HDFS03 HDFS的API操作
HDFS的API操作
之前时用Shell的一写相关操作,集群内部操作。
我们希望在Windows环境对远程的集群进行一个客户端访问,现在就在Windows环境上写代码,写HDFS客户端代码,远程连接上集群,对它们进行增删改查相关操作。
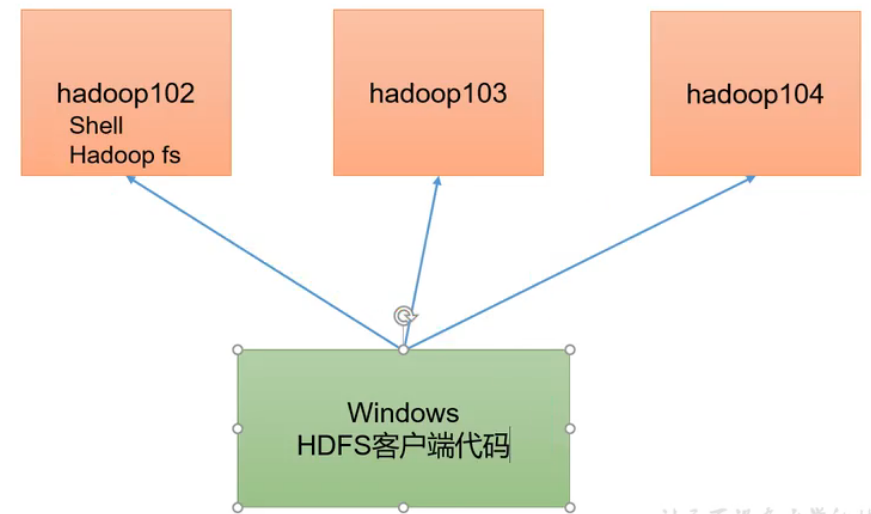
客户端环境准备
1.下载windows支持的hadoop
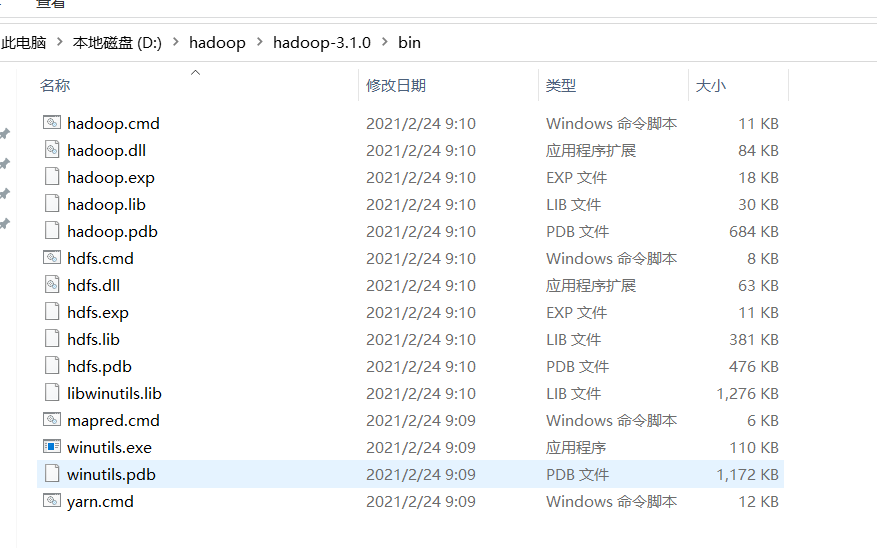
2.配置环境变量
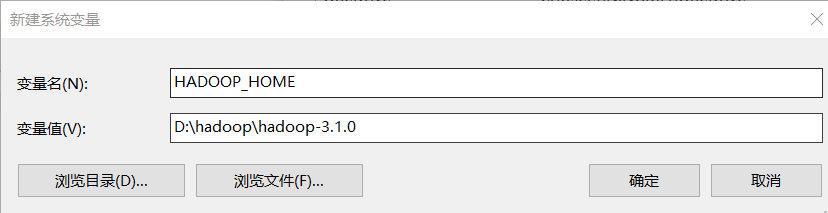
验证Hadoo环境变量是否正常,双击winutils.exe,没有报错就成功了。
3 在IDEA中创建一个Maven工程
1.创建一个maven工程
2.setting设置maven
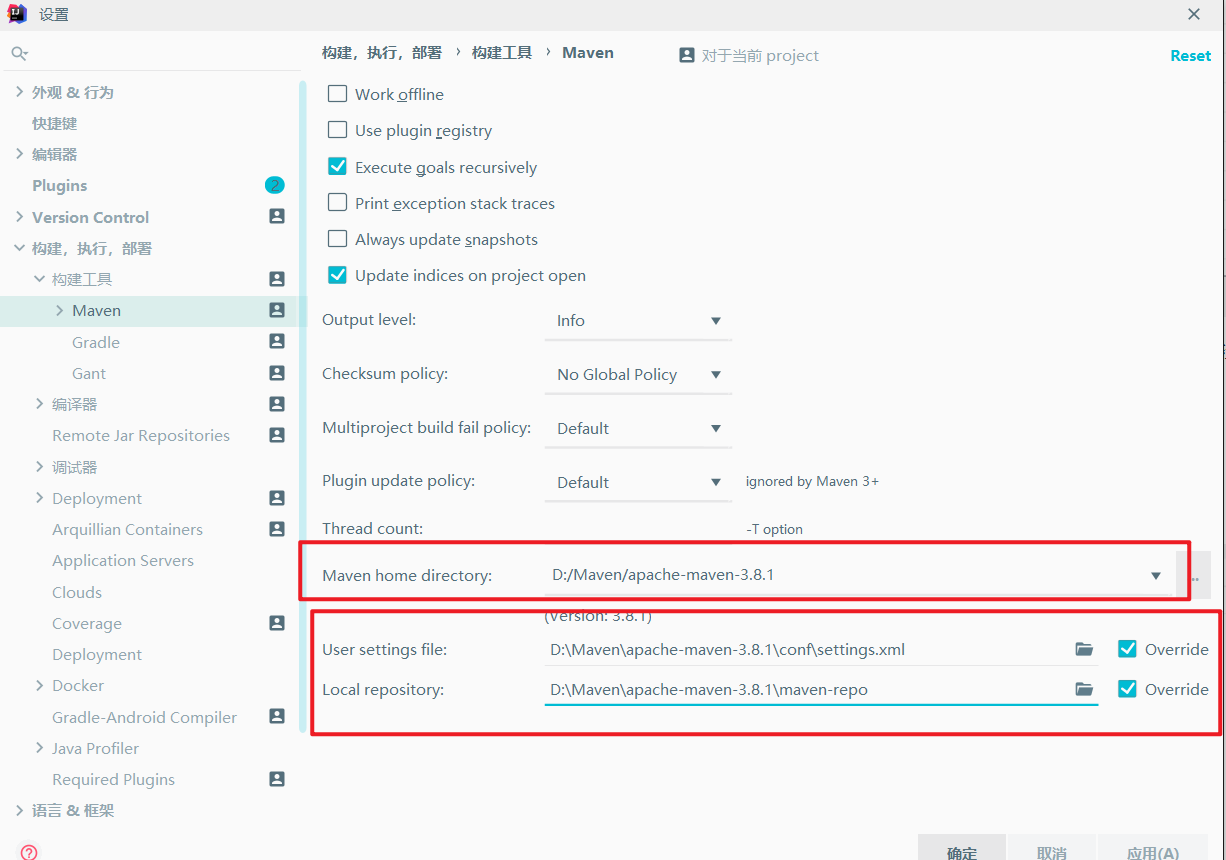
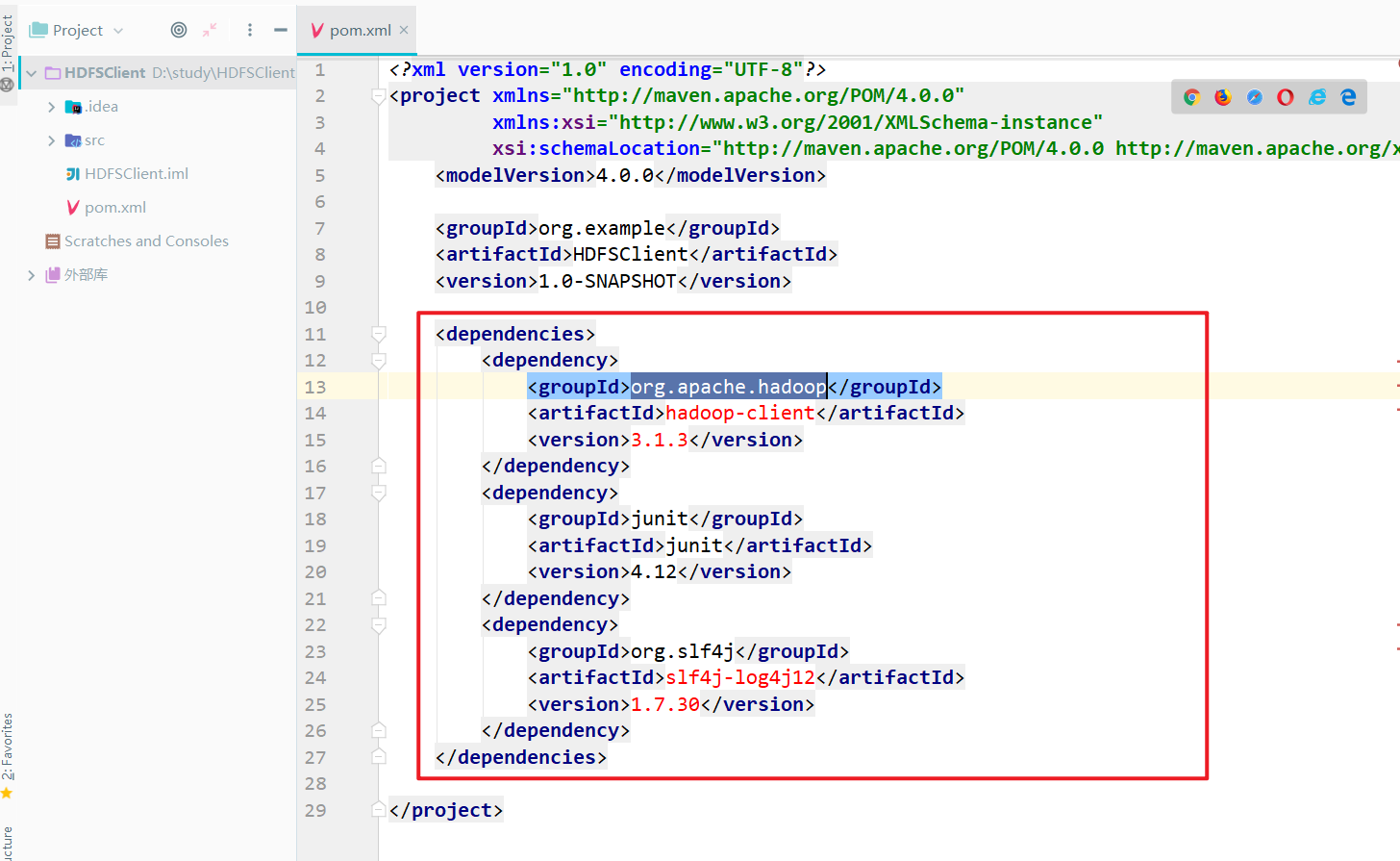
3.添加相关依赖
日志(打印日志时控制级别)、单元测试、hadoop(版本号一定要和集群中的一样)
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
4.在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,为了打印日志,添加如下代码
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5.在src/main/java下创建包名:com.ranan.hdfs
6.在该类下创建HdfsClient类
创建好了客户端类,接下来写代码操作远程的服务器集群
7.客户端去操作HDFS时,默认采用windows默认用户去访问HDFS,会报权限异常错误。所以在访问 HDFS 时,一定要配置用户。
org.apache.hadoop.security.AccessControlException: Permission denied: user=NINGMEI, access=WRITE, inode="/":ranan:supergroup:drwxr-xr-x
HDFS的API实例
1.获取一个客服端对象
2.执行相关的操作命令
3.关闭资源
用客户端远程创建目录
@Test
public void testmkdir() throws IOException, URISyntaxException, InterruptedException {
//连接集群的nn内部地址
URI uri = new URI("hdfs://hadoop102:8020");
//创建一个配置文件
Configuration configuration = new Configuration();
//用户
String user = "ranan";
//1.获取客户端对象 FileSystem抽象类
FileSystem fs = FileSystem.get(uri, configuration,user);
//2.执行相关操作 创建的文件路径
fs.mkdirs(new Path("/xiyou/huaguoshan"));
//3.关闭资源
fs.close();
}
下面会频繁的初始化、获取客服端对象以及关闭资源。所以把封装起来。
//因为是测试方法,所以使用befor,after。先执行befor在执行test最后after
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//连接集群的nn内部地址
URI uri = new URI("hdfs://hadoop102:8020");
//创建一个配置文件
Configuration configuration = new Configuration();
//用户
String user = "ranan";
//1.获取客户端对象
fs = FileSystem.get(uri, configuration,user);
}
@After
public void close() throws IOException {
//3.关闭资源
fs.close();
}
@Test
public void testmkdir() throws IOException {
//2.执行相关操作
fs.mkdirs(new Path("/xiyou/huaguoshan"));
}
}
HDFS用客户端上传文件copyFromLocalFile
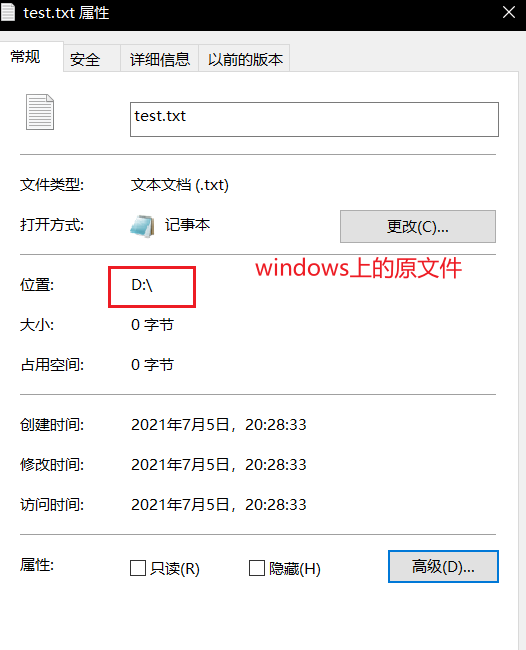
@Test
public void testPut() throws IOException {
//2.执行相关操作
/*
参数1:删除原文件
参数2:HDFS上是否允许覆盖
参数3:原数据路径
参数4:目的路径
*/
fs.copyFromLocalFile(false,false,new Path("D:\\test.txt"),new Path("/"));
}
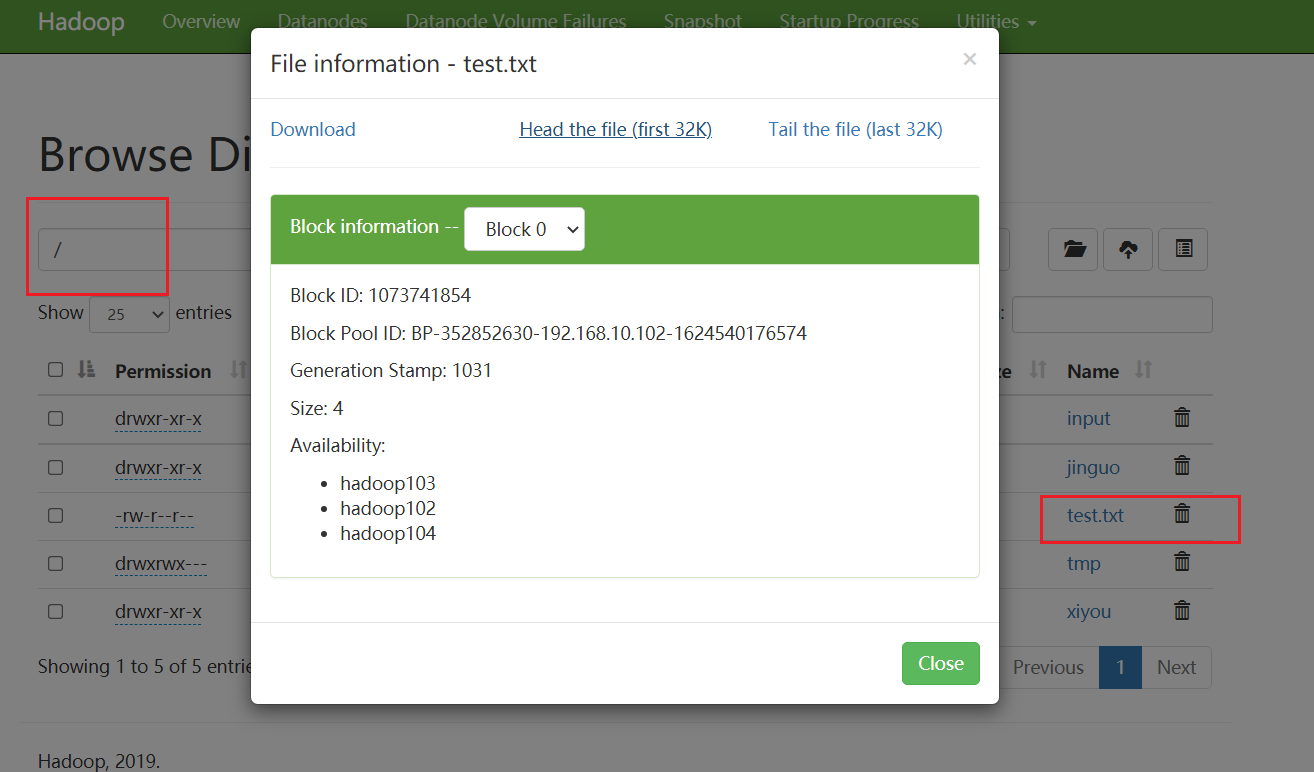
参数优先级
优先级由低到高
hdfs-default.xml -> hdfs-site.xml -> 在项目资源目录下的配置文件 -> 代码里的配置
测试案例1
在resources下新建一个file——hdfs-site.xml
在hdfs-site.xml中修改副本数为1
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
副本数变成1了,说明 resources 资源目录下的hdfs-site.xml 优先级更高
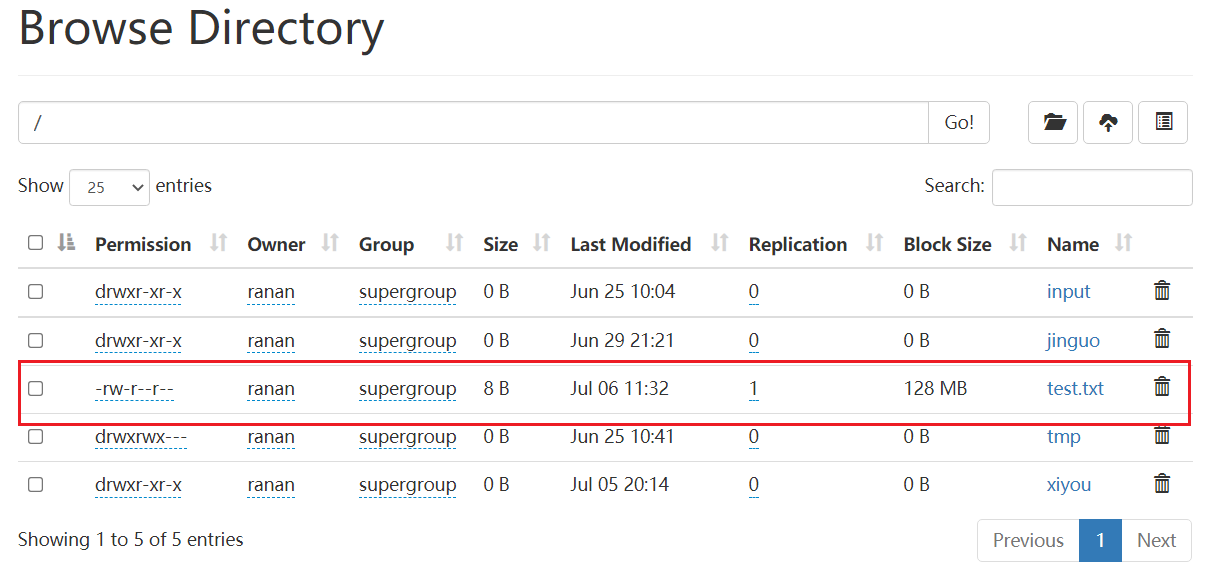
测试案例2
在客户端代码中配置副本数
configuration.set("dfs.replication","2");
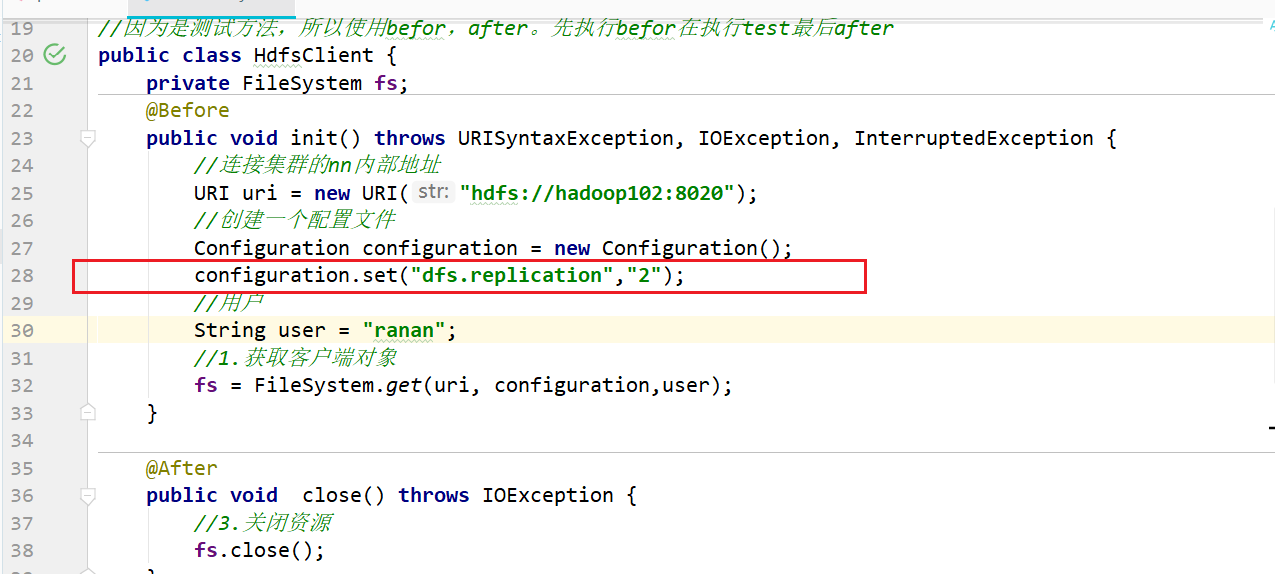
副本数变成2,说明代码里的配置优先级更高。
HDFS用客户端下载文件copyToLocalFile
编写代码
@Test
public void testGet() throws IOException {
//2.执行相关操作
/*
参数1:是否删除HDFS上的原文件
参数2:HDFS上原文件的路径
参数3:目的路径
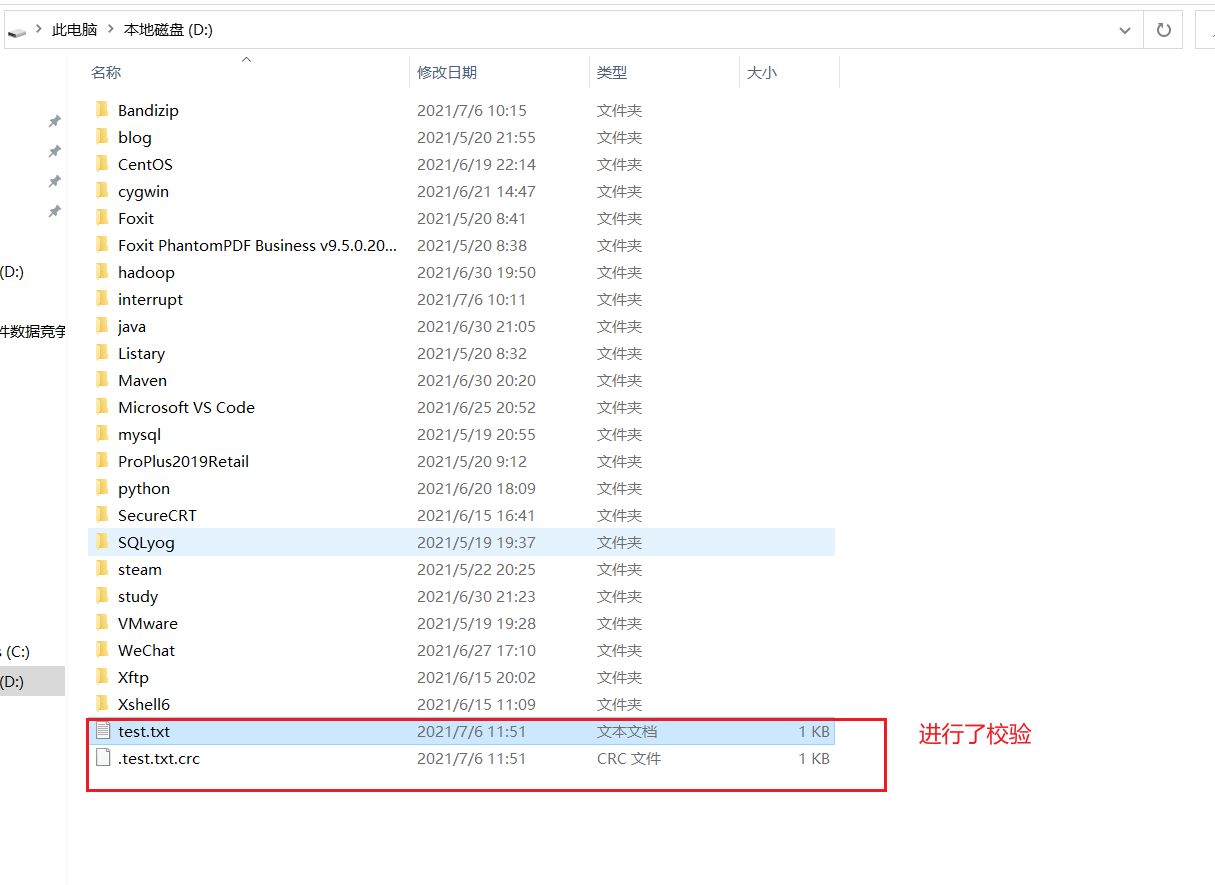
参数4:是否开启本地文件的校验,在传输的过程中验证文件是否完整传输
*/
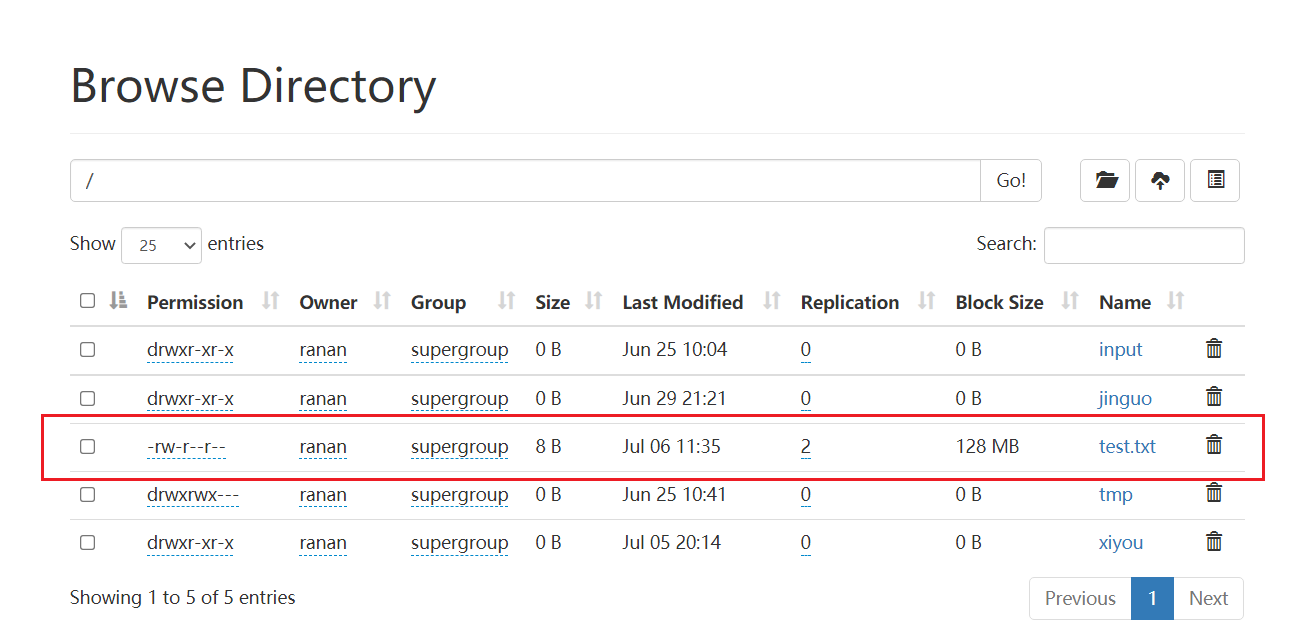
fs.copyToLocalFile(false,new Path("hdfs://hadoop102/test.txt"),new Path("D:"),true);
}
执行结果
HDFS用客户端删除文件delete
编写代码
@Test
public void testDel() throws IOException {
//2.执行相关操作
/*
参数1:HDFS上要删除的路径
参数2:是否递归删除 非空目录需要递归删除
*/
fs.delete(new Path("/xiyou"),true);
}
HDFS用客户端更名和移动文件rename
重命名代码
@Test
public void testMv() throws IOException {
//2.执行相关操作
/*
参数1:要修改的文件路径
参数2:移动的目的地,如果和原文件一个路径则修改名称
*/
fs.rename(new Path("/test.txt"),new Path("/test1.txt"));
}
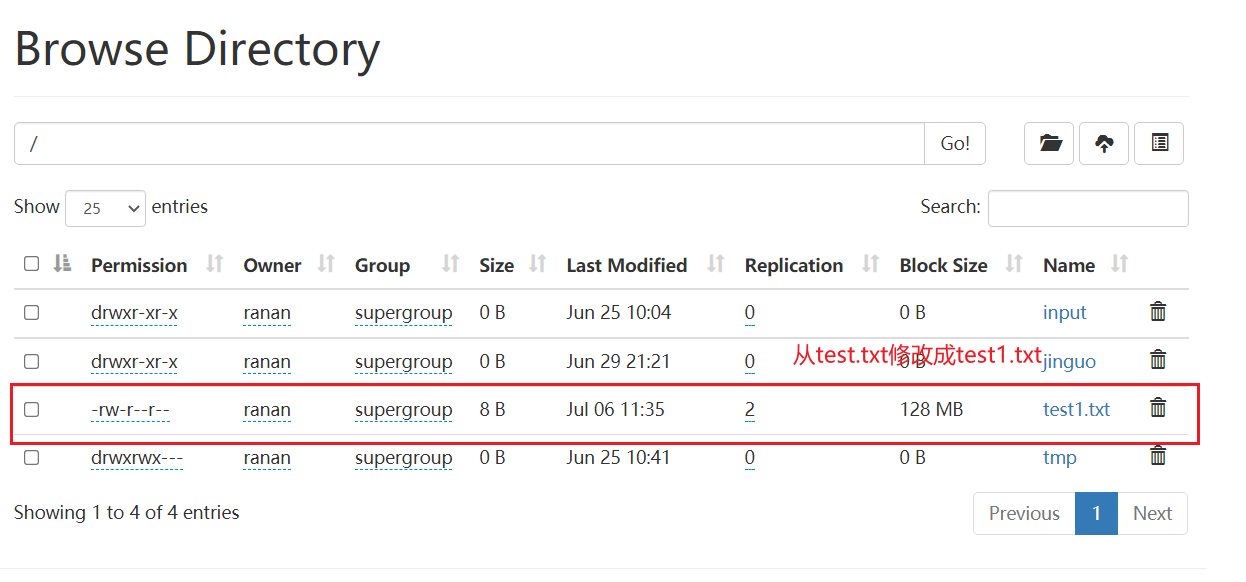
移动代码
@Test
public void testMv() throws IOException {
//2.执行相关操作
/*
参数1:要修改的文件路径
参数2:移动的目的地,如果和原文件一个路径则修改名称
*/
fs.rename(new Path("/test1.txt"),new Path("/tmp/test.txt"));
}
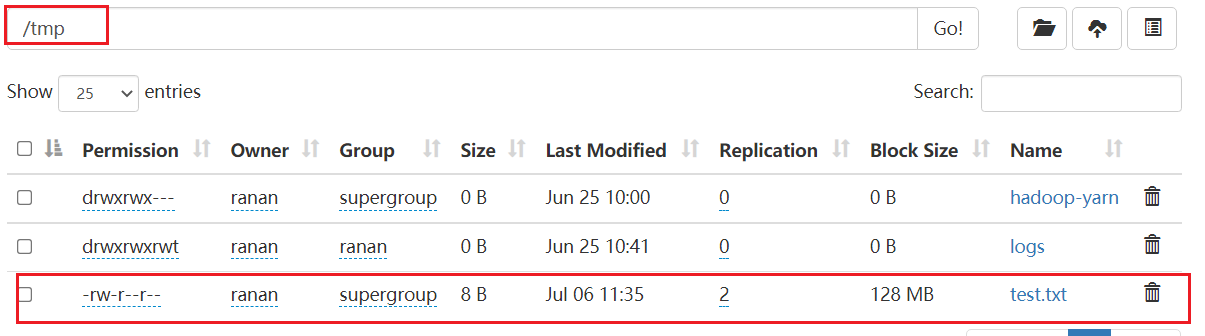
HDFS用客服端查看文件详情listFiles
查看文件名称、权限、长度、块信息
代码
@Test
public void fileDetail() throws IOException {
//2.执行相关操作
/*
参数1:查看文件的路径
参数2:递归
*/
// 获取所有文件信息,返回迭代器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
// 遍历文件
while (listFiles.hasNext()) {
//每个文件相关信息
LocatedFileStatus fileStatus = listFiles.next();
//每个文件的路径
System.out.println("==========" + fileStatus.getPath() + "=========");
//每个文件的权限
System.out.println(fileStatus.getPermission());
//每个文件的所有者
System.out.println(fileStatus.getOwner());
//所属组
System.out.println(fileStatus.getGroup());
//文件大小
System.out.println(fileStatus.getLen());
//上次修改时间
System.out.println(fileStatus.getModificationTime());
//副本数
System.out.println(fileStatus.getReplication());
//块大小
System.out.println(fileStatus.getBlockSize());
//文件名称
System.out.println(fileStatus.getPath().getName());
// 获取块信息 [0(第一块数据从哪开始读),30(第一块数据读到哪里结束),hadoop102,hadoop103,hadoop104] 每个块的存储位置
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
HDFS文件和文件夹判断listStatus
案例
循环遍历文件夹,判断该文件夹里的内容是文件还是目录
@Test
public void testFile() throws IOException {
//2.执行相关操作
/*
参数1:遍历的文件夹
*/
//得到/下的内容
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus status : listStatus) {
//getPath().getName()获得文件/目录名
if (status.isFile()) {
System.out.println("文件:" + status.getPath().getName());
} else {
System.out.println("目录:" + status.getPath().getName());
}
}
}
HDFS03 HDFS的API操作的更多相关文章
- 【Hadoop离线基础总结】HDFS的API操作
HDFS的API操作 创建maven工程并导入jar包 注意 由于cdh版本的所有的软件涉及版权的问题,所以并没有将所有的jar包托管到maven仓库当中去,而是托管在了CDH自己的服务器上面,所以我 ...
- 客户端操作 2 HDFS的API操作 3 HDFS的I/O流操作
2 HDFS的API操作 2.1 HDFS文件上传(测试参数优先级) 1.编写源代码 // 文件上传 @Test public void testPut() throws Exception { Co ...
- hadoop hdfs java api操作
package com.duking.util; import java.io.IOException; import java.util.Date; import org.apache.hadoop ...
- HDFS常用API操作 和 HDFS的I/O流操作
前置操作 创建maven工程,修改pom.xml文件: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xs ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- HDFS Java API 常用操作
package com.luogankun.hadoop.hdfs.api; import java.io.BufferedInputStream; import java.io.File; impo ...
- Hadoop学习记录(3)|HDFS API 操作|RPC调用
HDFS的API操作 URL方式访问 package hdfs; import java.io.IOException; import java.io.InputStream; import java ...
- 三、hdfs的JavaAPI操作
下文展示Java的API如何操作hdfs,在这之前你需要先安装配置好hdfs https://www.cnblogs.com/lay2017/p/9919905.html 依赖 你需要引入依赖如下 & ...
随机推荐
- 攻防世界 web5.disabled_button
我觉得戴上手套按应该可以! 方法一: 打开网址,发现flag按钮无法点击,F12查看源代码,删除disabled=" ",flag就点击了. 方法二 POST请求, 先分析一下源代 ...
- 看动画学算法之:双向队列dequeue
目录 简介 双向队列的实现 双向队列的数组实现 双向队列的动态数组实现 双向队列的链表实现 双向链表的时间复杂度 简介 dequeue指的是双向队列,可以分别从队列的头部插入和获取数据,也可以从队列的 ...
- objcopy使用
objcopy - copy and translate object files:用于二进制文件的拷贝和翻译(转化) objcopy的man文件如下所示: objcopy [-F bfdname|- ...
- UVA 10004 Bicoloring(DFS染色)
题意: 给N个点构成的无环无向图,并且保证所有点对都是连通的. 给每个点染色,要么染成黑要么染成白.问是否存在染色方案使得所有有边相连的点对颜色一定不一样. 是输出 BICOLORABLE 否则输出 ...
- 『与善仁』Appium基础 — 5、常用ADB命令(二)
目录 9.查看手机运行日志 (1)Android 日志 (2)按级别过滤日志 (3)按 tag 和级别过滤日志 (4)日志格式 (5)清空日志 10.获取APP的包名和启动名 方式一: 方式二: 11 ...
- scrapy 的response 的相关属性
Scrapy中response介绍.属性以及内容提取 解析response parse()方法的参数 response 是start_urls里面的链接爬取后的结果.所以在parse()方法中,我 ...
- ORA-01756: quoted string not properly terminated
导入sql文件报错:ORA-01756: quoted string not properly terminated 字符集的中英文问题: 临时解决方法:export NLS_LANG=AMERICA ...
- 2021.11.2-测试T1数独
痛苦 题目 数 独 [问题描述] 给定一个9*9矩阵,对其进行几种操作,分别是插入,删除,合并,查询,输出 主要学到了一些特别的操作. (1)备份( 本蒟蒻第一次了解到) (2)对与数据的一些特别的改 ...
- Python命令行参数及文件读出写入
看完了柯老板的个人编程作业,虽然是评测组不用做此次作业,但还是想对本次作业涉及到利用Python命令行参数以及进行文件读出写入操作做一个简单的总结.(个人编程作业还是想自己能敲一敲,毕竟我的码力还是小 ...
- 面向政务企业的开发者工具集-逐浪文本大师v0.1正式发布(含代码全部开源啦!)
这是一款基于.net 4.7环境开发的开发者工具. 一个实用的windows小工具集合,里面包含了多个常用的小软件.其中的批量修改文件名及文件内容功能,可以自定义修改规则,支持规则的导入与导出.不需要 ...