最清晰易懂的 Go WaitGroup 源码剖析
hi,大家好,我是haohongfan。
本篇主要介绍 WaitGroup 的一些特性,让我们从本质上去了解 WaitGroup。关于 WaitGroup 的基本用法这里就不做过多介绍了。相对于《这可能是最容易理解的 Go Mutex 源码剖析》来说,WaitGroup 就简单的太多了。
源码剖析
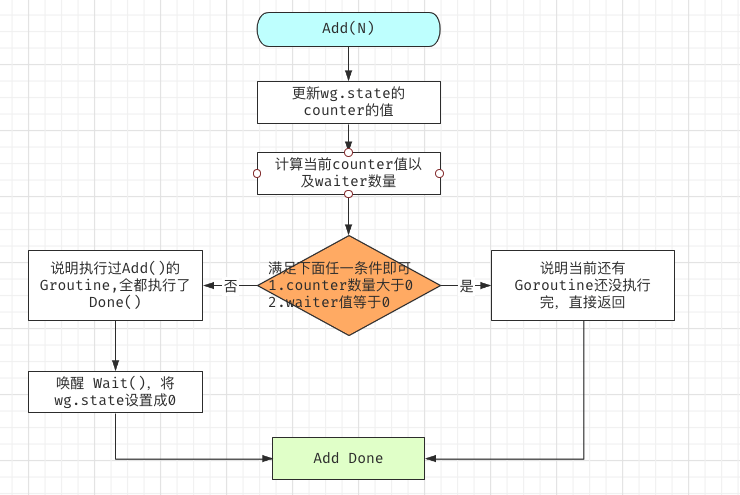
Add()
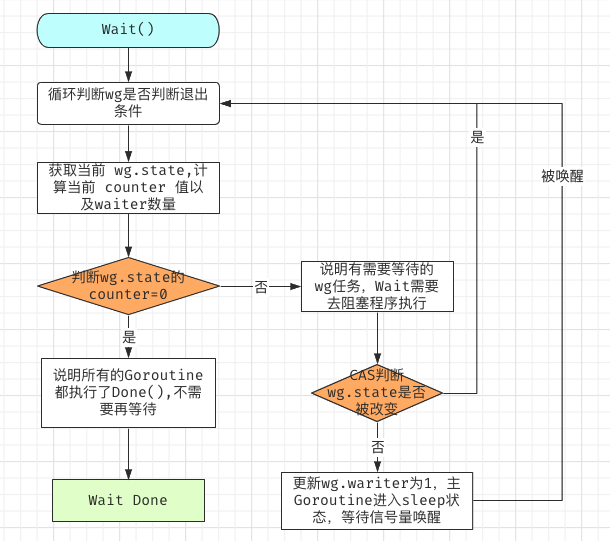
Wait()
type WaitGroup struct {
noCopy noCopy
state1 [3]uint32
}
WaitGroup 底层结构看起来简单,但 WaitGroup.state1 其实代表三个字段:counter,waiter,sema。
- counter :可以理解为一个计数器,计算经过 wg.Add(N), wg.Done() 后的值。
- waiter :当前等待 WaitGroup 任务结束的等待者数量。其实就是调用 wg.Wait() 的次数,所以通常这个值是 1 。
- sema : 信号量,用来唤醒 Wait() 函数。
为什么要将 counter 和 waiter 放在一起 ?
其实是为了保证 WaitGroup 状态的完整性。举个例子,看下面的一段源码
// sync/waitgroup.go:L79 --> Add()
if v > 0 || w == 0 { // v => counter, w => waiter
return
}
// ...
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
当同时发现 wg.counter <= 0 && wg.waiter != 0 时,才会去唤醒等待的 waiters,让等待的协程继续运行。但是使用 WaitGroup 的调用方一般都是并发操作,如果不同时获取的 counter 和 waiter 的话,就会造成获取到的 counter 和 waiter 可能不匹配,造成程序 deadlock 或者程序提前结束等待。
如何获取 counter 和 waiter ?
对于 wg.state 的状态变更,WaitGroup 的 Add(),Wait() 是使用 atomic 来做原子计算的(为了避免锁竞争)。但是由于 atomic 需要使用者保证其 64 位对齐,所以将 counter 和 waiter 都设置成 uint32,同时作为一个变量,即满足了 atomic 的要求,同时也保证了获取 waiter 和 counter 的状态完整性。但这也就导致了 32位,64位机器上获取 state 的方式并不相同。如下图:
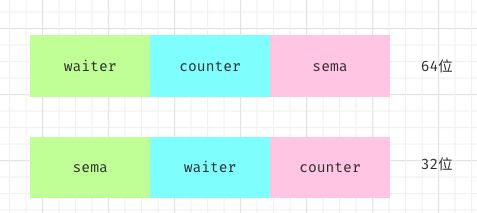
简单解释下:
因为 64 位机器上本身就能保证 64 位对齐,所以按照 64 位对齐来取数据,拿到 state1[0], state1[1] 本身就是64 位对齐的。但是 32 位机器上并不能保证 64 位对齐,因为 32 位机器是 4 字节对齐,如果也按照 64 位机器取 state[0],state[1] 就有可能会造成 atmoic 的使用错误。
于是 32 位机器上空出第一个 32 位,也就使后面 64 位天然满足 64 位对齐,第一个 32 位放入 sema 刚好合适。早期 WaitGroup 的实现 sema 是和 state1 分开的,也就造成了使用 WaitGroup 就会造成 4 个字节浪费,不过 go1.11 之后就是现在的结构了。
为什么流程图里缺少了 Done ?
其实并不是,是因为 Done 的实现就是 Add. 只不过我们常规用法 wg.Add(1) 是加 1 ,wg.Done() 是减 1,即 wg.Done() 可以用 wg.Add(-1) 来代替。 尽管我们知道 wg.Add 可以传递负数当 wg.Done 使用,但是还是别这么用。
退出waitgroup的条件
其实就一个条件, WaitGroup.counter 等于 0
日常开发中特殊需求
1. 控制超时/错误控制
虽说 WaitGroup 能够让主 Goroutine 等待子 Goroutine 退出,但是 WaitGroup 遇到一些特殊的需求,如:超时,错误控制,并不能很好的满足,需要做一些特殊的处理。
用户在电商平台中购买某个货物,为了计算用户能优惠的金额,需要去获取 A 系统(权益系统),B 系统(角色系统),C 系统(商品系统),D 系统(xx系统)。为了提高程序性能,可能会同时发起多个 Goroutine 去访问这些系统,必然会使用 WaitGroup 等待数据的返回,但是存在一些问题:
- 当某个系统发生错误,等待的 Goroutine 如何感知这些错误?
- 当某个系统响应过慢,等待的 Goroutine 如何控制访问超时?
这些问题都是直接使用 WaitGroup 没法处理的。如果直接使用 channel 配合 WaitGroup 来控制超时和错误返回的话,封装起来并不简单,而且还容易出错。我们可以采用 ErrGroup 来代替 WaitGroup。
有关 ErrGroup 的用法这里就不再阐述。golang.org/x/sync/errgroup
package main
import (
"context"
"fmt"
"golang.org/x/sync/errgroup"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), time.Second*5)
defer cancel()
errGroup, newCtx := errgroup.WithContext(ctx)
done := make(chan struct{})
go func() {
for i := 0; i < 10; i++ {
errGroup.Go(func() error {
time.Sleep(time.Second * 10)
return nil
})
}
if err := errGroup.Wait(); err != nil {
fmt.Printf("do err:%v\n", err)
return
}
done <- struct{}{}
}()
select {
case <-newCtx.Done():
fmt.Printf("err:%v ", newCtx.Err())
return
case <-done:
}
fmt.Println("success")
}
2. 控制 Goroutine 数量
场景模拟:
大概有 2000 - 3000 万个数据需要处理,根据对服务器的测试,当启动 200 个 Goroutine 处理时性能最佳。如何控制?
遇到诸如此类的问题时,单纯使用 WaitGroup 是不行的。既要保证所有的数据都能被处理,同时也要保证同时最多只有 200 个 Goroutine。这种问题需要 WaitGroup 配合 Channel 一块使用。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg = sync.WaitGroup{}
manyDataList := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
ch := make(chan bool, 3)
for _, v := range manyDataList {
wg.Add(1)
go func(data int) {
defer wg.Done()
ch <- true
fmt.Printf("go func: %d, time: %d\n", data, time.Now().Unix())
time.Sleep(time.Second)
<-ch
}(v)
}
wg.Wait()
}
使用注意点
使用 WaitGroup 同样不能被复制。具体例子就不再分析了。具体分析过程可以参见《这可能是最容易理解的 Go Mutex 源码剖析》
WaitGroup 的剖析到这里基本就结束了。有什么想跟我交流的,欢迎评论区留言。
欢迎关注我的公众号:HHFCodeRV,一起学习一起进步
最清晰易懂的 Go WaitGroup 源码剖析的更多相关文章
- 实践指路明灯,源码剖析flink-metrics
1. 通过上期的分享,我们对 Metrics 类库有了较深入的认识,并对指标监控的几个度量类型了如指掌. 本期,我们将走进当下最火的流式处理框架 flink 的源码,一同深入并学习一下别人家的代码. ...
- go中waitGroup源码解读
waitGroup源码刨铣 前言 WaitGroup实现 noCopy state1 Add Wait 总结 参考 waitGroup源码刨铣 前言 学习下waitGroup的实现 本文是在go ve ...
- 豌豆夹Redis解决方案Codis源码剖析:Proxy代理
豌豆夹Redis解决方案Codis源码剖析:Proxy代理 1.预备知识 1.1 Codis Codis就不详细说了,摘抄一下GitHub上的一些项目描述: Codis is a proxy base ...
- jQuery之Deferred源码剖析
一.前言 大约在夏季,我们谈过ES6的Promise(详见here),其实在ES6前jQuery早就有了Promise,也就是我们所知道的Deferred对象,宗旨当然也和ES6的Promise一样, ...
- Node 进阶:express 默认日志组件 morgan 从入门使用到源码剖析
本文摘录自个人总结<Nodejs学习笔记>,更多章节及更新,请访问 github主页地址.欢迎加群交流,群号 197339705. 章节概览 morgan是express默认的日志中间件, ...
- SpringMVC源码剖析(二)- DispatcherServlet的前世今生
上一篇文章<SpringMVC源码剖析(一)- 从抽象和接口说起>中,我介绍了一次典型的SpringMVC请求处理过程中,相继粉墨登场的各种核心类和接口.我刻意忽略了源码中的处理细节,只列 ...
- 玩转Android之Picasso使用详详详详详详解,从入门到源码剖析!!!!
Picasso是Squareup公司出的一款图片加载框架,能够解决我们在Android开发中加载图片时遇到的诸多问题,比如OOM,图片错位等,问题主要集中在加载图片列表时,因为单张图片加载谁都会写.如 ...
- 豌豆夹Redis解决方案Codis源码剖析:Dashboard
豌豆夹Redis解决方案Codis源码剖析:Dashboard 1.不只是Dashboard 虽然名字叫Dashboard,但它在Codis中的作用却不可小觑.它不仅仅是Dashboard管理页面,更 ...
- rest_framework之视图及源码剖析
最初形态(工作中可能会使用) 引子 Django的CBV我们应该都有所了解及使用,大体概括一下就是通过定义类并在类中定义get post put delete等对应于请求方法的方法,当请求来的时候会自 ...
随机推荐
- spring boot用ModelAndView向Thymeleaf模板传参数
最近在调试一个Spring Boot向Thymeleaf模板传参数的例子,但踩了很多坑,这里就把详细过程记录下来,以供大家参考. 先说下,这里遇到哪些坑呢? 1 我用的是IDEA社区版,这不支持JSP ...
- Warning: Cannot update during an existing state transition (such as within `render`). Render 报错
原来 修改(不用在构造函数里面定义)
- HashMap扩容后是否需要rehash?
需要,因为要重新计算旧数组元素在新数组地址.HashMap在JDK1.8中的rehash算法(也就是扩容后重新为里面的键值对寻址的算法)进行优化.hash寻址算法是 index =(n - 1) &a ...
- alpine jdk 中文乱码
一.概述 使用alpine镜像构建了一个oracle jdk的镜像,运行java业务时,查看日志,显示中文乱码. 但是,基于Alpine Linux的Docker基础镜像的镜像文件很小,也有代价: 把 ...
- C# ref and out
相同点: 1. ref 和 out 都是按地址传递的,使用后都将改变原来参数的数值: 2. 方法定义和调用方法都必须显式使用 ref 或者 out关键字: 3. 通过ref 和 ref 特性,一定程度 ...
- 【pytest官方文档】解读fixtures - 2. fixtures的调用方式
既然fixtures是给执行测试做准备工作的,那么pytest如何知道哪些测试函数 或者 fixtures要用到哪一个fixtures呢? 说白了,就是fixtures的调用. 一.测试函数声明传参请 ...
- Kubernetes - Kubelet TLS Bootstrapping
一.简单说明 写这个的初衷是自己搜索TLS Bootstrapping的时候没有搜到自己想要的东西,因为TLS Bootstrapping经过很多版本之后也发生了一些变化,所以网上很多也是老的内容了. ...
- Linux发行版及其目标用户
1.Debian Debian 众所周知,是Deepin,Ubuntu和Mint等流行Linux发行版的母亲,这些发行版提供了可靠的性能,稳定性和无与伦比的用户体验.最新的稳定发行版是Debian 1 ...
- 微服务架构Day16-SpringBoot之监控管理
监控管理使用步骤 通过引入spring-boot-starter-actuator,可以使用SpringBoot提供应用监控和管理的功能.可以通过HTTP,JMX,SSH协议来进行操作,自动得到审计, ...
- Kubernetes 实战 —— 03. pod: 运行于 Kubernetes 中的容器
介绍 pod P53 pod 是 Kubernetes 中最为重要的核心概念,而其他对象仅仅用于 pod 管理. pod 暴露或被 pod 使用. pod 是一组并置的容器,代表了 Kubernete ...