图解MySQL:count(*) 、count(1) 、count(主键字段)、count(字段)哪个性能最好?
大家好,我是小林。
当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1)、count(*)、count(字段) 等。
到底哪种效率是最好的呢?是不是 count(*) 效率最差?
我曾经以为 count(*) 是效率最差的,因为认知上 selete * from t 会读取所有表中的字段,所以凡事带有 * 字符的就觉得会读取表中所有的字段,当时网上有很多博客也这么说。
但是,当我深入 count 函数的原理后,被啪啪啪的打脸了!
不多说, 发车!
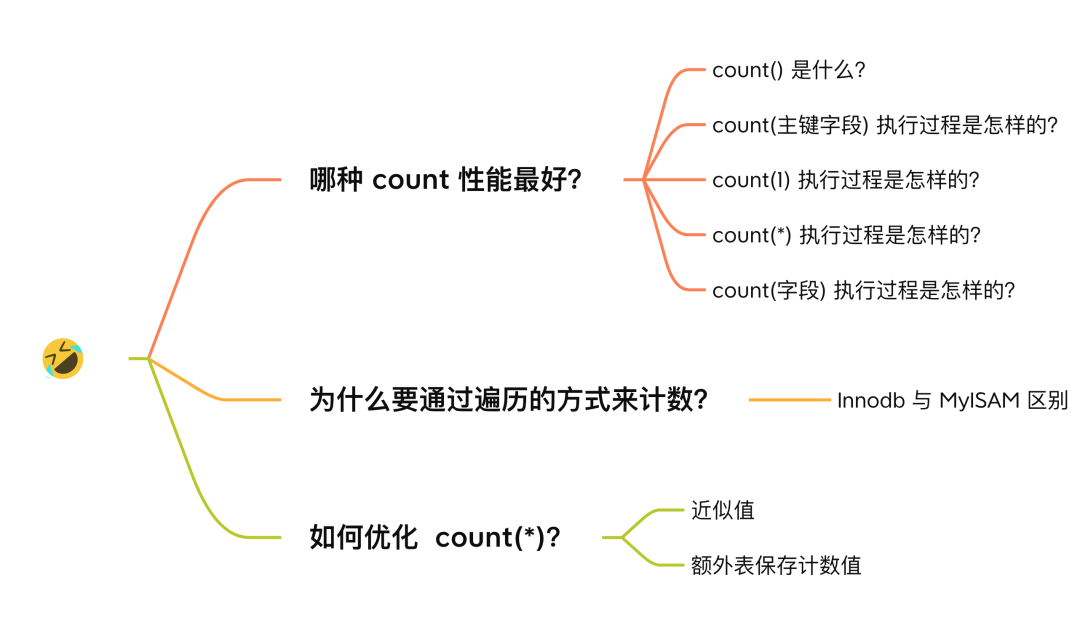
哪种 count 性能最好?
哪种 count 性能最好?
我先直接说结论:

要弄明白这个,我们得要深入 count 的原理,以下内容基于常用的 innodb 存储引擎来说明。
count() 是什么?
count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
假设 count() 函数的参数是字段名,如下:
select count(name) from t_order;
这条语句是统计「 t_order 表中,name 字段不为 NULL 的记录」有多少个。也就是说,如果某一条记录中的 name 字段的值为 NULL,则就不会被统计进去。
再来假设 count() 函数的参数是数字 1 这个表达式,如下:
select count(1) from t_order;
这条语句是统计「 t_order 表中,1 这个表达式不为 NULL 的记录」有多少个。
1 这个表达式就是单纯数字,它永远都不是 NULL,所以上面这条语句,其实是在统计 t_order 表中有多少个记录。
count(主键字段) 执行过程是怎样的?
在通过 count 函数统计有多少个记录时,MySQL 的 server 层会维护一个名叫 count 的变量。
server 层会循环向 InnoDB 读取一条记录,如果 count 函数指定的参数不为 NULL,那么就会将变量 count 加 1,直到符合查询的全部记录被读完,就退出循环。最后将 count 变量的值发送给客户端。
InnoDB 是通过 B+ 树来保持记录的,根据索引的类型又分为聚簇索引和二级索引,它们区别在于,聚簇索引的叶子节点存放的是实际数据,而二级索引的叶子节点存放的是主键值,而不是实际数据。
用下面这条语句作为例子:
//id 为主键值
select count(id) from t_order;
如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历聚簇索引,将读取到的记录返回给 server 层,然后读取记录中的 id 值,就会 id 值判断是否为 NULL,如果不为 NULL,就将 count 变量加 1。
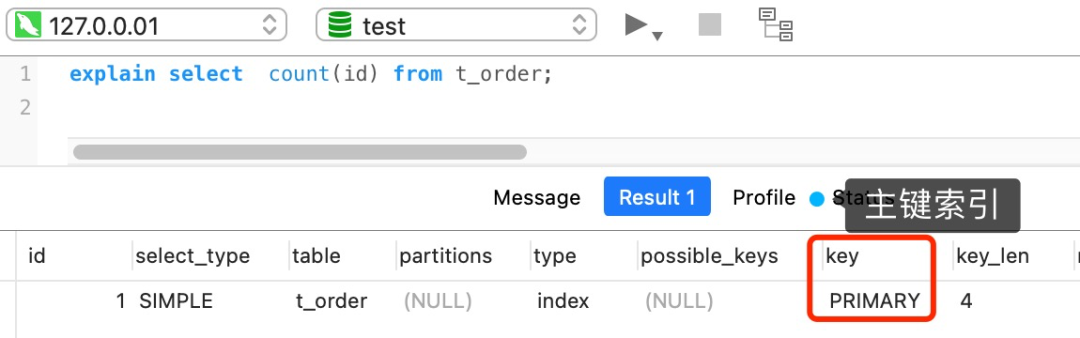
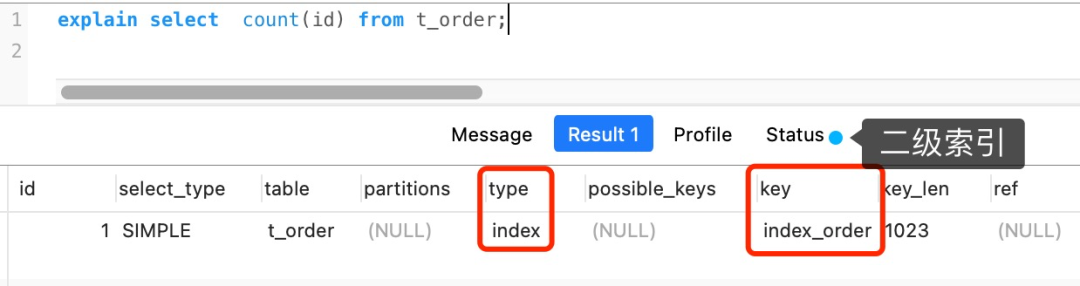
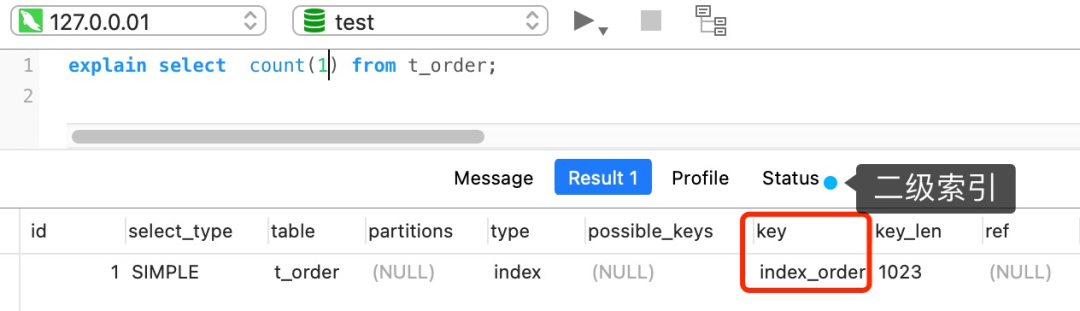
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就不是聚簇索引,而是二级索引。
 图片
图片
这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,这样遍历二级索引的 I/O 成本比遍历聚簇索引的 I/O 成本小,因此「优化器」优先选择的是二级索引。
count(1) 执行过程是怎样的?
用下面这条语句作为例子:
select count(1) from t_order;
如果表里只有主键索引,没有二级索引时。
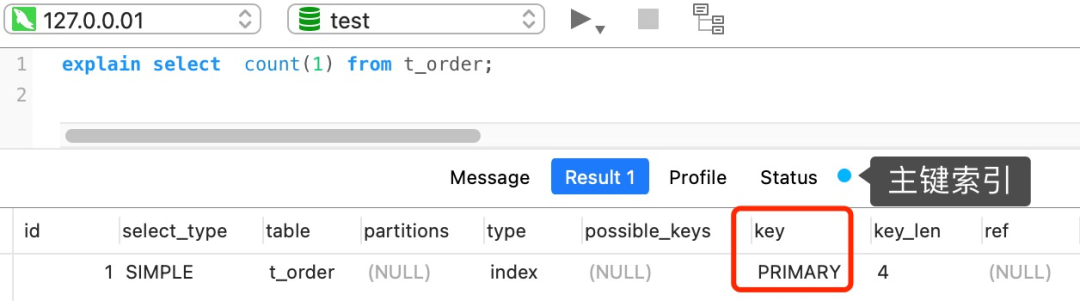
那么,InnoDB 循环遍历聚簇索引(主键索引),将读取到的记录返回给 server 层,但是不会读取记录中的任何字段的值,因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。参数 1 很明显并不是 NULL,因此 server 层每从 InnoDB 读取到一条记录,就将 count 变量加 1。
可以看到,count(1) 相比 count(主键字段) 少一个步骤,就是不需要读取记录中的字段值,所以通常会说 count(1) 执行效率会比 count(主键字段) 高一点。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就二级索引了。
count(*) 执行过程是怎样的?
看到 * 这个字符的时候,是不是大家觉得是读取记录中的所有字段值?
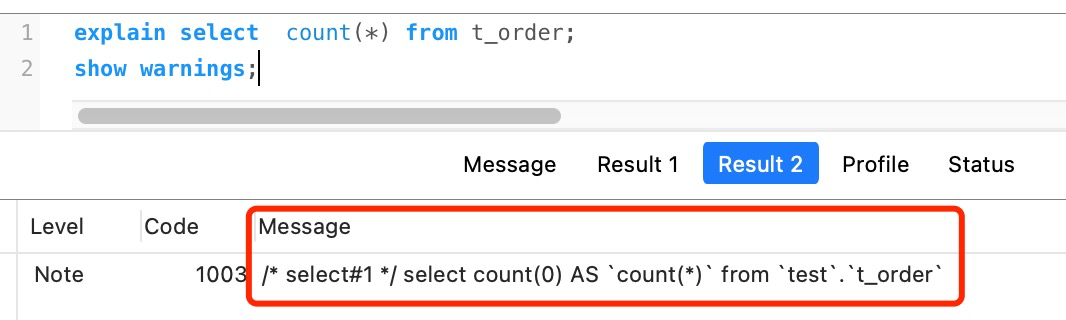
对于 selete * 这条语句来说是这个意思,但是在 count(*) 中并不是这个意思。
count(\*) 其实等于 count(0),也就是说,当你使用 count(*) 时,MySQL 会将 * 参数转化为参数 0 来处理。
所以,count(*) 执行过程跟 count(1) 执行过程基本一样的,性能没有什么差异。
在 MySQL 5.7 的官方手册中有这么一句话:
InnoDB handles SELECT COUNT(\*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
翻译:InnoDB以相同的方式处理SELECT COUNT(\*)和SELECT COUNT(1)操作,没有性能差异。
而且 MySQL 会对 count(*) 和 count(1) 有个优化,如果有多个二级索引的时候,优化器会使用key_len 最小的二级索引进行扫描。
只有当没有二级索引的时候,才会采用主键索引来进行统计。
count(字段) 执行过程是怎样的?
count(字段) 的执行效率相比前面的 count(1)、 count(*)、 count(主键字段) 执行效率是最差的。
用下面这条语句作为例子:
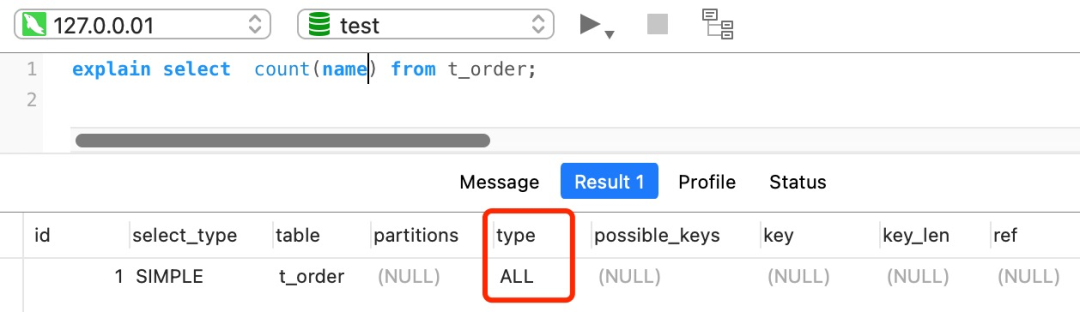
//name不是索引,普通字段
select count(name) from t_order;
对于这个查询来说,会采用全表扫描的方式来计数,所以它的执行效率是比较差的。
 图片
图片
小结
count(1)、 count(*)、 count(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。
所以,如果要执行 count(1)、 count(*)、 count(主键字段) 时,尽量在数据表上建立二级索引,这样优化器会自动采用 key_len 最小的二级索引进行扫描,相比于扫描主键索引效率会高一些。
再来,就是不要使用 count(字段) 来统计记录个数,因为它的效率是最差的,会采用全表扫描的方式来统计。如果你非要统计表中该字段不为 NULL 的记录个数,建议给这个字段建立一个二级索引。
为什么要通过遍历的方式来计数?
你可以会好奇,为什么 count 函数需要通过遍历的方式来统计记录个数?
我前面将的案例都是基于 Innodb 存储引擎来说明的,但是在 MyISAM 存储引擎里,执行 count 函数的方式是不一样的,通常在没有任何查询条件下的 count(*),MyISAM 的查询速度要明显快于 InnoDB。
使用 MyISAM 引擎时,执行 count 函数只需要 O(1 )复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息有存储了row_count值,由表级锁保证一致性,所以直接读取 row_count 值就是 count 函数的执行结果。
而 InnoDB 存储引擎是支持事务的,同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的,所以无法像 MyISAM一样,只维护一个 row_count 变量。
举个例子,假设表 t_order 有 100 条记录,现在有两个会话并行以下语句:
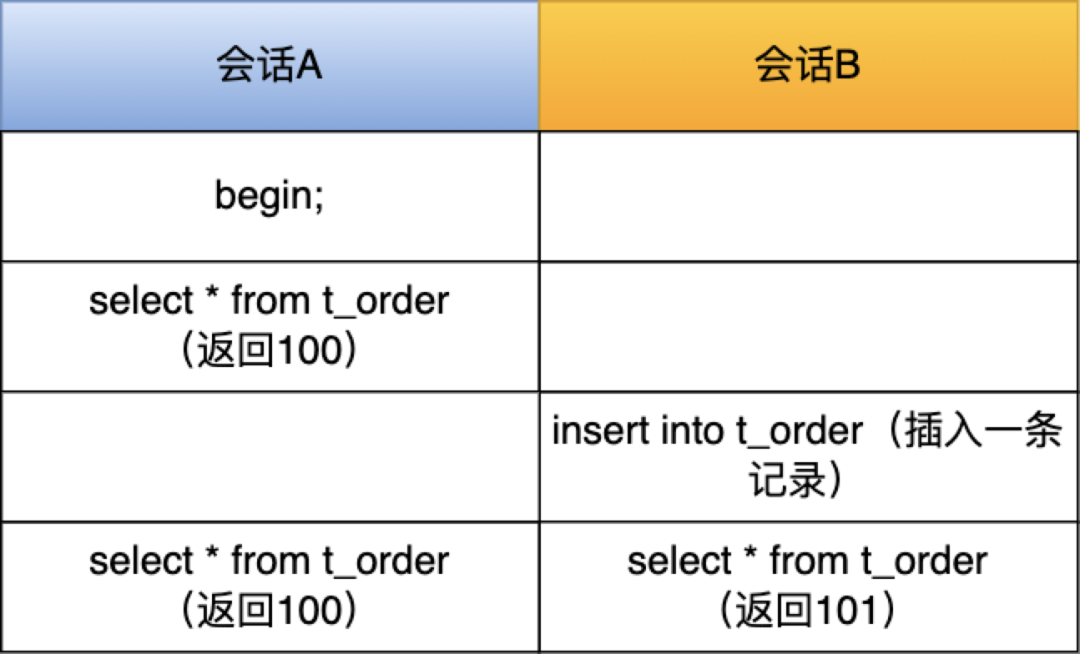
在会话 A 和会话 B的最后一个时刻,同时查表 t_order 的记录总个数,可以发现,显示的结果是不一样的。所以,在使用 InnoDB 存储引擎时,就需要扫描表来统计具体的记录。
而当带上 where 条件语句之后,MyISAM 跟 InnoDB 就没有区别了,它们都需要扫描表来进行记录个数的统计。
如何优化 count(*)?
如果对一张大表经常用 count(*) 来做统计,其实是很不好的。
比如下面我这个案例,表 t_order 共有 1200+ 万条记录,我也创建了二级索引,但是执行一次 select count(*) from t_order 要花费差不多 5 秒!
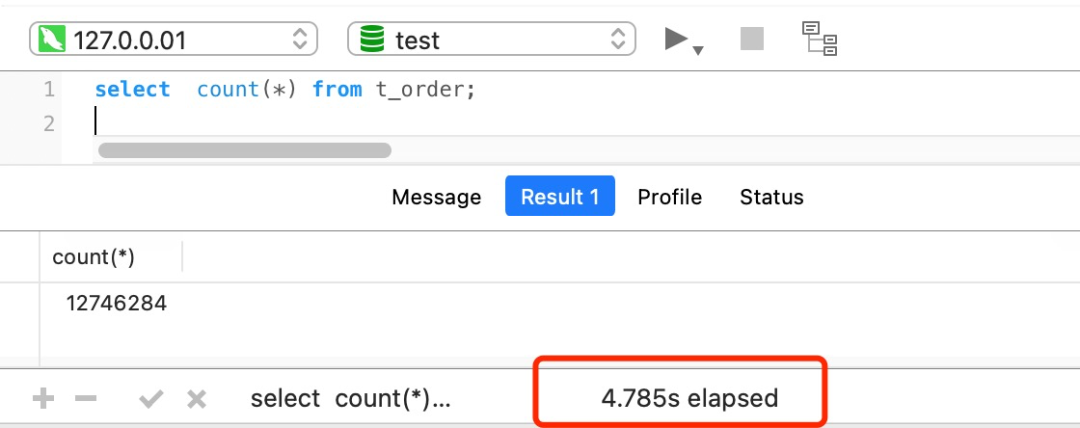
面对大表的记录统计,我们有没有什么其他更好的办法呢?
第一种,近似值
如果你的业务对于统计个数不需要很精确,比如搜索引擎在搜索关键词的时候,给出的搜索结果条数是一个大概值。
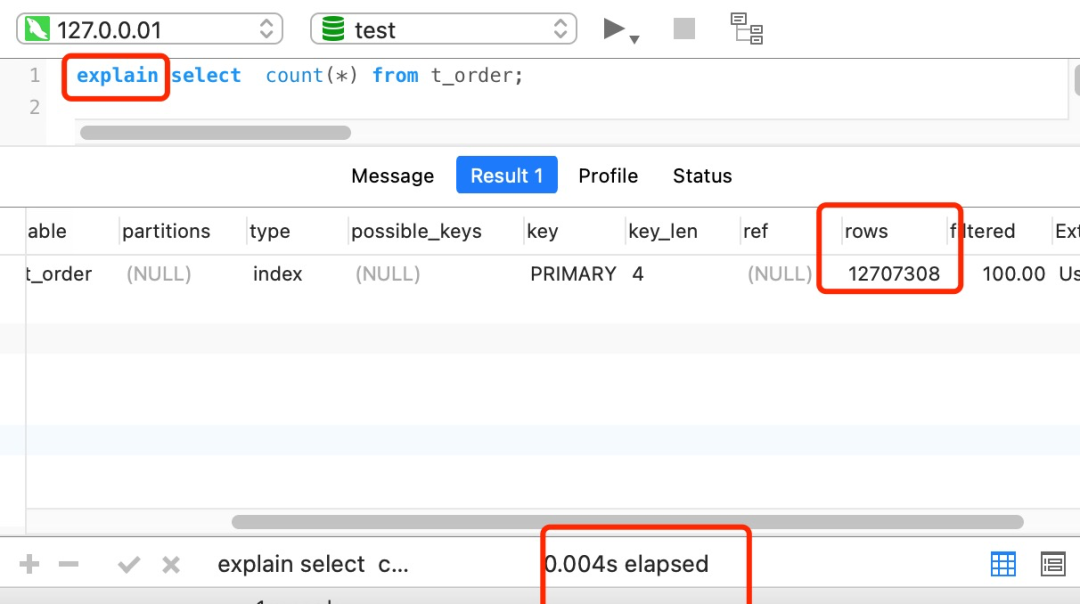
这时,我们就可以使用 show table status 或者 explain 命令来表进行估算。
执行 explain 命令效率是很高的,因为它并不会真正的去查询,下图中的 rows 字段值就是 explain 命令对表 t_order 记录的估算值。
第二种,额外表保存计数值
如果是想精确的获取表的记录总数,我们可以将这个计数值保存到单独的一张计数表中。
当我们在数据表插入一条记录的同时,将计数表中的计数字段 + 1。也就是说,在新增和删除操作时,我们需要额外维护这个计数表。
图解MySQL:count(*) 、count(1) 、count(主键字段)、count(字段)哪个性能最好?的更多相关文章
- COUNT(*)、COUNT(主键)、COUNT(1)
MyISAM引擎,记录数是结构的一部分,已存cache在内存中; InnoDB引擎,需要重新计算,id是主键的话,会加快扫描速度: 所以select count(*) MyISAM完胜! MyISA ...
- 【优化】COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)、COUNT(允许为空列)、COUNT(DISTINCT 列名)
[优化]COUNT(1).COUNT(*).COUNT(常量).COUNT(主键).COUNT(ROWID).COUNT(非空列).COUNT(允许为空列).COUNT(DISTINCT 列名) 1. ...
- mycat分布式mysql中间件(自增主键)
一.全局序列号 全局序列号是MyCAT提供的一个新功能,为了实现分库分表情况下,表的主键是全局唯一,而默认的MySQL的自增长主键无法满足这个要求.全局序列号的语法符合标准SQL规范,其格式为:nex ...
- (转)mysql自增列导致主键重复问题分析
mysql自增列导致主键重复问题分析... 原文:http://www.cnblogs.com/cchust/p/3914935.html 前几天开发童鞋反馈一个利用load data infile ...
- java面试一日一题:mysql中的自增主键
问题:请讲下mysql中的自增主键 分析:该问题主要考察对mysql中自增主键的掌握,使用场景及如何设置 回答要点: 主要从以下几点去考虑 1.什么自增主键 2.使用场景是什么: 3.innodb_a ...
- MySQL 插入与自增主键值相等的字段 与 高并发下保证数据准确的实验
场景描述: 表t2 中 有 自增主键 id 和 字段v 当插入记录的时候 要求 v与id 的值相等(按理来说这样的字段是需要拆表的,但是业务场景是 只有某些行相等 ) 在网上搜的一种办法是 先获取 ...
- oracle 中查看一张表是否有主键,主键在哪个字段上的语句怎么查如要查aa表,
select a.constraint_name, a.column_name from user_cons_columns a, user_constraints b where a.constra ...
- 一种历史详细记录表,完整实现:CommonOperateLog 详细记录某用户、某时间、对某表、某主键、某字段的修改(新旧值
一种历史详细记录表,完整实现:CommonOperateLog 详细记录某用户.某时间.对某表.某主键.某字段的修改(新旧值). 特别适用于订单历史记录.重要财务记录.审批流记录 表设计: names ...
- oracle中查看一张表是否有主键,主键在哪个字段上
利用Oracle中系统自带的两个视图可以实现查看表中主键信息,语句如下:select a.constraint_name, a.column_name from user_cons_columns a ...
- MySQL 使用自增ID主键和UUID 作为主键的优劣比较详细过程(从百万到千万表记录测试)
测试缘由 一个开发同事做了一个框架,里面主键是uuid,我跟他建议说mysql不要用uuid用自增主键,自增主键效率高,他说不一定高,我说innodb的索引特性导致了自增id做主键是效率最好的,为了拿 ...
随机推荐
- 石墨文档Websocket百万长连接技术实践
引言 在石墨文档的部分业务中,例如文档分享.评论.幻灯片演示和文档表格跟随等场景,涉及到多客户端数据同步和服务端批量数据推送的需求,一般的 HTTP 协议无法满足服务端主动 Push 数据的场景,因此 ...
- linux查询健康状态,如何直观的判断你的Linux系统是否健康
一提到对于查看系统运行的健康状况,可能大多数朋友考虑到的就是查看进程或者打开任务管理器,但是对于应用在真实生产环境中服务器的linux系统来说,以上两种方式都不是***效的查看方式,那么今天就给大家推 ...
- liunx 安装ActiveMQ 及 spring boot 初步整合 activemq
源码地址: https://gitee.com/kevin9401/microservice.git 一.安装 ActiveMQ: 1. 下载 ActiveMQ wget https://arch ...
- linux-源码软件管理-yum配置
总结如下:1.源码配置软件管理2.配置yum本地源和网络源及yum 工作原理讲解3.计算机硬盘介绍 1.1 源码管理软件 压缩包管理命令: # 主流的压缩格式包括tar.rar.zip.war.gzi ...
- Spring Boot项目的探究
一.pom.xml文件 1.父项目 <parent> <groupId>org.springframework.boot</groupId> <artifac ...
- Taro 3.5 canary 发布:支持适配 鸿蒙
一.背景 鸿蒙作为华为自研开发的一款可以实现万物互联的操作系统,一经推出就受到了很大的关注,被国人寄予了厚望.而鸿蒙也没让人失望,今年 Harmony2.0 正式推出供用户进行升级之后,在短短的三个月 ...
- logrotate没有rotate的排查过程
前言 背景 xxx,你过来把squid的日志检查一下,是否做了日志切割:于是乎开启了logrotate没有切割日志的排查旅程,em--.只能说过程很爽,平时疲于应付繁琐的事情,难得有点时间能一条线慢慢 ...
- log4j漏洞的产生原因和解决方案,小白都能看懂!!!!
核弹级bug Log4j,相信很多人都有所耳闻了,这两天很多读者都在问我关于这个bug的原理等一些问题,今天咱们就专门写一篇文章,一起聊一聊这个核弹级别的bug的产生原理以及怎么防止 产生原因 其实这 ...
- MySQL、Oracle元数据抽取分析
最近接到个任务是抽取mysql和Oracle的元数据,大致就是在库里把库.schema.表.字段.分区.索引.主键等信息抽取出来,然后导成excel. 因为刚开始接触元数据,对这个并不了解,就想借助一 ...
- java 数据类型:<泛型>在方法中和在构造器中的应用
背景: Java不允许我们把对象放在一个未知的集合中. import java.util.ArrayList; import java.util.List; /** * @ClassName Meth ...