【现学现卖】python小爬虫
1.给小表弟汇总一个院校列表,想来想去可以写一个小爬虫爬下来方便些,所以就看了看怎么用python写,到了基本能用的程度,没有什么特别的技巧,大多都是百度搜的,遇事不决问百度啦
2.基本流程就是:
用request爬取一个页面之后用BeautifulSoup4对爬到的页面进行处理,
然后需要的东西进行预处理之后存到桌面上的.txt文件里,
之后再对.txt文件里的字符串进行分割,
最后把数据存到excel表里
3.准备:需要下载安装requests库,以及BeautifulSoup4的库,还有xlsxwriter库,相关安装方法网上一大堆
4.爬取页面的网页源代码:

5.将爬取的数据存到.txt文件中:
from bs4 import BeautifulSoup
import requests
import os def get_soup():
r = requests.get("http://www.eol.cn/html/g/gxmd/bj/", timeout=30)
# 判断网络链接的状态,连接错误将产生一个异常
#print(r.status_code)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,features="html.parser")
return soup; #删除前几个元素
def del_previous_ele(full_list):
for i in range(8):
full_list.remove(full_list[0])
return full_list; #获取学校名称,学校编号,主管部门,办学层次
def select_school_ele(full_list):
school_list = []
for i in range(full_list.__len__()):
//这里是对获取的所有学校列表进行遍历,取出需要的数据
if (i % 7) == 1 or (i % 7) == 2 or (i % 7) == 3 or (i%7) == 5 :
school_list.append(full_list[i].string+"\t")
//获取到一个学校完整的信息之后就在后面换行
if (i%7) == 5:
school_list.append(" \n")
else:
pass return school_list;
#将数据写入文件
def createFile(txt):
file = open('C:\\Users\\XXXXXXXXXXXXXXX\\Desktop\\school.txt', 'w')
file.writelines(txt)
file.close();
print("写入成功") if __name__ == "__main__":
soup = get_soup()
full_list = del_previous_ele(soup.find_all(align="center"))
school_list = select_school_ele(full_list)
createFile(school_list)
6.对school.txt文件进行处理,处理完了存到excel文件里
import os
import xlsxwriter
def get_file(path,mode_):
list = "";
file = open(path,mode_)
list = file.read()
file.close() return list def write_excel(list):
workbook = xlsxwriter.Workbook("C:\\Users\\XXXXXXXXXXXXXXXXX\\Desktop\\school.xlsx")
worksheet = workbook.add_worksheet("school")
#5个属性为一组
list_5_item = list.split("\n")
# print(len(list_5_item))
for i in range(len(list_5_item)):
specific_school = list_5_item[i].split("\t")
print(len(specific_school))
for j in range(len(specific_school)):
worksheet.write( i , j , specific_school[j]) if __name__ == "__main__":
list = get_file('C:\\Users\\XXXXXXXXXXXXXXXXXXXXXXXXXXXx\\Desktop\\new.txt', 'r')
write_excel(list)
7.完成结果:
文本文件:
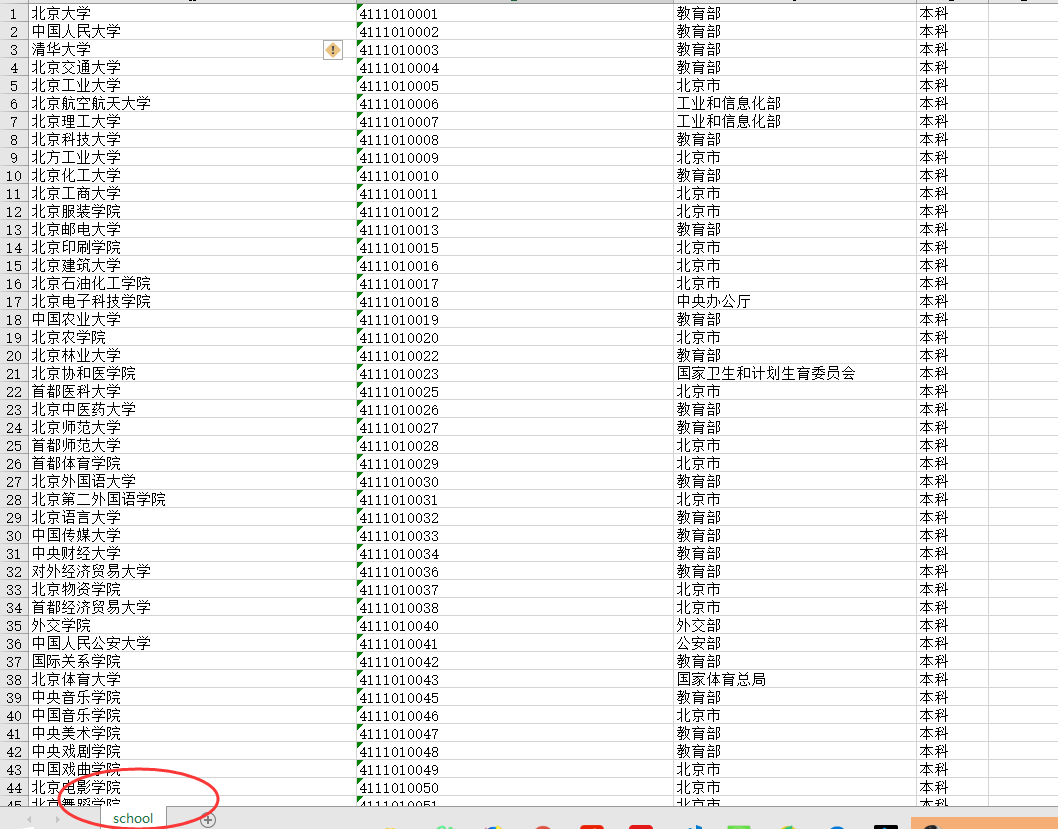
school.xlsx文件:
8.到这里就结束啦,因为刚接触写爬虫,所以有些地方难免写的不好,不喜勿喷啦
【现学现卖】python小爬虫的更多相关文章
- python小爬虫练手
一个人无聊,写了个小爬虫爬取不可描述图片.... 代码太短,就暂时先往这里贴一下做备份吧. 注:这是很严肃的技术研究,当然爬下来的图片我会带着批判性的眼光审查一遍的.... :) #! /usr/ ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- 现学现卖】IntelliJ+EmmyLua 开发调试Unity中Xlua
http://blog.csdn.net/u010019717/article/details/77510066?ref=myread http://blog.csdn.NET/u010019717 ...
- 现学现卖——VS2013 C#测试
VS2013 C#测试 首先安装Unit Test Generator.方法为:工具->扩展和更新->联机->搜索“Unit Test Generator”,图标为装有蓝色液体的小试 ...
- 程序猿的日常——Mybatis现学现卖
最近有一个小项目需求,需要用spring mvc + mybatis实现一个复杂的配置系统.其中遇到了很多不太常见的问题,在这里特意记录下: 主要涉及的内容有 事务 多表删除 插入并返回主键 1 sp ...
- 现学现卖——Keil uVision 使用教程
Keil uVision 使用教程 1.如果有旧的工程在,先关闭旧工程.Project -> Close Project2.新建工程.Project -> New uVision Proj ...
- 【现学现卖】th:href标签动态路径设置,thymeleaf获取session中的属性值
update:2020-02-28:按道理来说这个功能在前后端分离的时候应该不怎么用的上,基本到现在我还是没遇到过有这样的需求,不过也是一种方法就是.th:href="@{/{role}/l ...
- Python 小爬虫流程总结
接触Python3一个月了,在此分享一下知识点,也算是温故而知新了. 接触python之前是做前端的.一直希望接触面能深一点.因工作需求开始学python,几乎做的都是爬虫..第一个demo就是爬取X ...
- Python小爬虫-自动下载三亿文库文档
新手学python,写了一个抓取网页后自动下载文档的脚本,和大家分享. 首先我们打开三亿文库下载栏目的网址,比如专业资料(IT/计算机/互联网)http://3y.uu456.com/bl-197?o ...
随机推荐
- C语言:整数取值范转及溢出
short.int.long 是C语言中常用的三种整数类型,分别称为短整型.整型.长整型.在现代操作系统中,short.int.long 的长度分别是 2.4.4 或者 8,它们只能存储有限的数值,当 ...
- Day10 类与对象-面向对象编程(1)
面向对象编程(OOP) 面向对象编程的本质就是:以类的方式组织代码,以对象的组织(封装)数据. 抽象 三大特征: 封装 继承 多态 从认识论角度考虑是先有对象后有类.对象,是具体的事物.类,是抽象的, ...
- 手写系列-实现一个铂金段位的 React
一.前言 本文基于 https://pomb.us/build-your-own-react/ 实现简单版 React. 本文学习思路来自 卡颂-b站-React源码,你在第几层. 模拟的版本为 Re ...
- UBUNTU 16.04 LTS SERVER 手动升级 MariaDB 到最新版 10.2
UBUNTU 16.04 LTS SERVER 手动升级 MariaDB 到最新版 10.2 1. 起因 最近因为不同软件的数据问题本来只是一些小事弄着弄着就越弄越麻烦了,期间有这么个需求,没看到有中 ...
- 【数论】A%B Problem luogu-1865
题目描述 让你输出区间内的素数的个数 分析 预处理筛法,在随便搞一下就好了. AC代码 #include <bits/stdc++.h> using namespace std; #def ...
- C++第三十九篇 -- 研究一下Windows驱动开发(二)-- 驱动程序中重要的数据结构
数据结构是计算机程序的核心,I/O管理器定义了一些数据结构,这些数据结构是编写驱动程序时所必须掌握的.驱动程序经常要创建和维护这些数据结构的实例. 一.驱动对象(DRIVER_OBJECT) 每个驱动 ...
- vue 使用 lang="scss" 报错
npm install sass-loader@7.3.1 --save-dev npm install node-sass --save npm install style-loader --sav ...
- JS 之循环 应用案例1
应用场景:将el-select下拉框的lab值,显示在下面的详情text框,见下图 用到了 el-select 传值,js循环判断options.code是否等于传进来的值,等于就break; tex ...
- Hashtable 的实现原理
概述 和 HashMap 一样,Hashtable 也是一个散列表,它存储的内容是键值对. Hashtable 在 Java 中的定义为: public class Hashtable<K,V& ...
- jquey 定位到有某个类
$active = $('.g-pop-box .box-option a[class="on"]')