Greenplum数仓监控解决方案(开源版本)
Greenplum监控解决方案
基于Prometheus+Grafana+greenplum_exporter+node_exporter实现
关联图

一、基本概念
1.Prometheus
Prometheus时序数据库:存储的是时序数据,即按相同时序(相同名称和标签),以时间维度存储连续的数据的集合,lPrometheus Server, 负责从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)供用户使用。
lExporter, 负责收集目标对象(host, container…)的性能数据,并通过 HTTP 接口供 Prometheus Server 获取。
l可视化组件,监控数据的可视化展现对于监控方案至关重要。以前 Prometheus 自己开发了一套工具,不过后来废弃了,因为开源社区出现了更为优秀的产品 Grafana。Grafana 能够与 Prometheus 无缝集成,提供完美的数据展示能力。
lAlertmanager,用户可以定义基于监控数据的告警规则,规则会触发告警。一旦 Alermanager 收到告警,会通过预定义的方式发出告警通知。支持的方式包括 Email、PagerDuty、Webhook 等。
2. Grafana 介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、支持数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
二、Greenplum监控的实现
2.1Prometheus安装
源码编译安装(推荐官网)
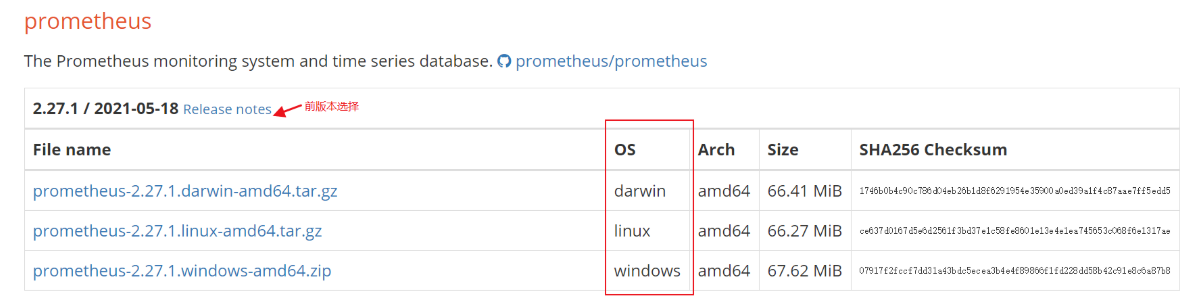
2.1.1下载源码包文件
$ cd usr/local/src/tools/ #自定义文件下载目录
命令下载(服务器可访问外网状态)
$ wget https://github.com/prometheus/prometheus/releases/download/v2.27.1/prometheus-2.27.1.linux-amd64.tar.gz
注:下载到本地通过第三方工具上载到服务器指定位置(服务器不可访问外网)
解压文件到自定义目录
tar -zxvf prometheus-2.27.1.linux-amd64.tar.gz -C /usr/local/
mv prometheus-2.27.1.linux-amd64/ prometheus #修改文件名便于管理
cd /usr/local/prometheus/
解压后文件目录
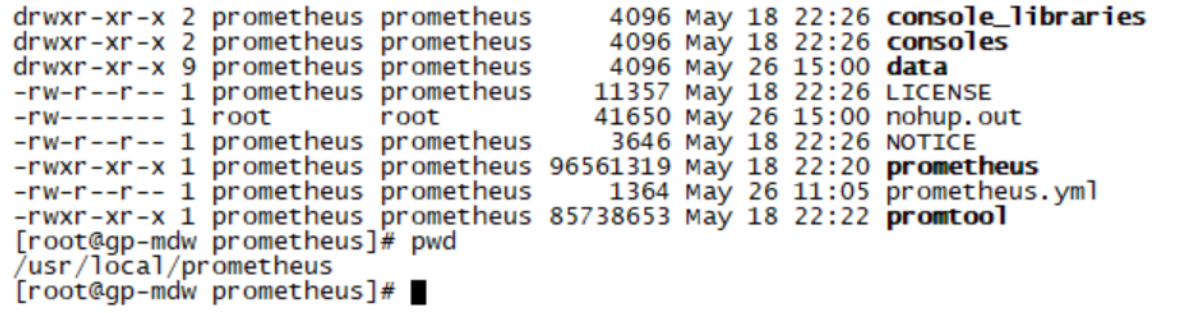
2.1.2创建用户用于管理启动prometheus服务
$ groupadd prometheus
$ useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus
$ chown prometheus.prometheus -R /usr/local/prometheus
2.1.3启动prometheus
注:启动方式有以下两种建议选择第二种执行方式便于管理服务
1.直接执行prometheus命令
cd /usr/local/prometheus
nohup ./prometheus &
ps -ef | grep prometheus #检查后台进程

2.配置系统systemd服务
(注:如启动失败查看当前系统服务启动日志cat /var/log/messages 如已按上述命令启动需kill掉当前后台运行进程才能重新运行下列启动命令)
cat > /usr/lib/systemd/system/prometheus.service <<EOF
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple #默认
User=prometheus #管理启动用户
ExecStart=/usr/local/prometheus/prometheus -- config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/var/lib/prometheus
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
启动prometheus服务
systemctl daemon-reload #重新加载服务配置文件
systemctl start prometheus.service
systemctl status prometheus.service
systemctl enable prometheus.service

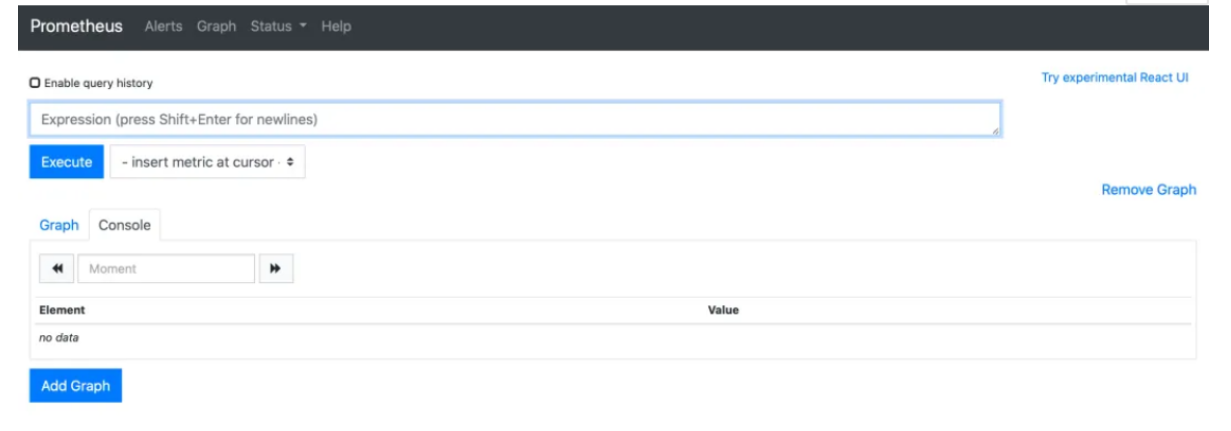
3.前端验证
启动后进行前端验证 访问成功效果显示如下(注:如访问不成功检查端口开放情况及防火墙状态)
http://192.128.xxx.xxx:9090 (IP:端口)
2.2配置安装node_exporter
node_exporter的作用是用于机器系统数据收集,监控服务器CPU、内存、磁盘、I/O等信息。安装在需要监控的服务器上
测试安装服务器:(注意:node_exporter 的运行用户也是 prometheus 用户需要在每台节点上都创建该用户。)
192.168.xxx.xxx
192.168.xxx.xxx
192.168.xxx.xxx
192.168.xxx.xxx
2.2.1下载安装
cd /usr/local/src/tools/ #该目录为自定义存放源码包目录
wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
tar -zxvf node_exporter-1.0.1.linux-amd64.tar.gz -C /usr/local/
mv node_exporter-1.0.1.linux-amd64/ node_exporter
2.2.2创建用户(如果已创建可以忽略)
groupadd prometheus
useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus
chown prometheus.prometheus -R /usr/local/node_exporter
2.2.3启动node_exporter
注:启动方式有以下两种建议选择第二种执行方式便于管理服务
1.直接执行node_exporter命令
cd /usr/local/node_exporter
nohup ./node_exporter &
ps -ef|grep node_exporter #查看后台进程状态
2.配置系统systemd服务(注:如已按上述命令启动需kill 掉当前后台运行进程 才能运行命令重启下列服务)
cat > /usr/lib/systemd/system/node_exporter.service <<EOF
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
启动node_exporter
systemctl daemon-reload
systemctl start node_exporter.service
systemctl enable node_exporter.service
systemctl status node_exporter.service

3.前端验证
http://192.168.xxx.xxx:9100/metrics、http://192.168.xxx.xxx:9100/metrics..........................
2.3Grafana安装
1.下载、安装
官网地址 https://grafana.com/grafana/download
找到对应系统版本运行如下命令:
源码包下载(可选)

wget https://dl.grafana.com/oss/release/grafana-7.5.7.linux-amd64.tar.gz
tar -zxvf grafana-7.5.7.linux-amd64.tar.gz
解压文件后文件目录
rpm 包下载(可选)

wget https://dl.grafana.com/oss/release/grafana-7.5.7-1.x86_64.rpm
sudo yum install grafana-7.5.7-1.x86_64.rpm
配置文件位于/etc/grafana/grafana.ini,这里暂时保持默认配置即可
2.启动 Grafana
systemctl enable grafana-server.service
systemctl start grafana-server.service
systemctl status grafana-server.service

3.前端验证及配置添加

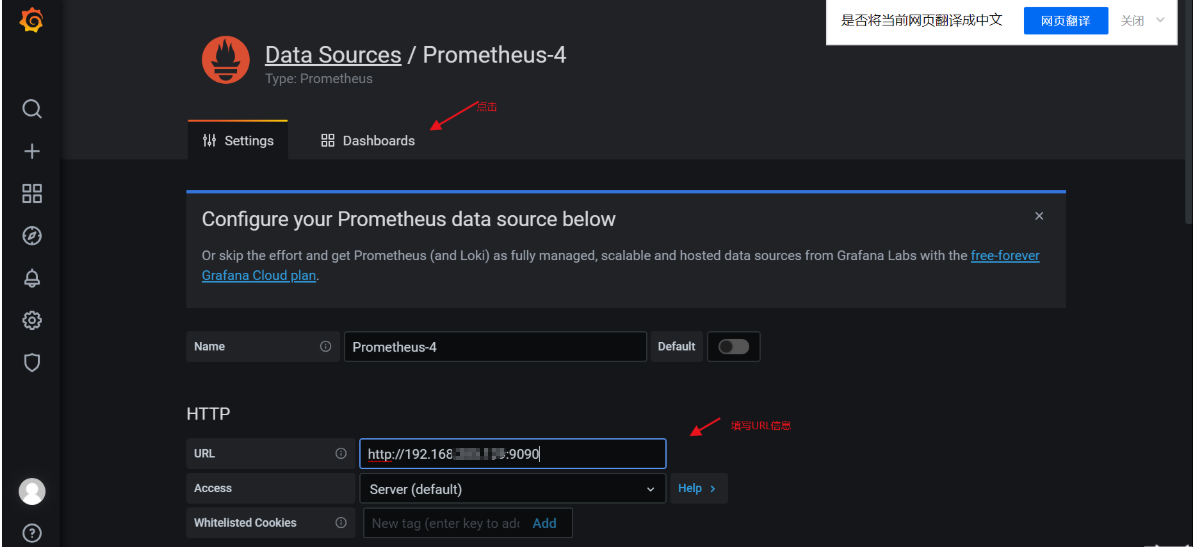
默认登录用户admin 密码 admin然后下一步会提示修改新的密码。重新登录后如下图,表示配置成功
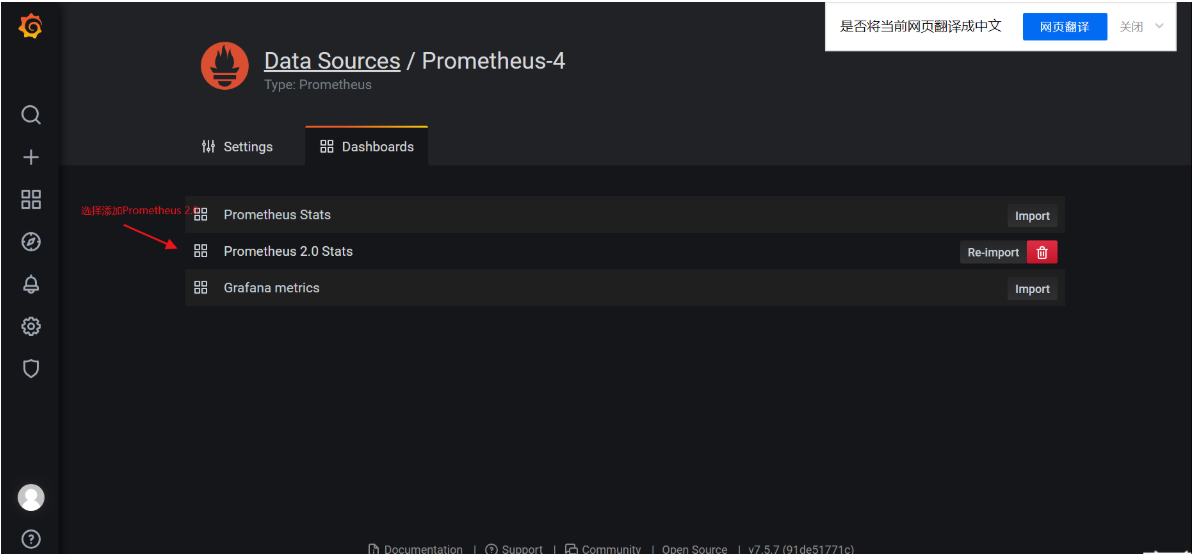
登录进去后会提示修改密码>>>>>>>>点击添加数据库>>>>>>>选择添加prometheus数据库>>>>>点击Doshboards>>>>>选择添加Promethus 2.0 >>>>>>完善URL路径信息后选择添加>>>>>>切换点击Doshboards



2.4greenplum_exporter安装
1.检查安装go语言编译器(前提)
cd /usr/local/src/tools/ #自定义源码文件包目录
wget https://gomirrors.org/dl/go/go1.14.12.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.14.12.linux-amd64.tar.gz
export PATH=$PATH:/usr/local/go/bin
go env -w GO111MODULE=on #修改go环境变量
go env -w GOPROXY=https://goproxy.io,direct
go env #查看当前go环境变量
注:完成安装go语言后可能会出现以下错误(错误原因 在64系统里执行32位程序)
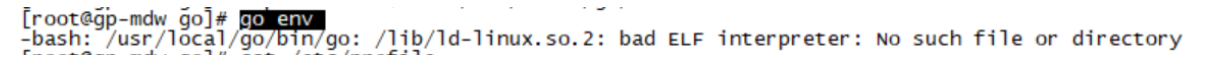
解决办法:
yum install glibc.i686
注:如有相关版本go语言环境,查找到当前go语言安装路径位置设置到环境变量中
go version #查看当前系统版本
find / -name golang* #查找当前按系统环境配置
vi /etc/profile
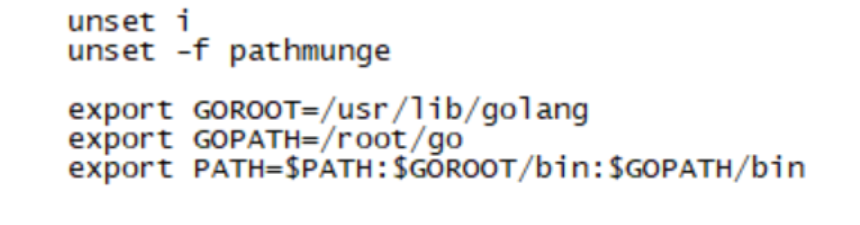
2.编译greenplum_exporter
git clone https://github.com/tangyibo/greenplum_exporter
cd greenplum_exporter/ && make build
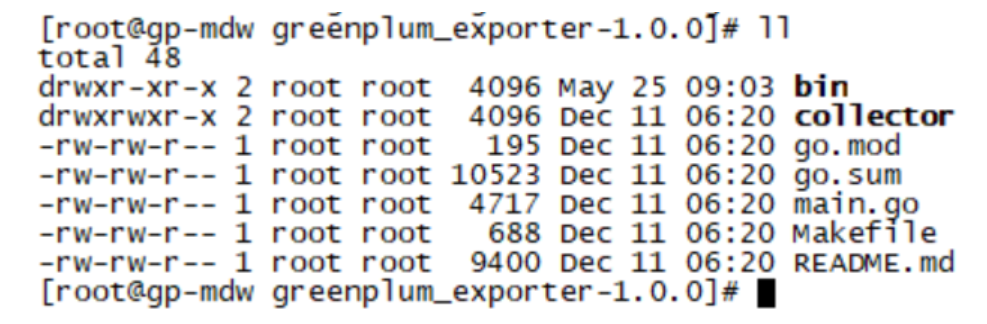
cd bin && ls -l
注:正常解压完后bin目录下会有greenplum_exporter启动程序

3.启动采集器greenplum_exporter
export GPDB_DATA_SOURCE_URL=postgres://gpadmin:123456@192.168.xxx.xxx:5432/postgres?sslmode=disable
nohup ./greenplum_exporter --web.listen-address="192.168.xxx.xxx:9297" --web.telemetry-path="/metrics" --log.level=error & #启动命令
注:环境变量GPDB_DATA_SOURCE_URL指定了连接Greenplum数据库的连接串(请使用gpadmin账号连接postgres库),该连接串以postgres://为前缀,具体格式如下:
postgres://gpadmin:password@192.168.xxx.xxx:5432/postgres?sslmode=disable
postgres://[数据库连接账号,必须为gpadmin]:[账号密码,即gpadmin的密码]@[数据库的IP地址]:[数据库端口号]/[数据库名称,必须为postgres]?[参数名]=[参数值]&[参数名]=[参数值]
也可配置编写脚本文件添加为开机自启
4.前端验证
访问greenplum_exporter的web界面http://192.168.xxx.xxx:9297/metrics (GP数仓启动才能采集到数据)

三、在Prometheus中配置Greenplum Exporter
prometheus的服务端通过pull向各个node_exporter节点端抓取信息,需要在各个node上安装exporter。可以利用 Prometheus 的 static_configs 来拉取 node_exporter 的数据。
1.编辑prometheus.yml文件
编辑一下文件,主要修改scrape_configs模块即可
vim /usr/local/prometheus/prometheus/prometheus.yml
添加内容
- job_name: 'gp-sdw1'
static_configs:
- targets: ['192.168.xxx.xxx:9100']
- job_name: 'gpeenplum'
static_configs:
- targets: ['192.168.xxx.xxx:9297']
- job_name: 'gp-mdw'
static_configs:
- targets: ['192.168.xxx.xxx:9100']
- job_name: 'gp-sdw2'
static_configs:
- targets: ['192.168.xxx.xxx:9100']
- job_name: 'gp-sdw3-mdw2'
static_configs:
- targets: ['192.168.xxx.xxx:9100']

2.添加完成后重启prometheus服务
ps -ef|grep prometheus
kill -9 当前进程
systemctl start prometheus.service
前端验证http://192.168.xxx.xxx:9090/targets
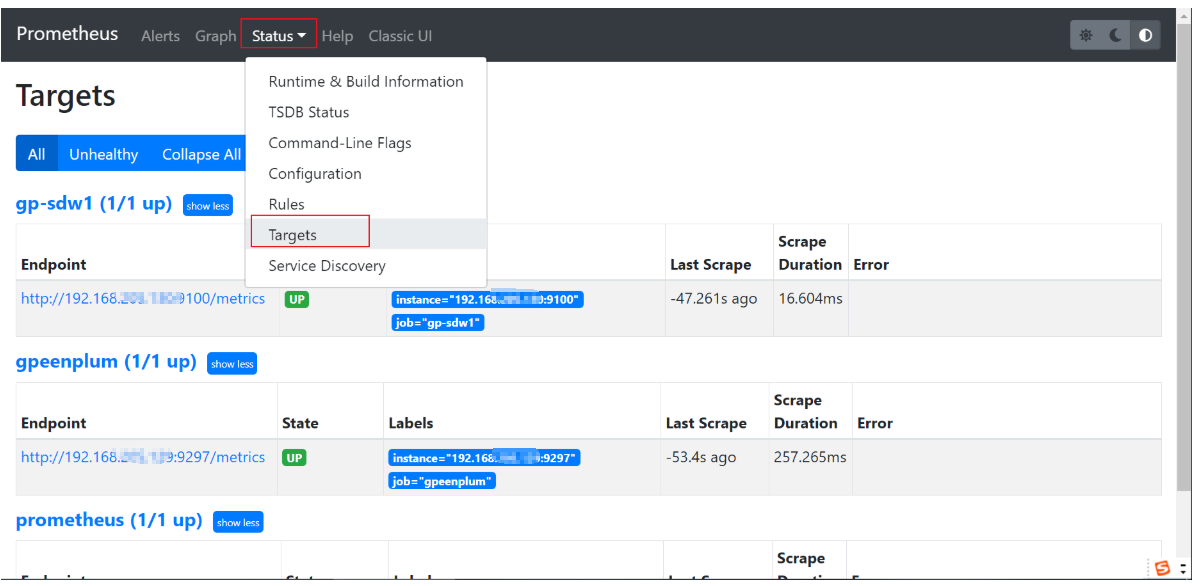
四、导入JSON 文件是实现greenplum_exporter、node_exporter监控指标
1.下载JSON 文件(示例控制台)
greenplum_exporter的JSON文件下载地址: https://grafana.com/grafana/dashboards/13822
node_exporter的JSON文件下载地址: https://grafana.com/grafana/dashboards/8919
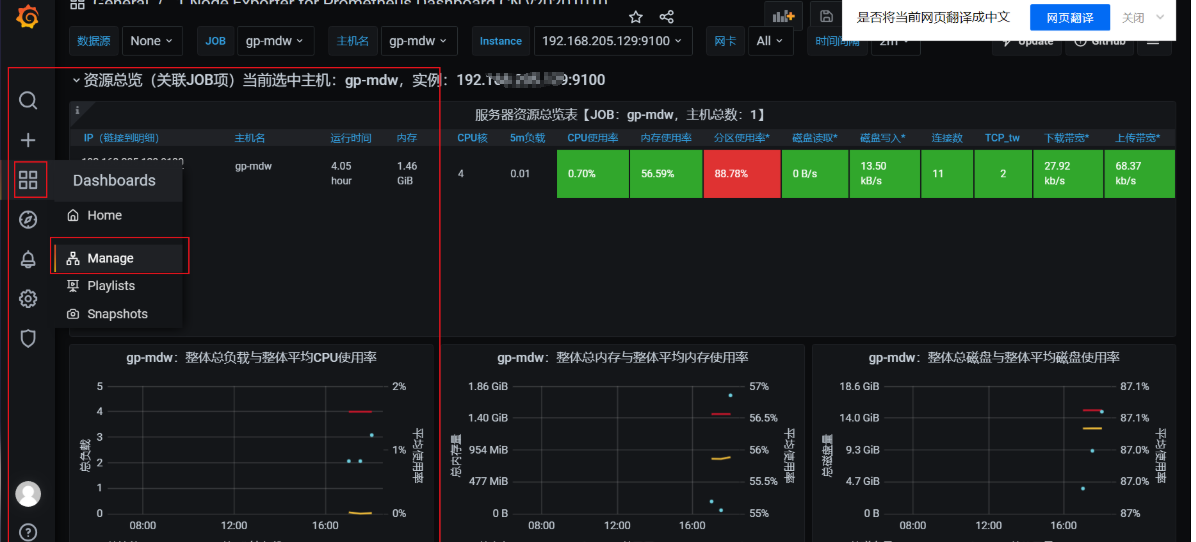
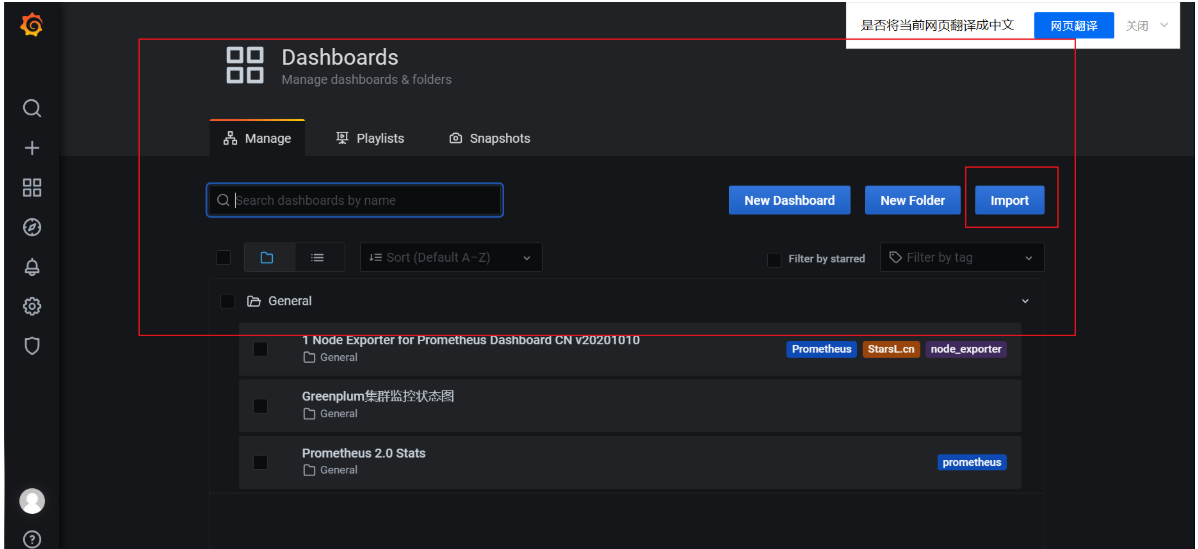
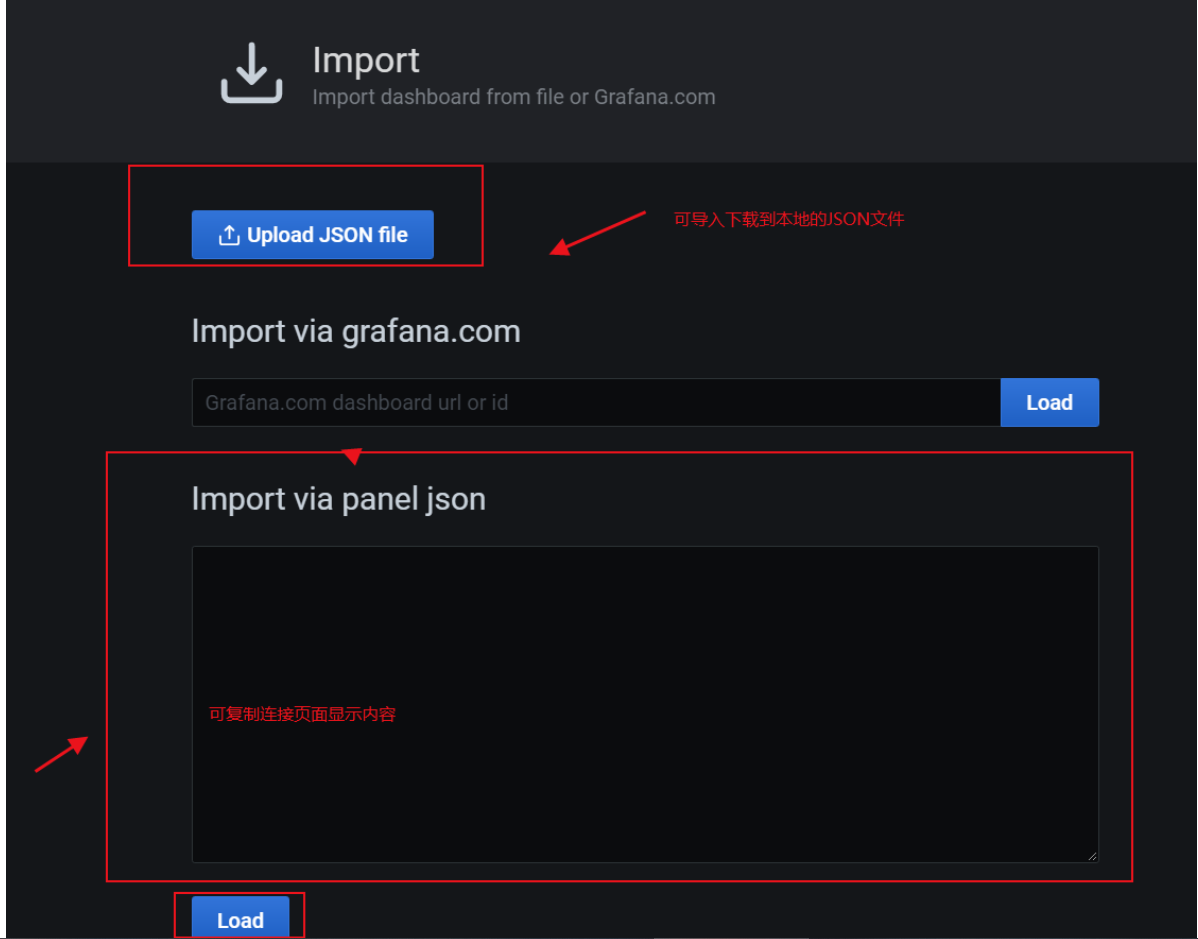
把文件导入到grafana中:Manage -- > Import --> Import via panel json(填入下载的JSON文件)
以下是导入文件后的效果,主要了解导入操作步骤,前端页面配置细节较多,有兴趣的同学也可搜索相关文章了解
能力有限,希望能给各位同学带来一定的帮助
Greenplum数仓监控解决方案(开源版本)的更多相关文章
- zabbix企业级的分布式开源监控解决方案 v5.0 LTS
目录 zabbix简介 服务模块 客户端守护进程 监控流程 功能拆解 安装 zabbix 5.0 LTS 参考官网 zabbix 5.0.12-1.el7 zabbix-server相关优化 1. 字 ...
- 成熟企业级开源监控解决方案Zabbix6.2关键功能实战-上
@ 目录 概述 定义 监控作用 使用理解 监控对象和指标 架构组成 常用监控软件分析 版本选型 俗语 安装 部署方式 部署 zabbix-agent 概述 定义 Zabbix 官网地址 https:/ ...
- Zabbix企业级开源监控解决方案
Zabbix企业级开源监控解决方案 目录 Zabbix企业级开源监控解决方案 一.Zabbix 1. 监控系统的必要性 2. 监控软件的作用 3. Zabbix的定义 4. Zabbix的监控原理 5 ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- 华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生. 伴随5G.大数据.AI.IoT的飞速发展,数据呈现大规模.多样性的极速增长 ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- CarbonData:大数据融合数仓新一代引擎
[摘要] CarbonData将存储和计算逻辑分离,通过索引技术让存储和计算物理上更接近,提升CPU和IO效率,实现超高性能的大数据分析.以CarbonData为融合数仓的大数据解决方案,为金融转型打 ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
- 数仓day02
1. 什么是ETL,ETL都是怎么实现的? ETL中文全称为:抽取.转换.加载 extract transform load ETL是传数仓开发中的一个重要环节.它指的是,ETL负责将分布的. ...
随机推荐
- GPU 高性能计算
背景 近日忽然想到,在CPU类型的服务器即使给到足够的运算资源,与GPU类型的服务器做运算来讲仍然是相差甚远,而本人有一台闲置的AMD vega8集显的电脑.想要用来做计算,来探究其与CPU运算的差别 ...
- 面试题五:Spring
Spring IoC 什么是IoC? 容器创建Bean对象,将他们装配在一起,配置并且管理它们的完整生命周期. Spring容器使用依赖注入来管理组成应用程序的Bean对象: 容器通过提供的配置元数据 ...
- linux学习之路第四天
用户和用户组的配置文件
- 2012年第三届蓝桥杯C/C++程序设计本科B组省赛题目 海盗比酒量 结果填空
** 一.题目 ** 海盗比酒量 有一群海盗(不多于20人),在船上比拼酒量.过程如下:打开一瓶酒,所有在场的人平分喝下,有几个人倒下了.再打开一瓶酒平分,又有倒下的,再次重复- 直到开了第4瓶酒,坐 ...
- java封装继承以及多态(含代码)
封装 该露的露,该藏的藏 我们常需设计要追求,"高内聚,低耦合".高内聚就是类的内部数据操作细节自己完成.不允许外部干涉:低耦合:仅暴漏少量的方法给外部使用. 封装(数据的隐藏) ...
- ftp错误&&详解方案
一.FTP错误代码列表150 文件状态良好,打开数据连接 200 命令成功 202 命令未实现 211 系统状态或系统帮助响应 212 目录状态 213 文件状态 214 帮助信息,信息仅对人类用户有 ...
- 2019年最新android常用开源库汇总上篇(转)
1.基本控件 1.1.TextView ScrollNumber ReadMoreTextView HtmlImage android-autofittextview html-textview Ba ...
- 个人博客开发之blog-api项目统一结果集api封装
前言 由于返回json api 格式接口,所以我们需要通过java bean封装一个统一数据返回格式,便于和前端约定交互, 状态码枚举ResultCode package cn.soboys.core ...
- ARTS第九周
1.Algorithm:每周至少做一个 leetcode 的算法题2.Review:阅读并点评至少一篇英文技术文章3.Tip:学习至少一个技术技巧4.Share:分享一篇有观点和思考的技术文章 以下是 ...
- Luogu P2051「AHOI2009」中国象棋
看见第一眼觉得是状压 \(\text{DP}\)?观察数据范围发现不可做 那按照最常规思路设状态试试? 设状态为\(dp[i][j]\)表示\(i*j\)的棋盘的方案数 好像转移不了欸 要不再来一维? ...