mongDB进阶
Mongo进阶
聚合
聚合操作将来自多个文档的值组合在一起,并且可以对分组数据执行各种操作以返回单个结果。
文档进入多阶段管道,将文档转换为聚合结果
聚合管道
例子:
第一阶段:过滤,$match
第二阶段:分组,$group
db.collectionName.aggregate([ { $match: { status: "A" } }, { $group: { _id: "$field1", total: { $sum: "$field2" } } } # 引号中$+字段表示字段路径,说明是对该字段下的值进行操作 ])
聚合管道由多个阶段组成
聚合方法
db.collectionName.aggregate():提供聚合管道的访问
db.collectionName.mapReduce():对大型数据集执行map-reduce聚合
变量
用户变量
要访问变量的 value,请使用带有前缀为 ($$)的变量名的 string。
如果变量 references 一个 object,要访问 object 中的特定字段,使用$$<variable>.<field>
系统变量
$$ROOT
$$CURRENT
$$REMOVE
$$DESCEND
$$PRUNE
$$KEEP
Map-reudce
MongoDB 中的所有 map-reduce 函数都是JavaScript,在mongod进程中运行
map-reduce 操作可以将结果写入集合或内联返回结果
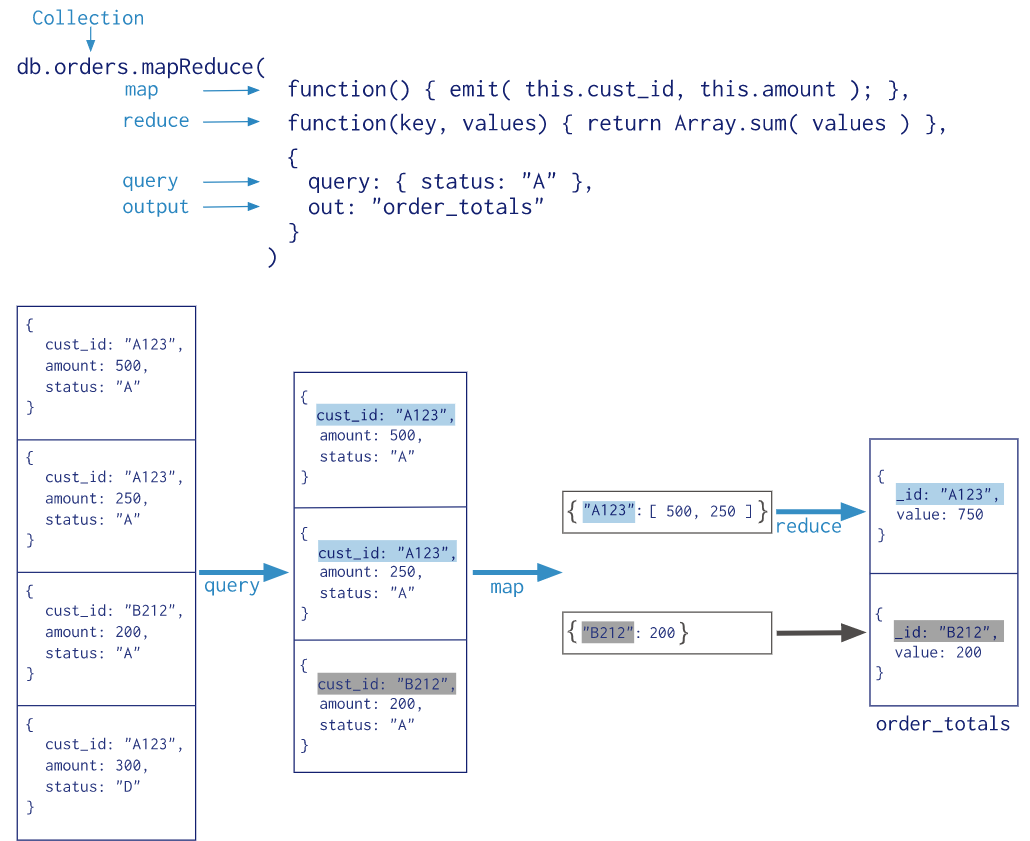
db.collection.mapReduce( function() {emit(key,value);}, //map 函数 function(key,values) {return reduceFunction}, //reduce 函数 { out: collection, query: document, sort: document, limit: number } )
map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
reduce :统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
out :统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
query: 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
sort :和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
limit :发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
参考
关联
DBRef
{ $ref : <value>, $id : <value>, $db : <value> }
$ref:引用的集合名称
$id:引用的id
$db:数据库名称
例子
> db.posts.insert({"title":"Hello Mongodb DBRef1",authors:[new DBRef('authors',author._id)]})
# posts集合插入一个文档,该文档中的authors记录的是集合author中的id
# 相当于posts集合给authors字段设置外键
$lookup
db.product.aggregate([ { $lookup: { from: "orders", # 需要关联的集合 localField: "_id", # 本集合需要关联的字段 foreignField: "pid", # 外键字段 as: "inventory_docs":对应外键集合的数据,即orders的数据 } } ])
原子操作
| 常用命令 | 描述 | 例子 |
|---|---|---|
| $set | 用来指定一个键并更新键值,若键不存在并创建 | { $set : { field : value } } |
| $unset | 删除一个键 | { $unset : { field : 1} } |
| $inc | 增减的操作 | { $inc : { field : value } } |
| $push | 把value追加到field里面去,field一定要是数组类型才行,如果field不存在,会新增一个数组类型加进去 | { $push : { field : value } } |
| $pushAll | 同$push,只是一次可以追加多个值到一个数组字段内 | { $pushAll : { field : value_array } } |
| $pull | 从数组field内删除一个等于value值 | { $pull : { field : _value } } |
| $addToSet | 增加一个值到数组内,而且只有当这个值不在数组内才增加 | |
| $pop | 删除数组的第一个或最后一个元素 | { $pop : { field : 1 } } |
| $rename | 修改字段名称 | { $rename : { old_field_name : new_field_name } } |
| $bit | 位操作 | {$bit : { field : {and : 5}}} |
索引
索引可以提高读操作的效率
创建索引
db.collectionName.createIndex( <key and index type specification>, <options> )
选项
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
例子:db.values.createIndex({open: 1, close: 1}, {background: true,name: myindex})
复制
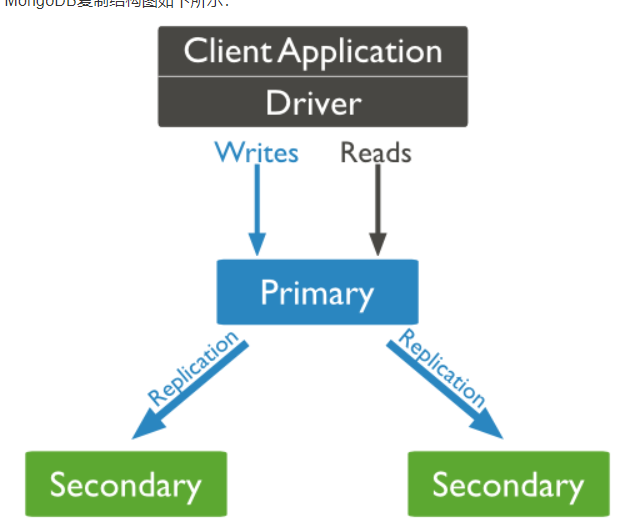
副本集(replica set)特征:
N 个节点的集群
任何节点可作为主节点
所有写入操作都在主节点上
自动故障转移
自动恢复
副本集设置
开启服务并为其命名
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
rs.initiate():启动一个新的副本集。
rs.conf():来查看副本集的配置
rs.status() :查看副本集状态
rs.add(INSTANCE_NAME:PORT):添加成员
db.isMaster() :是否位主节点
分片(shard)
一种将数据分配到多个机器上的方法,实现水平扩展
为什么使用分片
复制所有的写入操作到主节点
延迟的敏感数据会在主节点查询
单个副本集限制在12个节点
当请求量巨大时会出现内存不足。
本地磁盘不足
垂直扩展价格昂贵
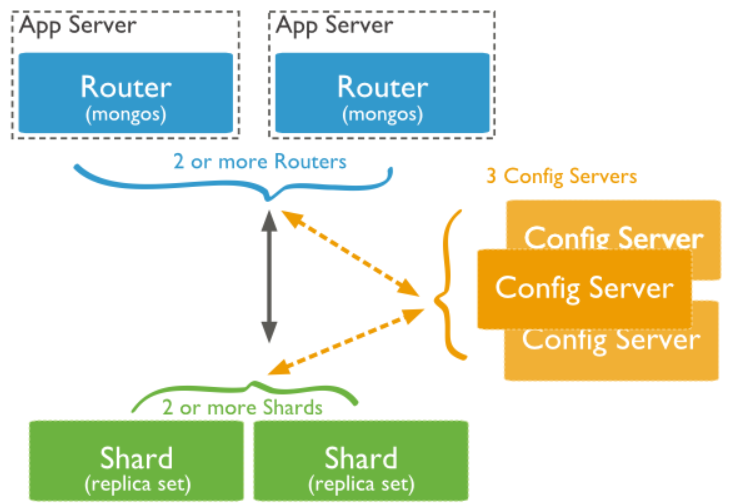
Shard:用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组成一个replica set承担,防止主机单点故障
Config Server:mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
Query Routers:前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
实例
分片结构如下(需要启动三种服务)
Shard Server 1:27020
Shard Server 2:27021
Shard Server 3:27022
Shard Server 4:27023
--------------------
Config Server :27100
--------------------
Route Process:40000
此例是为方便展示使用不同端口来区分切片服务,实际应用中可以通过不同的host,在不同的机器中创建和启动
Shard Server
# 创建切片服务的数据存储文件夹
[root@100 /]# mkdir -p /www/mongoDB/shard/s{1,2,3,4}
# 创建切片服务的日志文件夹
[root@100 /]# mkdir -p /www/mongoDB/shard/log
在指定的一个路径下分别创建服务启动的配置文件,比如
vim /usr/mongoDB/shard/s1.conf
port=27020 #指定服务端口
dbpath=/www/mongoDB/shard/s1 #数据存储目录
logpath=/www/mongoDB/shard/log/s1.log #日志文件
logappend=true #使用追加方式写日志
fork=true #后台运行
maxConns=5000 #设定最大同时连接数,默认为2000
storageEngine=mmapv1 #指定存储引擎为内存映射文件
shardsvr=true # 分片服务
启动服务
# 启动shard服务
[root@100 /]# /usr/local/mongoDB/bin/mongod -f /usr/mongoDB/shard/s1.conf
....
[root@100 /]# /usr/local/mongoDB/bin/mongod -f /usr/mongoDB/shard/s4.conf
Config Server
[root@100 /]# mkdir -p /www/mongoDB/shard/config
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
--------------------------
vim /usr/mongoDB/shard/config.conf
port=27100
dbpath=/www/mongoDB/shard/config
logpath=/www/mongoDB/shard/log/config.log
logappend=true
fork=true
maxConns=5000
storageEngine=mmapv1
configsvr=true #配置服务
--------------------------
# 启动config服务
[root@100 /]# /usr/local/mongoDB/bin/mongod -f /usr/mongoDB/shard/config.conf
Route Progress
# 启动路由服务
[root@100 /]#/usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 19
chunkSize这一项是用来指定chunk的大小的,单位是MB,默认大小为200MB
在Route Progress服务处登陆
[root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000
添加分片节点
mongos> sh.addshard("localhost:27020")
mongos> sh.addshard("localhost:27021")
mongos> sh.addshard("localhost:27022")
mongos> sh.addshard("localhost:27023")
使库有分片能力
mongos> sh.enablesharding("dbName")
使集合分片
#指定文档中数据库对应的表通过什么分片.使表根据field1和field2分片
mongos>sh.shardcollection("dbName.collectionName",{"field1":1,"field2":1}})
添加标签
sh.addShardTag("shard0000","Master")
sh.addShardTag("shard0001","s1")
sh.addShardTag("shard0002","s2")
sh.addShardTag("shard0003","s3")
sh.addShardTag("shard0004","s4")
测试
mongos> sh.status() # 查看分片状态信息
mongos> user dbName
mongos> for (var i=1;i<=50000;i++)dbName.collectionName.insert({"id":i,"name":"tom"+i}) # 写入数据查看结果
删除分片
mongos> db.runCommand("removeShard":"localhost:27023")
备份与恢复
备份
mongodump -h dbhost -d dbname -o dbdirectory
恢复
mongorestore -h <hostname><:port> -d dbname <path>
不需要登陆mongo
mongDB进阶的更多相关文章
- linux部署mongodb及基本操作
原文:http://blog.csdn.net/jinzhencs/article/details/50930877 一.安装部署mongo 1.创建文件夹 /opt/mongodb/single / ...
- MongoDb进阶实践之六 MongoDB查询命令详述(补充)
一.引言 上一篇文章我们已经介绍了MongoDB数据库的查询操作,但是并没有介绍全,随着自己的学习的深入,对查询又有了新的东西,决定补充进来.如果大家想看上一篇有关MongoDB查询的 ...
- nmap进阶使用[脚本篇]
nmap 进阶使用 [ 脚本篇 ] 2017-05-18 NMAP 0x01 前言 因为今天的重点并非nmap本身使用,这次主要还是想给大家介绍一些在实战中相对比较实用的nmap脚本,所以关于 ...
- nodejs进阶(6)—连接MySQL数据库
1. 建库连库 连接MySQL数据库需要安装支持 npm install mysql 我们需要提前安装按mysql sever端 建一个数据库mydb1 mysql> CREATE DATABA ...
- nodejs进阶(4)—读取图片到页面
我们先实现从指定路径读取图片然后输出到页面的功能. 先准备一张图片imgs/dog.jpg. file.js里面继续添加readImg方法,在这里注意读写的时候都需要声明'binary'.(file. ...
- JavaScript进阶之路(一)初学者的开始
一:写在前面的问题和话 一个javascript初学者的进阶之路! 背景:3年后端(ASP.NET)工作经验,javascript水平一般般,前端水平一般般.学习资料:犀牛书. 如有误导,或者错误的地 ...
- nodejs进阶(3)—路由处理
1. url.parse(url)解析 该方法将一个URL字符串转换成对象并返回. url.parse(urlStr, [parseQueryString], [slashesDenoteHost]) ...
- nodejs进阶(5)—接收请求参数
1. get请求参数接收 我们简单举一个需要接收参数的例子 如果有个查找功能,查找关键词需要从url里接收,http://localhost:8000/search?keyword=地球.通过前面的进 ...
- nodejs进阶(1)—输出hello world
下面将带领大家一步步学习nodejs,知道怎么使用nodejs搭建服务器,响应get/post请求,连接数据库等. 搭建服务器页面输出hello world var http = require ...
随机推荐
- PCIE笔记--PCIe错误定义与分类
转载地址:http://blog.chinaaet.com/justlxy/p/5100057782 前面的文章提到过,PCI总线中定义两个边带信号(PERR#和SERR#)来处理总线错误.其中PER ...
- dhcpd 启动失败No subnet declaration for wlan0
今天在调试机器的WIFI热点,好不容易把dhcp编译打包进去,服务启动出现报错No subnet declaration for wlan0,详细信息如下: Internet Systems Cons ...
- SkyWalking部署及.Net Core简单使用
SkyWalking官方网站非常详细,以下只是本人学习过程的整理 一.SkyWalking简介 1.概念 SkyWalking是分布式系统的应用程序性能监视工具,专为微服务.云原生架构而设计 SkyW ...
- 使用python操作HDF5文件
HDF Hierarchical Data Format,又称HDF5 在深度学习中,通常会使用巨量的数据或图片来训练网络.对于如此大的数据集,如果对于每张图片都单独从硬盘读取.预处理.之后再送入网络 ...
- 【Java】数组Array
Java基础复习之:数组 简介 数组(Array):多个相同数据类型按照一定顺序排列的集合,并使用一个名字命名,通过编号的方式对这些数据进行统一管理 一维数组 一维数组的声明与初始化 int[] id ...
- Could not set property 'id' of 'class com.xxx.xxEntity'
使用mybatisplus的save功能时,系统报错如下: Could not set property 'id' of 'class com.xxx.xxEntity' with value '13 ...
- 一看就懂的IdentityServer4认证授权设计方案
查阅了大多数相关资料,总结设计一个IdentityServer4认证授权方案,我们先看理论,后设计方案. 1.快速理解认证授权 我们先看一下网站发起QQ认证授权,授权通过后获取用户头像,昵称的流程. ...
- Spark中资源调度和任务调度
Spark比MR快的原因 1.Spark基于内存的计算 2.粗粒度资源调度 3.DAG有向无环图:可以根据宽窄依赖划分出可以并行计算的task 细粒度资源调度 MR是属于细粒度资源调度 优点:每个ta ...
- MySQL基础语句(MySQL内置函数 )
MySQL 字符串函数 函数 描述 实例 ASCII(s) 返回字符串 s 的第一个字符的 ASCII 码. 返回 CustomerName 字段第一个字母的 ASCII 码: SELECT ASCI ...
- OpenStack平台的使用
一.OpenStack平台的使用 使用双节点部署,192.168.16.10为控制节点.192.168.16.20为计算节点. (一).创建镜像 1.在控制节点中找到qcow2镜像 [root@con ...