flume目录下,启动flume
bin/flume-ng agent -n a1 -c conf -f conf/mysql-flume.conf -Dflume.root.logger=INFO,console
等待他运行,同时我们可以打开一个新窗口连接数据库,使用我们新建的test数据库和fk表。
实时采集数据
flume会实时采集数据到kafka中,我们可以启动一个kafak的消费监控,用于查看mysql的实时数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
这时就可以查看数据了,kafka会打印mysql中的数据
然后我们更改数据库中的一条数据,新读取到的数据也会变更
before:

after:
.png)
flume实时采集mysql数据到kafka中并输出的更多相关文章
- flume采集MongoDB数据到Kafka中
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(自定义了flume连接mongodb的source插件) jdk1.8 kafka(2.11) zookeeper(3.57) ...
- 使用maxwell实时同步mysql数据到kafka
一.软件环境: 操作系统:CentOS release 6.5 (Final) java版本: jdk1.8 zookeeper版本: zookeeper-3.4.11 kafka 版本: kafka ...
- 采用Flume实时采集和处理数据
它已成功安装Flume在...的基础上.本文将总结使用Flume实时采集和处理数据,详细过程,如下面: 第一步,在$FLUME_HOME/conf文件夹下,编写Flume的配置文件,命名为flume_ ...
- Mysql增量写入Hdfs(一) --将Mysql数据写入Kafka Topic
一. 概述 在大数据的静态数据处理中,目前普遍采用的是用Spark+Hdfs(Hive/Hbase)的技术架构来对数据进行处理. 但有时候有其他的需求,需要从其他不同数据源不间断得采集数据,然后存储到 ...
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- MongoDB -> kafka 高性能实时同步(sync 采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- WebSocket 实时更新mysql数据到页面
使用websocket的初衷是,要实时更新mysql中的报警信息到web页面显示 没怎么碰过web,代码写的是真烂,不过也算是功能实现了,放在这里也是鞭策自己,web也要多下些功夫 准备 引入依赖 & ...
- flink-cdc同步mysql数据到kafka
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
随机推荐
- POJ1325二分匹配或者DINIC(最小路径覆盖)
题意: 有k个任务,两个机器,第一个机器有n个模式,第二个机器有m个模式,每个任务要么在第一个机器的一个模式下工作,要么在第二个机器的一个模式下工作,机器每切换一个模式需要重启一次,两个 ...
- WIN64内核编程-的基础知识
WIN64内核编程基础班(作者:胡文亮) https://www.dbgpro.com/x64driver 我们先从一份"简历"说起: 姓名:X86或80x86 性别:? 出生 ...
- 重新封装了一下NODE-MONGO 使其成为一个独立的服务.可以直接通过get/post来操作
# 重新封装了一下NODE-MONGO 使其成为一个独立的服务.可以直接通过get/post来操作 # consts.js 配置用的数据,用于全局参数配置 # log.js 自己写的一个简单的存储本地 ...
- 【python】Leetcode每日一题-森林中的兔子
[python]Leetcode每日一题-森林中的兔子 [题目描述] 森林中,每个兔子都有颜色.其中一些兔子(可能是全部)告诉你还有多少其他的兔子和自己有相同的颜色.我们将这些回答放在 answers ...
- Day004 选择结构
选择结构 if单选择结构(if) if双选择结构(if...else...) if多选择结构(if..else if...else) 嵌套的if结构 switch多选择结构 switch语句中的变量类 ...
- 类的两个装饰器classmethod、staticethod和内置魔术方法
一.两个装饰器@classmethod.@staticmethod @classmethod:把类中的绑定方法变成一个类方法,cls 就等于类名 有什么用? 1.在方法中任然可以引用类中的静态变量 2 ...
- 上手 WebRTC DTLS 遇到很多 BUG?浅谈 DTLS Fragment
上一篇<详解 WebRTC 传输安全机制:一文读懂 DTLS 协议>详细阐述了 DTLS.本文将结合 DTLS 开发中遇到的问题,详细解读 DTLS 的一些基础概念以及 Fragment ...
- JAVA并发(1)-AQS(亿点细节)
AQS(AbstractQueuedSynchronizer), 可以说的夸张点,并发包中的几乎所有类都是基于AQS的. 一起揭开AQS的面纱 1. 介绍 为依赖 FIFO阻塞队列 的阻塞锁和相关同步 ...
- SpringBoot整合shiro系列-SpingBoot是如何将shiroFilter注册到servlet容器中的
一.先从配置类入手,主要是@Bean了一个ShiroFilterFactoryBean: @Data @Configuration @Slf4j @EnableConfigurationPropert ...
- istio流量管理:非侵入式流量治理
在服务治理中,流量管理是一个广泛的话题,一般情况下,常用的包括: 动态修改服务访问的负载均衡策略,比如根据某个请求特征做会话保持: 同一个服务有多版本管理,将一部分流量切到某个版本上: 对服务进行保护 ...